
 Technology peripherals
AI
Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!
Technology peripherals
AI
Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!
Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!

Recently, a netizen compiled a list of "Numbers that every LLM developer should know" and explained why these numbers are important and how we should use them.
When he was at Google, there was a document compiled by legendary engineer Jeff Dean called "Numbers Every Engineer Should Know."

Jeff Dean: "Numbers Every Engineer Should Know"
For LLM (Large Language Model) developers, it is also very useful to have a similar set of numbers for rough estimation.

Prompt
##40-90%: Add "concise" to the prompt The subsequent cost savings
#You must know that you pay according to the token used by LLM during output.
This means that you can save a lot of money by letting your model be concise.
At the same time, this concept can be expanded to more places.
For example, you originally wanted to use GPT-4 to generate 10 alternatives, but now you may be able to ask it to provide 5 first, and then you can keep the other half of the money.
1.3: The average number of tokens per word
LLM operates in token units.
And a token is a word or a subpart of a word. For example, "eating" may be decomposed into two tokens "eat" and "ing".
Generally speaking, 750 English words will generate about 1000 tokens.
For languages other than English, the number of tokens per word will be increased, depending on their commonality in LLM’s embedding corpus.

Considering that the cost of using LLM is very high, the numbers related to the price are has become particularly important.
~50: Cost ratio of GPT-4 and GPT-3.5 Turbo
Using GPT-3.5-Turbo About 50 times cheaper than GPT-4. I say "approximately" because GPT-4 charges differently for prompts and generation.
So in actual application, it is best to confirm whether GPT-3.5-Turbo is enough to meet your needs.
For example, for tasks like summarizing, GPT-3.5-Turbo is more than sufficient.


##5: Use GPT- 3.5-Turbo vs. OpenAI Embedding Cost Ratio for Text Generation
This means that looking up something in a vector storage system is much cheaper than using generation with LLM. Specifically, searching in the neural information retrieval system costs about 5 times less than asking GPT-3.5-Turbo. Compared with GPT-4, the cost gap is as high as 250 times! 10: Cost Ratio of OpenAI Embeds vs. Self-Hosted Embeds Note: This number is very sensitive to load and embedding batch sizes are very sensitive, so consider them as approximations. With g4dn.4xlarge (on-demand price: $1.20/hour) we can leverage SentenceTransformers with HuggingFace (comparable to OpenAI’s embeddings) at ~9000 per second The speed of token embedding. Doing some basic calculations at this speed and node type shows that self-hosted embeds can be 10x cheaper. 6: Cost ratio of OpenAI basic model and fine-tuned model query On OpenAI, the cost of fine-tuned model 6 times that of the base model. This also means that it is more cost-effective to adjust the base model's prompts than to fine-tune a custom model. 1: Cost ratio of self-hosting base model vs. fine-tuned model query If you host the model yourself, then The cost of the fine-tuned model is almost the same as that of the base model: the number of parameters is the same for both models. ~$1 million: the cost of training a 13 billion parameter model on 1.4 trillion tokens Paper address: https://arxiv.org/pdf/2302.13971.pdf ##LLaMa’s The paper mentioned that it took them 21 days and used 2048 A100 80GB GPUs to train the LLaMa model. Assuming we train our model on the Red Pajama training set, assuming everything works fine, without any crashes, and it succeeds the first time, we will get the above numbers. In addition, this process also involves coordination between 2048 GPUs. Most companies do not have the conditions to do this. However, the most critical message is: it is possible to train our own LLM, but the process is not cheap. And every time it is run, it takes several days. In comparison, using a pre-trained model will be much cheaper. < 0.001: Cost rate for fine-tuning and training from scratch For example, you can fine-tune a 6B parameter model for about $7. Training and fine-tuning
This means that if you want to fine-tune Shakespeare's entire work (about 1 million words), you only need to spend forty or fifty dollars.
However, fine-tuning is one thing, training from scratch is another...
GPU memory
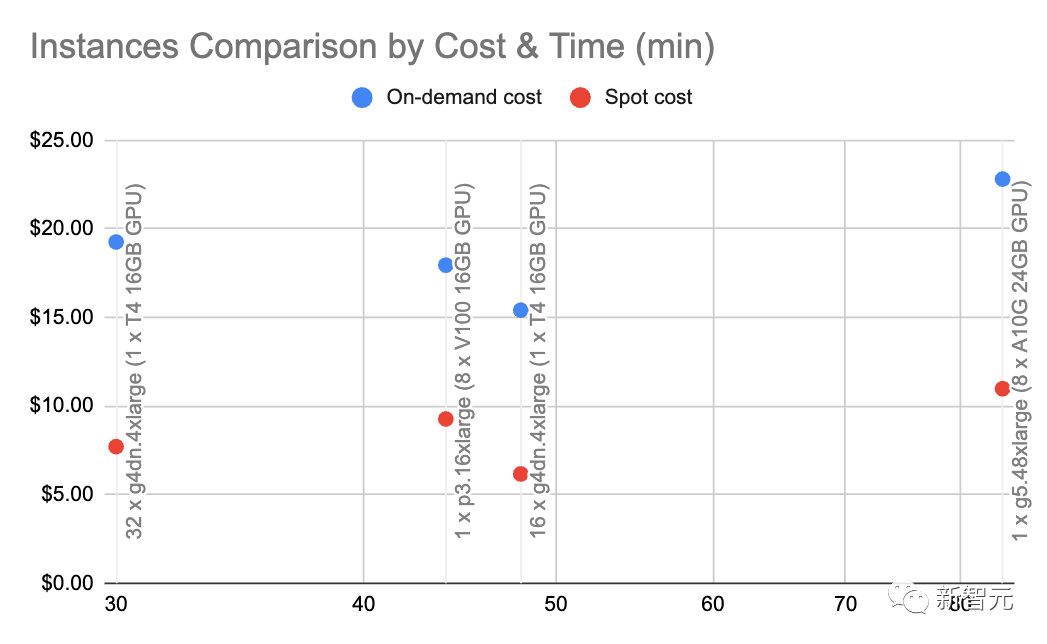
If you are self-hosting the model, it is very important to understand the GPU memory, because LLM is pushing the GPU memory to the limit.The following statistics are used specifically for inference. If you want to do training or fine-tuning, you need quite a bit of video memory. V100: 16GB, A10G: 24GB, A100: 40/80GB: GPU memory capacity Understand the different types The amount of video memory your GPU has is important as this will limit the amount of parameters your LLM can have. Generally speaking, we like to use A10G because they are priced at $1.5 to $2 per hour on AWS on demand and have 24G of GPU memory, while each A100 The price is approximately $5/hour. 2x Parameter amount: Typical GPU memory requirements of LLM For example, when you have a 7 billion Parametric model requires approximately 14GB of GPU memory. This is because in most cases each argument requires a 16-bit floating point number (or 2 bytes). Usually you don't need more than 16 bits of precision, but most of the time the resolution starts to decrease when the precision reaches 8 bits (and in some cases this is acceptable). Of course, there are some projects that have improved this situation. For example, llama.cpp ran through a 13 billion parameter model by quantizing to 4 bits on a 6GB GPU (8 bits are also acceptable), but this is not common. ~1GB: Typical GPU memory requirements for embedding models Whenever you embed statements (clustering, semantics (which is often done for search and classification tasks), you need an embedding model like a sentence converter. OpenAI also has its own commercial embedding model. 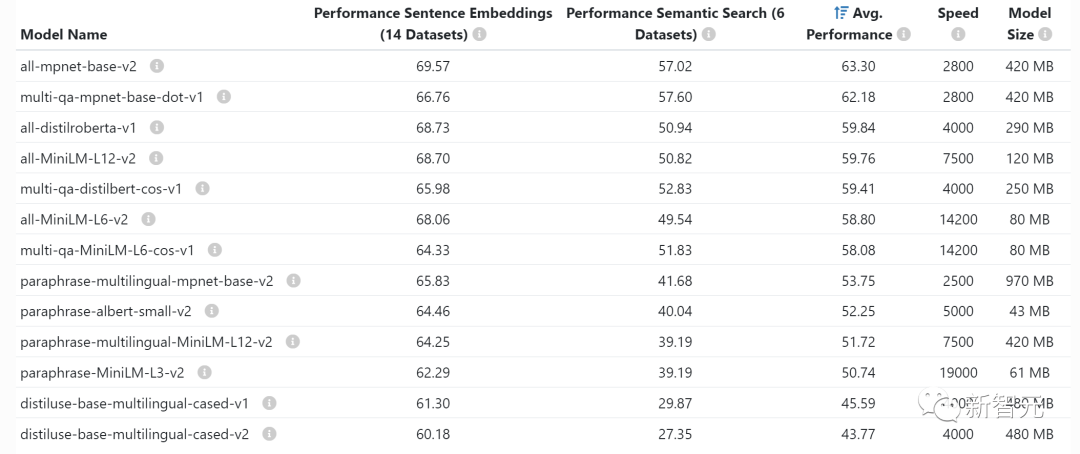
Usually you don’t have to worry about how much video memory embedding takes up on the GPU, they are quite small and you can even embed LLM on the same GPU .
>10x: Improve throughput by batching LLM requests
##Latency of running LLM queries through GPU Very high: At a throughput of 0.2 queries per second, the latency may be 5 seconds.
Interestingly, if you run two tasks, the delay may only be 5.2 seconds.
This means that if you can bundle 25 queries together, you will need about 10 seconds of latency, and the throughput has been increased to 2.5 queries per second.
However, please read on.
~1 MB: GPU memory required for the 13 billion parameter model to output 1 token
What you need The amount of video memory is directly proportional to the maximum number of tokens you want to generate.
For example, generating output of up to 512 tokens (approximately 380 words) requires 512MB of video memory.
You might say, this is no big deal - I have 24GB of video memory, what is 512MB? However, if you want to run larger batches, this number starts to add up.
For example, if you want to do 16 batches, the video memory will be directly increased to 8GB.
The above is the detailed content of Imitating Jeff Dean's divine summary, a former Google engineer shared 'LLM development secrets': numbers that every developer should know!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1381
1381
 52
52

 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 How to perform digital signature verification with Debian OpenSSL
Apr 13, 2025 am 11:09 AM
How to perform digital signature verification with Debian OpenSSL
Apr 13, 2025 am 11:09 AM
Using OpenSSL for digital signature verification on Debian systems, you can follow these steps: Preparation to install OpenSSL: Make sure your Debian system has OpenSSL installed. If not installed, you can use the following command to install it: sudoaptupdatesudoaptininstallopenssl to obtain the public key: digital signature verification requires the signer's public key. Typically, the public key will be provided in the form of a file, such as public_key.pe
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
 How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
Managing Hadoop logs on Debian, you can follow the following steps and best practices: Log Aggregation Enable log aggregation: Set yarn.log-aggregation-enable to true in the yarn-site.xml file to enable log aggregation. Configure log retention policy: Set yarn.log-aggregation.retain-seconds to define the retention time of the log, such as 172800 seconds (2 days). Specify log storage path: via yarn.n
 Sony confirms the possibility of using special GPUs on PS5 Pro to develop AI with AMD
Apr 13, 2025 pm 11:45 PM
Sony confirms the possibility of using special GPUs on PS5 Pro to develop AI with AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, chief architect of SonyInteractiveEntertainment (SIE, Sony Interactive Entertainment), has released more hardware details of next-generation host PlayStation5Pro (PS5Pro), including a performance upgraded AMDRDNA2.x architecture GPU, and a machine learning/artificial intelligence program code-named "Amethylst" with AMD. The focus of PS5Pro performance improvement is still on three pillars, including a more powerful GPU, advanced ray tracing and AI-powered PSSR super-resolution function. GPU adopts a customized AMDRDNA2 architecture, which Sony named RDNA2.x, and it has some RDNA3 architecture.
