

MySQL database read-write separation is one of the common methods to improve service quality. For technical solutions, there are many mature open source frameworks or solutions, such as: sharding-jdbc, AbstractRoutingDatasource in spring, MySQL-Router, etc., and ReplicationConnection in mysql-jdbc can also support it.
This article will not do too much analysis on the technical selection of read-write separation. It only explores the reasons for connection failure when using druid as a data source and combining it with ReplicationConnection for read-write separation, and finds a simple and effective solution. solution.
Due to historical reasons, certain services have connection failure exceptions. The key error reports are as follows:

It can be inferred from the logs This is because the connection has not interacted with the MySQL server for a long time, causing the server to close the connection, which is a typical connection failure situation.
jdbc configuration
##jdbc:mysql:replication://master_host:port,slave_host:port/database_name
druid configuration
testWhileIdle=true (i.e., idle connection check is enabled); timeBetweenEvictionRunsMillis=6000L (i.e. , for the scenario of obtaining a connection, if a connection is idle for more than 1 minute, it will be checked. If the connection is invalid, it will be discarded and reacquired). Attachment: Theprocessing logic in DruidDataSource.getConnectionDirect is as follows:
if (testWhileIdle) {
final DruidConnectionHolder holder = poolableConnection.holder;
long currentTimeMillis = System.currentTimeMillis();
long lastActiveTimeMillis = holder.lastActiveTimeMillis;
long lastExecTimeMillis = holder.lastExecTimeMillis;
long lastKeepTimeMillis = holder.lastKeepTimeMillis;
if (checkExecuteTime
&& lastExecTimeMillis != lastActiveTimeMillis) {
lastActiveTimeMillis = lastExecTimeMillis;
}
if (lastKeepTimeMillis > lastActiveTimeMillis) {
lastActiveTimeMillis = lastKeepTimeMillis;
}
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}
}mysql timeout parameter configuration wait_timeout=3600 (3600 seconds, that is : If a connection has not interacted with the server for more than an hour, the connection will be killed by the server). Obviously, based on the above configuration, according to conventional understanding, the problem "The last packet successfully received from server was xxx,xxx,xxx milliseconds ago" should not occur. (Of course, the possibility of manual intervention to kill the database connection was also ruled out at that time). When the "supposed" experience cannot explain the problem, it is often necessary to jump out of the shackles of superficial experience and get to the bottom of it. So, what is the real cause of this problem?

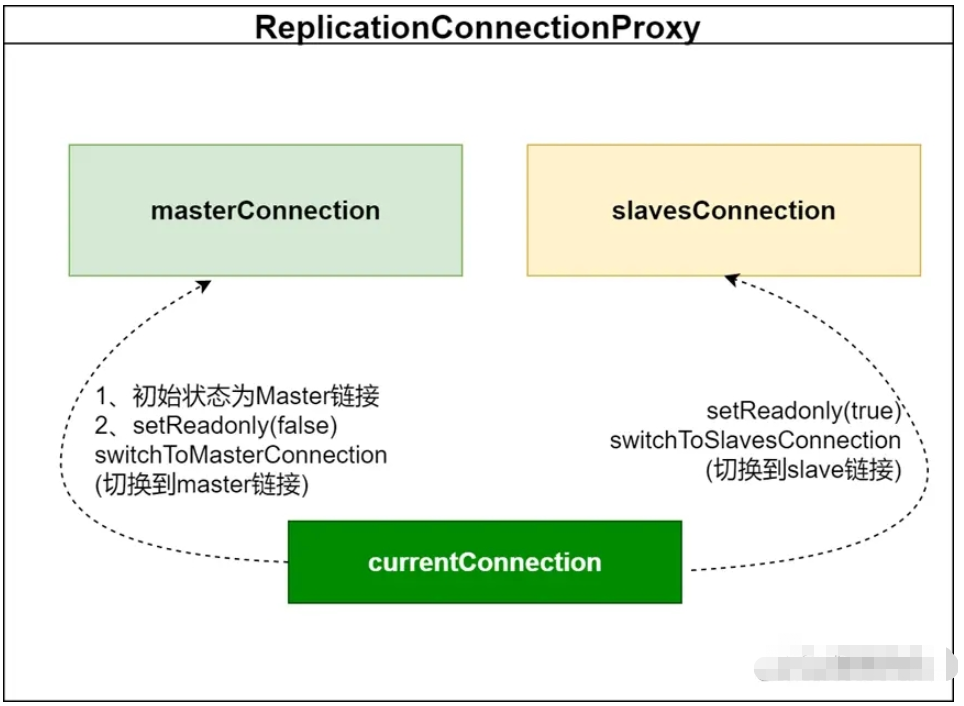
public static ReplicationConnection createProxyInstance(List<String> masterHostList, Properties masterProperties, List<String> slaveHostList,
Properties slaveProperties) throws SQLException {
ReplicationConnectionProxy connProxy = new ReplicationConnectionProxy(masterHostList, masterProperties, slaveHostList, slaveProperties);
return (ReplicationConnection) java.lang.reflect.Proxy.newProxyInstance(ReplicationConnection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
}
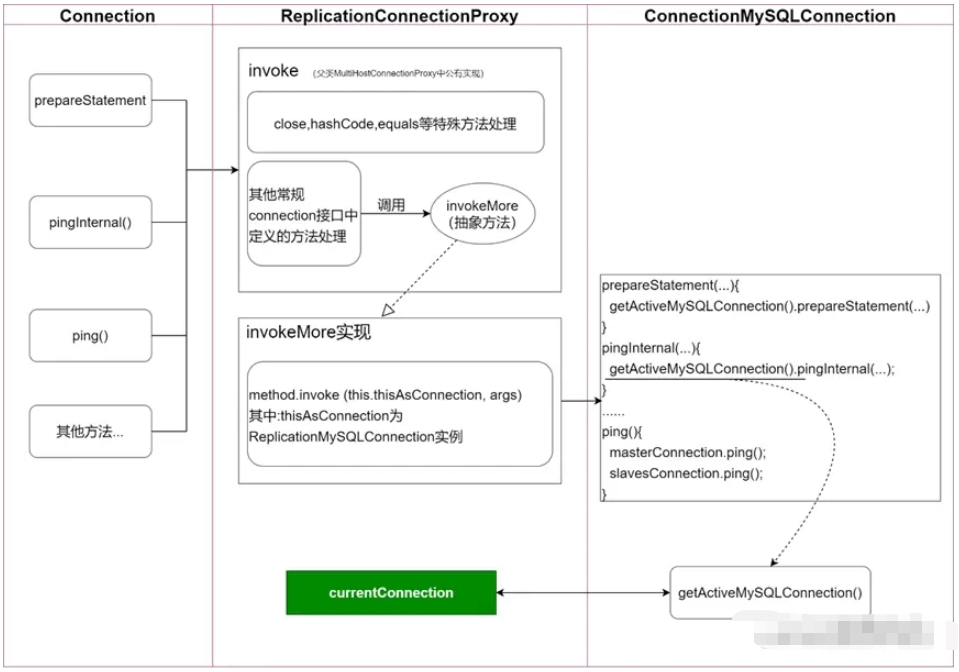
对于prepareStatement等常规逻辑,ConnectionMySQConnection获取到当前连接进行处理(普通的读写分离的处理的重点正是在此);此时,重点提及pingInternal方法,其处理方式也是获取当前连接,然后执行pingInternal逻辑。
对于ping()这个特殊逻辑,图中描述相对简单,但主体含义不变,即:对master连接和sleves连接都要进行ping()的处理。
图中,pingInternal流程和druid的MySQ连接检查有关,而ping的特殊处理,也正是解决问题的关键。
druid中对MySQL连接检查的默认实现类是MySqlValidConnectionChecker,其中核心逻辑如下:
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (usePingMethod) {
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (clazz.isAssignableFrom(conn.getClass())) {
if (validationQueryTimeout <= 0) {
validationQueryTimeout = DEFAULT_VALIDATION_QUERY_TIMEOUT;
}
try {
ping.invoke(conn, true, validationQueryTimeout * 1000);
} catch (InvocationTargetException e) {
Throwable cause = e.getCause();
if (cause instanceof SQLException) {
throw (SQLException) cause;
}
throw e;
}
return true;
}
}
String query = validateQuery;
if (validateQuery == null || validateQuery.isEmpty()) {
query = DEFAULT_VALIDATION_QUERY;
}
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
if (validationQueryTimeout > 0) {
stmt.setQueryTimeout(validationQueryTimeout);
}
rs = stmt.executeQuery(query);
return true;
} finally {
JdbcUtils.close(rs);
JdbcUtils.close(stmt);
}
}对应服务中使用的mysql-jdbc(5.1.45版),在未设置“druid.mysql.usePingMethod”系统属性的情况下,默认usePingMethod为true,如下:
public MySqlValidConnectionChecker(){
try {
clazz = Utils.loadClass("com.mysql.jdbc.MySQLConnection");
if (clazz == null) {
clazz = Utils.loadClass("com.mysql.cj.jdbc.ConnectionImpl");
}
if (clazz != null) {
ping = clazz.getMethod("pingInternal", boolean.class, int.class);
}
if (ping != null) {
usePingMethod = true;
}
} catch (Exception e) {
LOG.warn("Cannot resolve com.mysql.jdbc.Connection.ping method. Will use 'SELECT 1' instead.", e);
}
configFromProperties(System.getProperties());
}
@Override
public void configFromProperties(Properties properties) {
String property = properties.getProperty("druid.mysql.usePingMethod");
if ("true".equals(property)) {
setUsePingMethod(true);
} else if ("false".equals(property)) {
setUsePingMethod(false);
}
}同时,可以看出MySqlValidConnectionChecker中的ping方法使用的是MySQLConnection中的pingInternal方法,而该方法,结合上面对ReplicationConnection的分析,当调用pingInternal时,只是对当前连接进行检验。执行检验连接的时机是通过DrduiDatasource获取连接时,此时未设置readOnly属性,检查的连接,其实只是ReplicationConnectionProxy中的master连接。
此外,如果通过“druid.mysql.usePingMethod”属性设置usePingMeghod为false,其实也会导致连接失效的问题,因为:当通过valideQuery(例如“select 1”)进行连接校验时,会走到ReplicationConnection中的普通查询逻辑,此时对应的连接依然是master连接。
题外一问:ping方法为什么使用“pingInternal”,而不是常规的ping?
原因:pingInternal预留了超时时间等控制参数。
在服务中,使用的MySQL JDBC版本是5.1.45,并且使用的Druid版本是1.1.20。经过对其他高版本依赖的了解,依然存在该问题。
修改的工作量主要在于数据源配置和aop调整,但需要一定的整体回归验证成本,鉴于涉及该问题的服务重要性一般,暂不做大调整。
基于原有ReplicationConnection的功能,拓展pingInternal调整为普通的ping,集成原有Driver拓展新的Driver。方案可行,但修改成本不算小。
为简单高效解决问题,选择拓展MySqlValidConnectionChecker,并在druid数据源中加上对应配置即可。拓展如下:
public class MySqlReplicationCompatibleValidConnectionChecker extends MySqlValidConnectionChecker {
private static final Log LOG = LogFactory.getLog(MySqlValidConnectionChecker.class);
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (conn instanceof ReplicationConnection) {
try {
((ReplicationConnection) conn).ping();
LOG.info("validate connection success: connection=" + conn.toString());
return true;
} catch (SQLException e) {
LOG.error("validate connection error: connection=" + conn.toString(), e);
throw e;
}
}
return super.isValidConnection(conn, validateQuery, validationQueryTimeout);
}
}ReplicatoinConnection.ping()的实现逻辑中,会对所有master和slaves连接进行ping操作,最终每个ping操作都会调用到LoadBalancedConnectionProxy.doPing进行处理,而此处,可在数据库配置url中设置loadBalancePingTimeout属性设置超时时间。
The above is the detailed content of How to solve the problem of connection failure caused by MySQL using ReplicationConnection. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



