

COUNT(expression): Returns the total number of queried records. The expression parameter is a field or * sign.
MySQL version: 5.7.29
Create a user table and insert one million pieces of data, of which half a million rows in the gender field are null Value of
CREATE TABLE `users` ( `Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(32) DEFAULT NULL COMMENT '名称', `gender` varchar(20) DEFAULT NULL COMMENT '性别', `create_date` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`Id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
Prior to MySQL 5.7.18, InnoDB processed statements by scanning the clustered index. SELECT COUNT(*) Starting in MySQL 5.7.18, InnoDB handles SELECT COUNT(*) statements by traversing the smallest available secondary index, unless the index or optimizer hint instructs the optimizer to use a different index. If the secondary index does not exist, the clustered index is scanned.
The general meaning is that if there is a secondary index, use the secondary index. If there are multiple secondary indexes, the smallest secondary index will be preferred to reduce costs. If there is no secondary index, use the clustered index.
The following tests are used to verify these views.
First of all, query the execution plan when there is only the primary key index of Id.

You can see that the type is index, which means that the index is used. The key is PRIMARY, which means the primary key index is used, key_len=8.
Next, add an index to the name field, and use the execution plan again to view

You can see that the index is also used, but the index uses name The index of the field, key_len=99.
Then add an index to the create_date field while retaining the name field index, and check the execution plan again

#You can see that this time the The create_date field is indexed, key_len=6.
No matter which index is used above, the total number of rows finally queried is one million, regardless of whether they contain NULL values.
count(1) has the same query results as count(*), and ultimately returns one million pieces of data, regardless of whether they contain NULL values.
count(col) counts the value of a certain column, which is divided into three situations:
The query results are the same as count(*), and ultimately one million pieces of data are returned.
Use count(name) For query, the execution plan is as follows:

You can see that the index field is used for statistics, and the index is also hit.
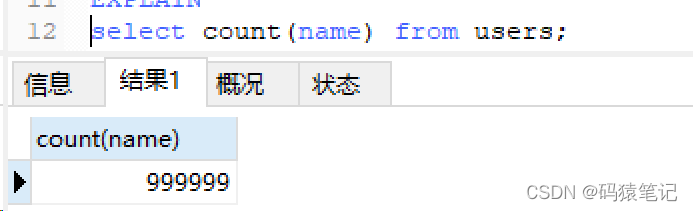
Set the name field in a column to NULL, and then perform a count query. The result returns 999999
Then set the NULL value of this column to an empty string, and then Perform a count query, and the result returns 1000000
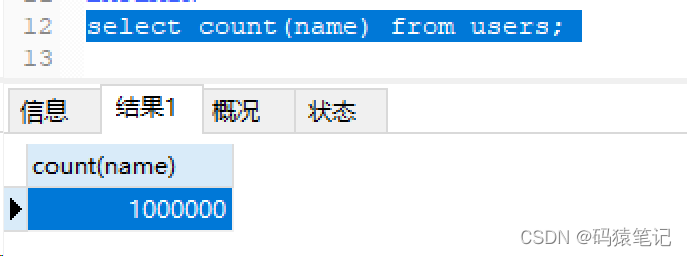
. Therefore, in summary, simply using the index field to count the number of rows can hit the index, and only count the number of rows that are not NULL values.
If you count fields without indexes, the index will not be used, and only the number of rows that are not NULL values will be counted.

I don’t know where I saw or heard about it before, count(1) is better than count(*) count(*) is highly efficient, which is a wrong perception. There is a saying on the official website, InnoDB handles SELECT COUNT( *) and SELECT COUNT(1) operations in the same way. There is no performance difference.
Translation The bottom line is that InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way, with no performance difference.
For MyISAM tables, COUNT(*) is optimized to return very quickly if retrieving from one table, no other columns are retrieved and there is no clause. This optimization only applies to MyISAM tables because for this The storage engine stores the exact number of rows and can be accessed very quickly. COUNT(1) does the same optimization only if the first column is defined as NOT NULL. ----From MySQL official website
These optimizations are based on the premise that there is no where and group by.
It is also mentioned in the Alibaba development specifications

So if you can use count(*) during development, just use count(*).
The above is the detailed content of What is the difference between count(*), count(1), and count(col) in MySQL?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



