

Indices can be divided into B-Tree indexes and hash indexes according to the underlying implementation. Most of the time we use B-Tree indexes. -Tree index, because of its good performance and features, is more suitable for building high-concurrency systems.
Divided according to the storage method of the index, the index can be divided into clustered index and non-clustered index. The leaf nodes of a non-clustered index only contain all fields and primary key IDs, while the leaf nodes of a clustered index contain complete record rows.
According to clustered index and non-clustered index, it can be further divided into ordinary index, covering index, unique index and joint index.
Clustered index is also called clustered index. It is not actually a separate index type, but a data storage method. The leaf nodes of the clustered index store all column information of a row of records. In other words, the leaf node of the clustered index contains a complete record row.
Non-clustered index is also called auxiliary index and ordinary index. Its leaf nodes only contain one primary key value. To find records through non-clustered index, you must first find the primary key, and then go to the clustered index through the primary key. Find the corresponding record row, this process is called table return.
For example, a data table containing user names and ages, assuming that the primary key is the user ID, the structure of the clustered index is (orange represents the id, green is the pointer to the child node):
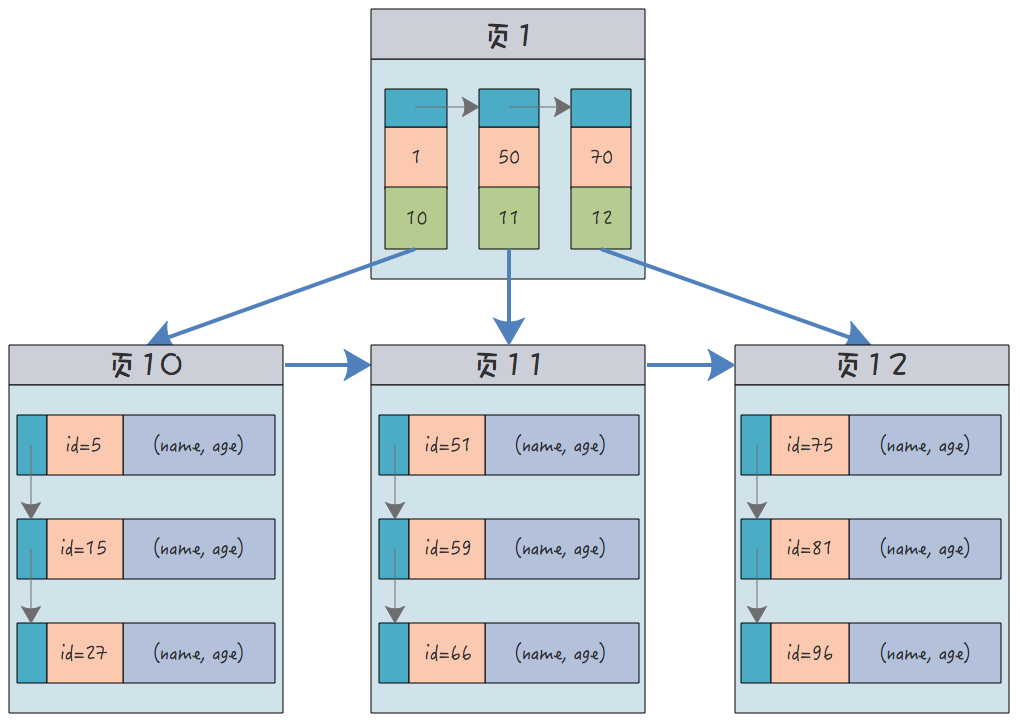
In the leaf nodes, in order to highlight the records, (id, name, age) is distinguished. In fact, they are connected together. They form a line. The record as a whole.
The structure of a non-clustered index (with age as the index) is:
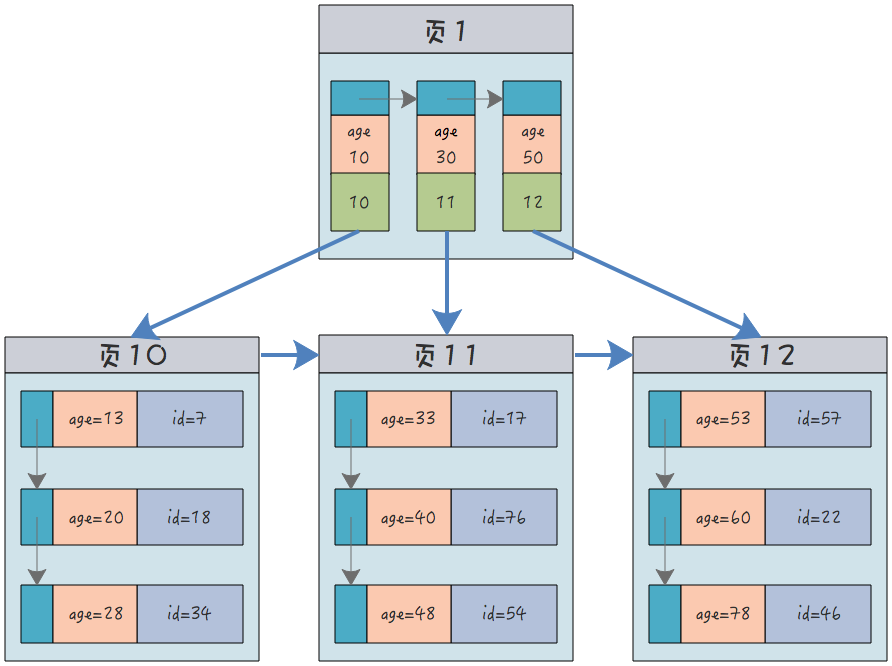
In addition to the age field itself, the leaf nodes of the node , only contains the primary key ID of the current record, and does not contain the information of the complete record. You need to query the clustered index through the ID number to obtain the entire row of record data.
In InnoDB, each table must have a clustered index, which will be created based on the primary key by default. If there is no primary key in the table, InnoDB will select a suitable column as the clustered index. If no suitable column is found, a hidden column DB_ROW_ID will be used as the clustered index.
Because the non-clustered index does not contain complete data information, searching for complete data records requires table return, so one query operation actually requires two index queries. . If every index query needs to be run twice to get the result, then this will inevitably lead to a loss of efficiency, because if you can reduce the query by one, you should reduce it by one.
Take the age index above as an example. It is a non-clustered index. If I want to query the user's ID by age, I execute the following statement:
1 |
select id from userinfo where age = 10; |
Is it still necessary to return the table in this case? Because I only need the value of the id, I can already get the id through the age index. If I still go back to the table once, wouldn't it be a useless operation? In fact it is not needed. When the auxiliary index already contains all the information required for the query, the table return operation can be avoided in the index query. This is a covering index.
Joint index refers to an index created on multiple columns at the same time. After creating a joint index, the leaf node will contain the value of each index column at the same time, and it will be based on multiple columns at the same time. Column sorting, this sorting is similar to what we understand as dictionary order.
For example, the index structure created for the above names and ages at the same time:
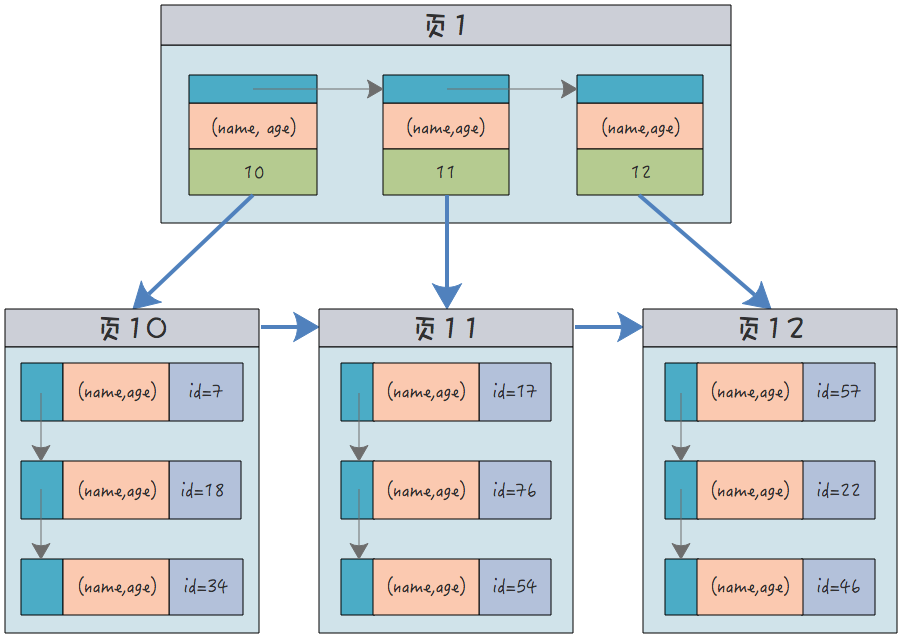
(name, age)Both It's an abbreviation, and I can't think of a dozen names.
Each leaf node saves all index columns at the same time. In addition, it still only contains the primary key id.
When an index is created for multiple columns, the index cannot be used as long as it contains the columns for which the index was created. The use of the index must follow the leftmost prefix matching principle.
Assuming that an index is created for column (A, B, C), then only the following scenarios can use the index:
The above is the detailed content of What are clustered indexes, non-clustered indexes, joint indexes and unique indexes in MySQL. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



