

Understanding the persistence process of MySQL data can help us deepen our understanding of the underlying MySQL. In this article, we will sort out this process in a popular way. Help everyone establish a preliminary understanding. If you are interested, you can study and research this process in depth.
The storage of MySQL data can generally be divided into two parts, the stored procedure in the memory and the persistent storage on the hard disk. Here, it involves the buffer poll and redo in the memory. log and the transaction log and table structure on the disk. In this article, we do not explain the specific design of each part in detail, but just give you a conceptual understanding:
buffer poll is part of the InnoDB engine cache pool. We can simply understand it here as the cache of memory blocks that the database reads from disk into memory;
redo log is a logical log in memory, recording transaction change operations
Transaction log is a disk Food logical log on
Table structure is the structure that actually stores data
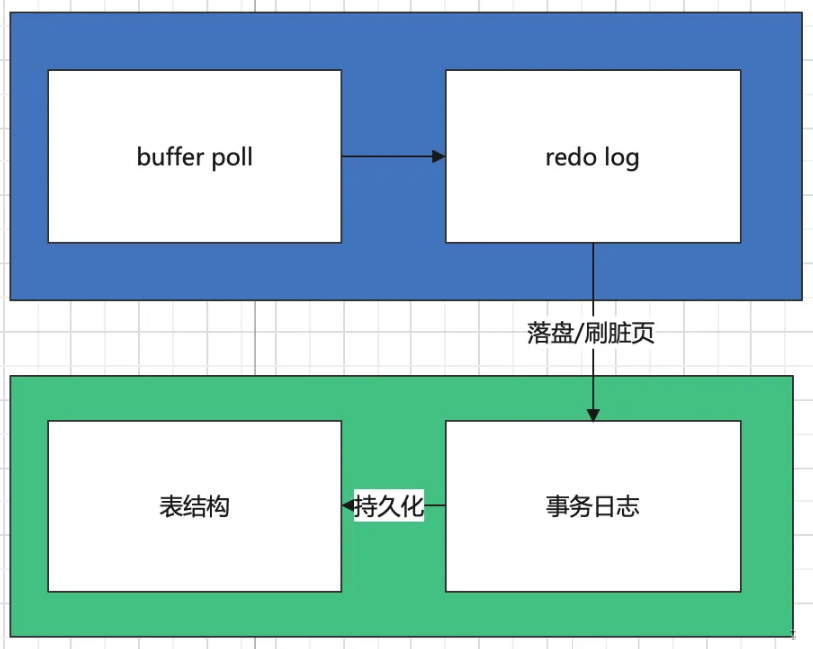
buffer poll has a cache for the data read into the memory. When the query command is executed, it will first check whether there is a hit in the cache. If there is a miss, The required data will be read from the disk. The cache management uses an improved LRU algorithm, which will not be introduced in depth here.
When a modification instruction is run, the first thing to do is to modify the cache in buffer poll. The modified data will be marked as dirty page, At the same time, the modified operations will also be recorded in redo log. The version chain in MVCC that we often say is implemented with the help of redo log.
It should be noted that dirty pages are not dropped to the disk immediately, but there is a flush control mechanism that can be set. For example, a transaction is dropped to the disk immediately after settlement, regularly dropped to the disk according to a certain time, etc. .
The operations in memory are non-persistent. If an unexpected problem occurs and the system crashes, the data has not been persisted, so in theory, it will not cause damage to the database. sexual influence.
InnoDB’s persistence on disk is divided into two steps. The first step is the storage of logical logs, and then Then flush the data in the log into disk space.
Before discussing why we should use logical logs, we need to briefly understand the difference between random IO and sequential IO:
The addressing process is an important bottleneck in disk IO because it requires moving the probe to the location where it needs to be read to read disk data.
Sequential IO means that the addressed space is continuous and the moving distance is very short. Random IO means that the addresses we need to find are distributed everywhere. Move long distances.
So, we can clearly draw the conclusion: replacing random IO with sequential IO can effectively improve the efficiency of disk IO, and the role of logical logs is correct. In this case, because the log files are continuous on the disk, the IO efficiency can be much higher compared to data table information distributed everywhere.
As long as we completely update the operation in the transaction log, then the transaction has been successfully persisted, and a dedicated thread will store the log information into the table structure.
The process of storing log information into the table structure is divided into two steps. First, the data will be updated in the cache area of the table header. After completion, it will be refreshed in the corresponding table structure.
The purpose of two-step storage is to ensure strong consistency of data storage and prevent data from being incomplete due to database downtime during the process of flashing to disk.
The cache area of the table header and the storage block of the table structure have check codes to verify the integrity of the data. If the former is complete and the latter is incomplete, directly re-flash the former data in the latter. It can be solved. If the former is incomplete, it means that the process of flushing from the log failed, just flush again.
The above is the detailed content of MySQL data persistence process example analysis. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



