

What is the underlying principle of redis

Redis core object
There is a "core object" in RedisIt is called redisObject, which is used to represent all keys and values. The redisObject structure is used to represent String, Five data types: Hash, List, Set, and ZSet.
The source code of redisObject is in redis.h, written in c language. If you are interested, you can check it out by yourself. I have drawn a picture about redisObject here, which shows that the structure of redisObject is as follows:
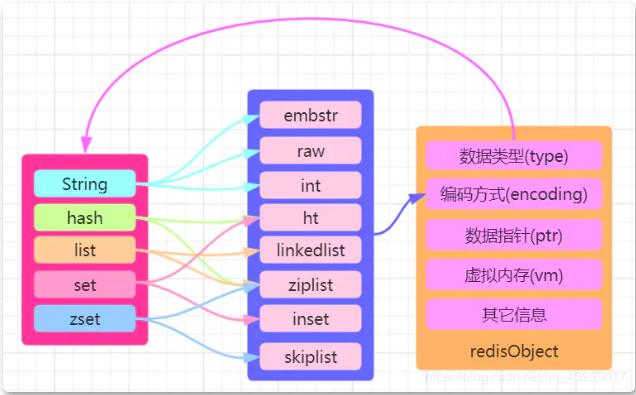
In redisObject"type indicates which data type it belongs to, and encoding indicates the storage method of the data", which is the underlying implementation of the data type. structure. Therefore, this article specifically introduces the corresponding part of encoding.
So what do the storage types in encoding mean? The meaning represented by the specific data type is as shown in the following figure:
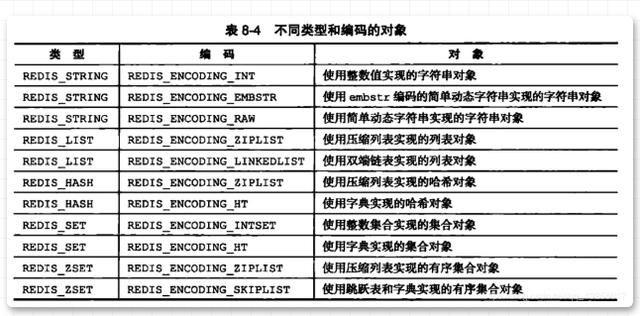
#You may still feel confused after reading this picture. Don’t panic, we will give a detailed introduction to the five data structures. This picture only allows you to find the storage types corresponding to each data structure, and probably have an impression in your mind.
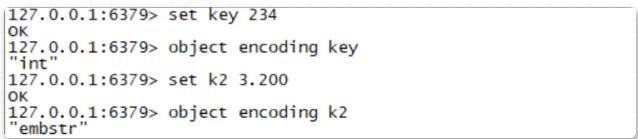
To give a simple example, if you set a string key 234 in Redis, and then check the storage type of this string, you will see that it is int type. Non-integer types use the embstr storage type. The specific operation is shown in the figure below:
String type
String is the most basic data type of Redis. The above introduction also mentioned that Redis uses c language developed. However, there are obvious differences between string types in Redis and string types in C language.
There are three ways to store data structure of type String: int, raw, and embstr.. So what are the differences between these three storage methods?
int
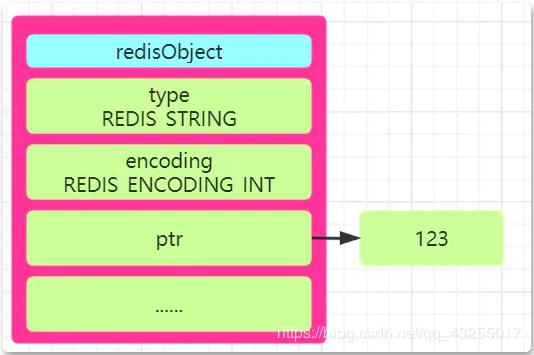
Redis stipulates that if what is stored is "integer value", such as set num 123, it will be stored using the int storage method. This value will be saved in the "ptr attribute" of redisObject.
SDS
If the stored "string is a string value and the length is greater than 32 bytes" will be used Store in SDS (simple dynamic string) mode, and the encoding is set to raw; if "The string length is less than or equal to 32 bytes", the encoding will be changed to embstr to save the string.
SDS is called "Simple Dynamic String". There are three attributes defined in SDS in the Redis source code: int len, int free, and char buf[].
len saves the length of the string, free represents the number of unused bytes in the buf array, and the buf array stores each character element of the string.
So when you store a string Hello in Redsi, according to the description of the Redis source code, you can draw the redisObject structure diagram in the form of SDS as shown below:
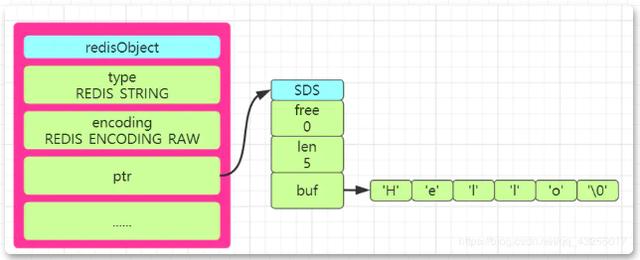
Comparison between SDS and c language strings
Redis definitely has its own advantages in using SDS as the type of string storage. Compared with SDS strings in c language, SDS has The string has its own design and optimization. The specific advantages are as follows:
(1) The string in the C language does not record its own length, so "get the string every time The length of will be traversed, and the time complexity is O(n)". To obtain a string in Redis, you only need to read the value of len, and the time complexity becomes O(1).
(2)"c language" In the concatenation of two strings, if sufficient length of memory space is not allocated, "buffer overflow will occur" ; And 『SDS』 will first determine whether the space meets the requirements based on the len attribute. If the space is not enough, the corresponding space will be expanded, so "there will be no buffer overflow" .
(3) SDS also provides "space pre-allocation" and "lazy space release" two strategies. When allocating space for a string, allocate more space than actual, so that "reduce the number of memory reallocations caused by continuous execution of string growth".
When the string is shortened, SDS will not immediately reclaim the unused space. Instead, it will record the unused space through the free attribute and release it when it is used later.
The specific space pre-allocation principle is: "When the length len of the modified string is less than 1MB, space with the same length as len will be pre-allocated, that is, len=free; if len is greater than 1MB, The space allocated by free is 1MB".
(4) SDS is binary safe. In addition to storing strings, it can also store binary files (such as binary data of pictures, audios, videos, etc.); while strings in C language use empty strings as Terminators. Some images contain terminators and are therefore not binary safe.
In order to make it easier to understand, we have made a table comparing C language strings and SDS, as shown below:
C language strings SDS The time complexity of getting the length is O(n) The time complexity of getting the length is O(1) It is not binary safe but binary safe can only save strings and can also save binary data. When the string grows n times, the string will inevitably grow. Bringing n times of memory allocation n times increasing the number of string memory allocations
String type application
Speaking of this, I believe many people can say that they are already proficient in the String type of Redis , but to master pure theory, theory still needs to be applied in practice. As mentioned above, String can be used to store pictures. Now we will use picture storage as a case study.
(1) First of all, the uploaded image must be encoded. Here is a tool class to process the image into Base64 encoding. The specific implementation code is as follows:
/** * 将图片内容处理成Base64编码格式 * @param file * @return */ public static String encodeImg(MultipartFile file) { byte[] imgBytes = null; try { imgBytes = file.getBytes(); } catch (IOException e) { e.printStackTrace(); } BASE64Encoder encoder = new BASE64Encoder(); return imgBytes==null?null:encoder.encode(imgBytes );Copy code
(2) The second step is to store the processed image string format into Redis. The implemented code is as follows:
/** * Redis存储图片 * @param file * @return */ public void uploadImageServiceImpl(MultipartFile image) { String imgId = UUID.randomUUID().toString(); String imgStr= ImageUtils.encodeImg(image); redisUtils.set(imgId , imgStr); // 后续操作可以把imgId存进数据库对应的字段,如果需要从redis中取出,只要获取到这个字段后从redis中取出即可。 }This is how the image is implemented Binary storage, of course, the application of String type data structure also has conventional counting: "Statistics on the number of Weibo, statistics on the number of fans", etc.
Hash type
There are two ways to implement Hash objects: ziplist and hashtable. The storage method of hashtable is of type String, and the value is also stored in the form of key value.
The bottom layer of the dictionary type is implemented by hashtable. Understanding the bottom layer implementation principle of dictionary means understanding the implementation principle of hashtable. The implementation principle of hashtable can be compared to the bottom layer principle of HashMap.
Dictionary
Both will calculate the array subscript through the key when adding it. The difference is that the calculation method is different. HashMap uses the hash function, while hashtable calculates the array subscript. After the hash value, the array subscript must be obtained again through the sizemask attribute and the hash value.
We know that the biggest problem with hash tables is hash conflicts. In order to solve hash conflicts, if different keys in the hashtable obtain the same index through calculation, a one-way linked list will be formed ("Chain Address Method" ), as shown in the figure below:
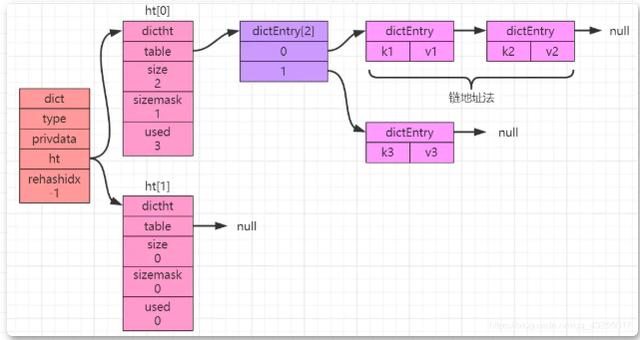
rehash
In the underlying implementation of the dictionary, the value object is stored as an object of each dictEntry, When the key-value pairs stored in the hash table continue to increase or decrease, the hash table needs to be expanded or contracted.
Just like HashMap, rehash operation will also be performed here, that is, rehash arrangement. As can be seen from the above figure, ht[0] and ht[1] are two objects. Below we will focus on the role of their attributes.
There are four attributes in the hash table structure definition: dictEntry **table, unsigned long size, unsigned long sizemask, and unsigned long used, which respectively mean "hash table array, hash The table size, used to calculate the index value, is always equal to size-1, the number of nodes already in the hash table".
ht[0] is used to initially store data. When expansion or contraction is required, the size of ht[0] determines the size of ht[1]. All the data in ht[0] The key-value pairs will be rehashed into ht[1].
Expansion operation: The expanded size of ht[1] is the first integer power of 2 that is twice the current value of ht[0].used; Shrinking operation: The first integer power of ht[0].used An integer power of 2 greater than or equal to 2.
When all key-value pairs on ht[0] are rehashed to ht[1], all array subscript values will be recalculated, and ht[0] will be released after the data migration is completed. , then change ht[1] to ht[0], and create a new ht[1] to prepare for the next expansion and contraction.
Progressive rehash
If the amount of data is very large during the rehash process, Redis does not successfully rehash all the data at once, which will cause Redis's external service to stop. In order to handle this situation internally, Redis The situation uses "Progressive rehash".
Redis divides all rehash operations into multiple steps until all rehash operations are completed. The specific implementation is related to the rehashindex attribute in the object. "If rehashindex is expressed as -1, it means there is no rehash operation".
When the rehash operation starts, the value will be changed to 0. During the progressive rehash process "Updates, deletions, and queries will be performed in both ht[0] and ht[1]", for example, when updating a value, first update ht[0], and then update ht[1].
The new operation is directly added to the ht[1] table, and ht[0] will not add any data. This ensures that "ht[0] only decreases but does not increase, until At a certain moment in the end, it becomes an empty table", and the rehash operation is completed.
The above is the implementation principle of the underlying hashtable of the dictionary. After talking about the implementation principle of hashtable, let's take a look at the two storage methods of Hash data structure"ziplist (compressed list)"
ziplist
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。
压缩列表是列表键和哈希键底层实现的原理之一,「压缩列表并不是以某种压缩算法进行压缩存储数据,而是它表示一组连续的内存空间的使用,节省空间」,压缩列表的内存结构图如下:

压缩列表中每一个节点表示的含义如下所示:
zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。
zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。
zllen:2个字节的大小,记录压缩列表中的节点数。
entry:表示列表中的每一个节点。
zlend:表示压缩列表的特殊结束符号'0xFF'。
再压缩列表中每一个entry节点又有三部分组成,包括previous_entry_ength、encoding、content。
previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的其实地址,因为他们的地址是连续的。
encoding:这里保存的是content的内容类型和长度。
content:content保存的是每一个节点的内容。

说到这里相信大家已经都hash这种数据结构已经非常了解,若是第一次接触Redis五种基本数据结构的底层实现的话,建议多看几遍,下面来说一说hash的应用场景。
应用场景
哈希表相对于String类型存储信息更加直观,擦欧总更加方便,经常会用来做用户数据的管理,存储用户的信息。
hash也可以用作高并发场景下使用Redis生成唯一的id。下面我们就以这两种场景用作案例编码实现。
存储用户数据
第一个场景比如我们要储存用户信息,一般使用用户的ID作为key值,保持唯一性,用户的其他信息(地址、年龄、生日、电话号码等)作为value值存储。
若是传统的实现就是将用户的信息封装成为一个对象,通过序列化存储数据,当需要获取用户信息的时候,就会通过反序列化得到用户信息。
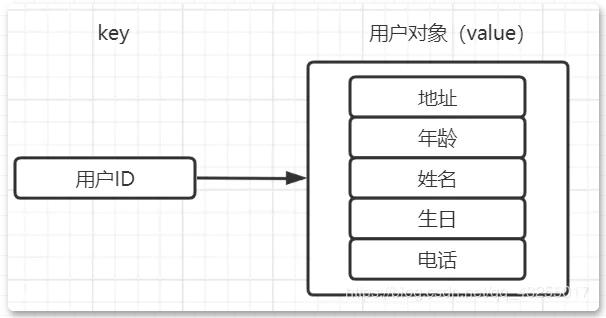
但是这样必然会造成序列化和反序列化的性能的开销,并且若是只修改其中的一个属性值,就需要把整个对象序列化出来,操作的动作太大,造成不必要的性能开销。
若是使用Redis的hash来存储用户数据,就会将原来的value值又看成了一个k v形式的存储容器,这样就不会带来序列化的性能开销的问题。
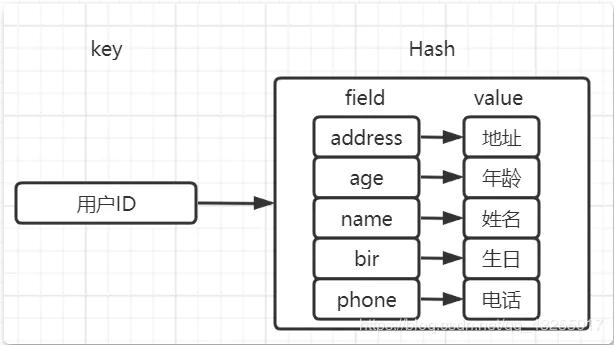
分布式生成唯一ID
第二个场景就是生成分布式的唯一ID,这个场景下就是把redis封装成了一个工具类进行实现,实现的代码如下:
// offset表示的是id的递增梯度值 public Long getId(String key,String hashKey,Long offset) throws BusinessException{ try { if (null == offset) { offset=1L; } // 生成唯一id return redisUtil.increment(key, hashKey, offset); } catch (Exception e) { //若是出现异常就是用uuid来生成唯一的id值 int randNo=UUID.randomUUID().toString().hashCode(); if (randNo <h3 id="List类型">List类型</h3><p>在 Redis 3.2 之前的版本,Redis 的列表是通过结合使用 ziplist 和 linkedlist 实现的。在3.2之后的版本就是引入了quicklist。</p><p>ziplist压缩列表上面已经讲过了,我们来看看linkedlist和quicklist的结构是怎么样的。</p><p>Linkedlist有双向链接,和普通的链表一样,都由指向前后节点的指针构成。时间复杂度为O(1)的操作包括插入、修改和更新,而时间复杂度为O(n)的操作是查询。</p><p>linkedlist和quicklist的底层实现是采用链表进行实现,在c语言中并没有内置的链表这种数据结构,Redis实现了自己的链表结构。</p><p><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168511087742882.jpg" class="lazy" alt="What is the underlying principle of redis"></p><p>Redis中链表的特性:</p><ol class=" list-paddingleft-2">
<li><p>每一个节点都有指向前一个节点和后一个节点的指针。</p></li>
<li><p>头节点和尾节点的prev和next指针指向为null,所以链表是无环的。</p></li>
<li><p>链表有自己长度的信息,获取长度的时间复杂度为O(1)。</p></li>
</ol><p>Redis中List的实现比较简单,下面我们就来看看它的应用场景。</p><h3 id="应用场景">应用场景</h3><p>Redis中的列表可以实现<strong>「阻塞队列」</strong>,结合lpush和brpop命令就可以实现。生产者使用lupsh从列表的左侧插入元素,消费者使用brpop命令从队列的右侧获取元素进行消费。</p><p>(1)首先配置redis的配置,为了方便我就直接放在application.yml配置文件中,实际中可以把redis的配置文件放在一个redis.properties文件单独放置,具体配置如下:</p><pre class="brush:php;toolbar:false">spring redis: host: 127.0.0.1 port: 6379 password: user timeout: 0 database: 2 pool: max-active: 100 max-idle: 10 min-idle: 0 max-wait: 100000(2)第二步创建redis的配置类,叫做RedisConfig,并标注上@Configuration注解,表明他是一个配置类。
@Configuration public class RedisConfiguration { @Value("{spring.redis.port}") private int port; @Value("{spring.redis.pool.max-active}") private int maxActive; @Value("{spring.redis.pool.min-idle}") private int minIdle; @Value("{spring.redis.database}") private int database; @Value("${spring.redis.timeout}") private int timeout; @Bean public JedisPoolConfig getRedisConfiguration(){ JedisPoolConfig jedisPoolConfig= new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(maxActive); jedisPoolConfig.setMaxIdle(maxIdle); jedisPoolConfig.setMinIdle(minIdle); jedisPoolConfig.setMaxWaitMillis(maxWait); return jedisPoolConfig; } @Bean public JedisConnectionFactory getConnectionFactory() { JedisConnectionFactory factory = new JedisConnectionFactory(); factory.setHostName(host); factory.setPort(port); factory.setPassword(password); factory.setDatabase(database); JedisPoolConfig jedisPoolConfig= getRedisConfiguration(); factory.setPoolConfig(jedisPoolConfig); return factory; } @Bean public RedisTemplate, ?> getRedisTemplate() { JedisConnectionFactory factory = getConnectionFactory(); RedisTemplate, ?> redisTemplate = new StringRedisTemplate(factory); return redisTemplate; } }(3)第三步就是创建Redis的工具类RedisUtil,自从学了面向对象后,就喜欢把一些通用的东西拆成工具类,好像一个一个零件,需要的时候,就把它组装起来。
@Component public class RedisUtil { @Autowired private RedisTemplate<string> redisTemplate; /** 存消息到消息队列中 @param key 键 @param value 值 @return */ public boolean lPushMessage(String key, Object value) { try { redisTemplate.opsForList().leftPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** 从消息队列中弹出消息 - <rpop> @param key 键 @return */ public Object rPopMessage(String key) { try { return redisTemplate.opsForList().rightPop(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** 查看消息 @param key 键 @param start 开始 @param end 结束 0 到 -1代表所有值 复制代码@return */ public List<object> getMessage(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } }</object></rpop></string>这样就完成了Redis消息队列工具类的创建,在后面的代码中就可以直接使用。
Set集合
Redis中列表和集合都可以用来存储字符串,但是「Set是不可重复的集合,而List列表可以存储相同的字符串」,Set集合是无序的这个和后面讲的ZSet有序集合相对。
Set的底层实现是「ht和intset」,ht(哈希表)前面已经详细了解过,下面我们来看看inset类型的存储结构。
inset也叫做整数集合,用于保存整数值的数据结构类型,它可以保存int16_t、int32_t 或者int64_t 的整数值。
在整数集合中,有三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容,length就是记录contents里面的大小。
在整数集合新增元素的时候,若是超出了原集合的长度大小,就会对集合进行升级,具体的升级过程如下:
首先扩展底层数组的大小,并且数组的类型为新元素的类型。
然后将原来的数组中的元素转为新元素的类型,并放到扩展后数组对应的位置。
整数集合升级后就不会再降级,编码会一直保持升级后的状态。
应用场景
Set集合的应用场景可以用来「去重、抽奖、共同好友、二度好友」等业务类型。接下来模拟一个添加好友的案例实现:
@RequestMapping(value = "/addFriend", method = RequestMethod.POST) public Long addFriend(User user, String friend) { String currentKey = null; // 判断是否是当前用户的好友 if (AppContext.getCurrentUser().getId().equals(user.getId)) { currentKey = user.getId.toString(); } //若是返回0则表示不是该用户好友 return currentKey==null?0l:setOperations.add(currentKey, friend); }
假如两个用户A和B都是用上上面的这个接口添加了很多的自己的好友,那么有一个需求就是要实现获取A和B的共同好友,那么可以进行如下操作:
public Set intersectFriend(User userA, User userB) { return setOperations.intersect(userA.getId.toString(), userB.getId.toString()); }举一反三,还可以实现A用户自己的好友,或者B用户自己的好友等,都可以进行实现。
ZSet集合
ZSet是有序集合,从上面的图中可以看到ZSet的底层实现是ziplist和skiplist实现的,ziplist上面已经详细讲过,这里来讲解skiplist的结构实现。
skiplist也叫做「跳跃表」,跳跃表是一种有序的数据结构,它通过每一个节点维持多个指向其它节点的指针,从而达到快速访问的目的。
skiplist由如下几个特点:
有很多层组成,由上到下节点数逐渐密集,最上层的节点最稀疏,跨度也最大。
每一层都是一个有序链表,只扫包含两个节点,头节点和尾节点。
每一层的每一个每一个节点都含有指向同一层下一个节点和下一层同一个位置节点的指针。
如果一个节点在某一层出现,那么该以下的所有链表同一个位置都会出现该节点。
具体实现的结构图如下所示:
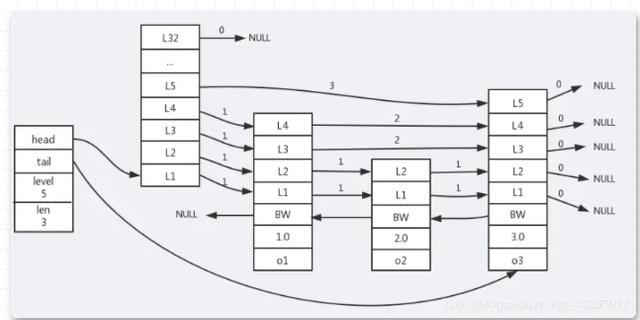
跳跃表的结构中包含指向头节点和尾节点的指针head和tail,能够快速进行定位。当在跳跃表中从尾向前遍历时,层数用 level 表示,跳跃表长度用 len 表示,同时也会使用后退指针 BW。
BW下面还有两个值分别表示分值(score)和成员对象(各个节点保存的成员对象)。
跳跃表的实现中,除了最底层的一层保存的是原始链表的完整数据,上层的节点数会越来越少,并且跨度会越来越大。
跳跃表的上面层就相当于索引层,都是为了找到最后的数据而服务的,数据量越大,条表所体现的查询的效率就越高,和平衡树的查询效率相差无几。
应用场景
因为ZSet是有序的集合,因此ZSet在实现排序类型的业务是比较常见的,比如在首页推荐10个最热门的帖子,也就是阅读量由高到低,排行榜的实现等业务。
下面就选用获取排行榜前前10名的选手作为案例实现,实现的代码如下所示:
@Autowired private RedisTemplate redisTemplate; /** * 获取前10排名 * @return */ public static List<levelvo> getZset(String key, long baseNum, LevelService levelService){ ZSetOperations<serializable> operations = redisTemplate.opsForZSet(); // 根据score分数值获取前10名的数据 Set<zsetoperations.typedtuple>> set = operations.reverseRangeWithScores(key,0,9); List<levelvo> list= new ArrayList<levelvo>(); int i=1; for (ZSetOperations.TypedTuple<object> o:set){ int uid = (int) o.getValue(); LevelCache levelCache = levelService.getLevelCache(uid); LevelVO levelVO = levelCache.getLevelVO(); long score = (o.getScore().longValue() - baseNum + levelVO .getCtime())/CommonUtil.multiplier; levelVO .setScore(score); levelVO .setRank(i); list.add( levelVO ); i++; } return list; }</object></levelvo></levelvo></zsetoperations.typedtuple></serializable></levelvo>以上的代码实现大致逻辑就是根据score分数值获取前10名的数据,然后封装成lawyerVO对象的列表进行返回。
The above is the detailed content of What is the underlying principle of redis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
