

What are the introductory knowledge points for Redis?

1. Introduction to Redis
REmote DIctionary Server (Redis) is a key-value storage system written by Salvatore Sanfilippo. Redis is an open source log-type Key-Value database written in ANSI C language, abides by the BSD protocol, supports the network, can be memory-based and persistent, and provides APIs in multiple languages. It is often called a data structure server because values can be of types such as String, Map, List, Sets and Sorted Sets.
Everyone knows that redis is a no sql database based on key-value, so let’s first learn about key-related knowledge points
1. Any binary sequence can be used as a key
2. Redis has unified rules to design keys
3. The maximum length allowed for key-value is 512MB
2. Supported languages
1 |
|
3. What are the application scenarios of Redis? ?
1. The most commonly used one is session cache
2. Message queue, such as payment
3. Activity ranking or count
4 , publish, subscribe to messages (message notifications)
5. Product list, comment list, etc.
4. Redis installation
About redis installation and related For an introduction to knowledge points, please refer to Nosql database service redis
The approximate installation steps are as follows:
Redis is developed in c language, and installing redis requires a c language compilation environment
If you don’t have gcc, you need to install it online: yum install gcc-c
Step 1: Get the source package: wget http://download.redis.io/rele...
Step 2 : Decompress redis: tar zxvf redis-3.0.0.tar.gz
Step 3: Compile. Enter the redis source code directory (cd redis-3.0.0). Execute make
Step 4: Installation. make install PREFIX=/usr/local/redis
The PREFIX parameter specifies the installation directory of redis
5. Redis data type
Redis supports a total of five Data types
1, string(string)
2, hash(hash)
3, list(list)
4, set (Set)
5, zset (sorted set ordered set)
string(string)
The most basic data type of Redis is key Value pairs, where one key corresponds to a value. It should be noted that a key-value pair can store up to 512MB.
1 |
|
Introduction to related commands
set sets the value for a Key
get gets the value corresponding to a key
getset sets the value (value) for a Key and returns the corresponding value
mset sets the value (value) for multiple keys
hash (hash)
redis hash is a collection of key-value pairs, a mapping table of string type fields and values, suitable for storing objects
1 |
|
Introduction to related commands
hset configures the field in the hash corresponding to the Key as value. If the hash does not exist, it will be automatically created.
hget obtains the value of the field configuration in a certain hash
hmset configures multiple field values in the same hash in batches
hmget obtains multiple field values in the same hash in batches
list(list)
is a simple string list in redis, which is sorted in insertion order
1 |
|
Related command introduction
lpush inserts elements to the left of the specified list and returns after insertion The length of the list
rpush inserts an element to the right side of the specified list and returns the length of the inserted list
llen returns the length of the specified list
lrange returns the specified range in the specified list The element value
set(set)
is an unordered set of string type and cannot be repeated
1 |
|
Introduction to related commands
sadd adds a string element to the set collection corresponding to key, returns 1 if successful, returns 0 if the element exists
smembers Returns all elements in the specified set
srem Delete an element of the specified set
zset (sorted set ordered set)
is an ordered set of string type and cannot be repeated
Each element in the sorted set needs to specify a score, and the elements are sorted in ascending order according to the score. If multiple elements have the same score, they are sorted in ascending order in lexicographic order. The sorted set is therefore very suitable for ranking
1 |
|
Related command introduction
zadd Add 1 or more elements to the specified sorteset
zrem Delete 1 or more elements from the specified sorteset Element
zcount View the number of elements within the specified score range in the specified sorteset
zscore View the elements with the specified score in the specified sorteset
zrangebyscore View the specified score in the specified sorteset All elements within the range
6, key value related commands
1 |
|
exists #Confirm whether the key exists
del #Delete key
expire #Set Key expiration time (in seconds)
persist #Remove Key expiration time configuration
rename #Rename key
type #Type of return value
7. Redis service Related commands
1 |
|
slect #选择数据库(数据库编号0-15)
quit #退出连接
info #获得服务的信息与统计
monitor #实时监控
config get #获得服务配置
flushdb #删除当前选择的数据库中的key
flushall #删除所有数据库中的key
8、Redis的发布与订阅
Redis发布与订阅(pub/sub)是它的一种消息通信模式,一方发送信息,一方接收信息。
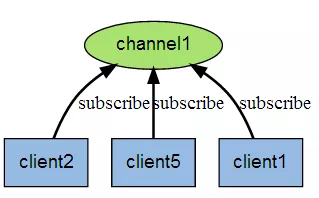
下图是三个客户端同时订阅同一个频道
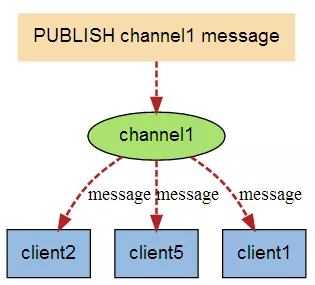
下图是有新信息发送给频道1时,就会将消息发送给订阅它的三个客户端
9、Redis事务
Redis事务可以一次执行多条命令
1、发送exec命令前放入队列缓存,结束事务
2、收到exec命令后执行事务操作,如果某一命令执行失败,其它命令仍可继续执行
3、一个事务执行的过程中,其它客户端提交的请求不会被插入到事务执行的命令列表中
一个事务经历三个阶段
开始事务(命令:multi)
命令执行
结束事务(命令:exec)
1 |
|
10、Redis安全配置
可以通过修改配置文件设备密码参数来提高安全性
#requirepass foobared
去掉注释#号就可以配置密码
没有配置密码的情况下查询如下
1 |
|
配置密码之后,就需要进行认证
1 |
|
11、Redis持久化
Redis持久有两种方式:Snapshotting(快照),Append-only file(AOF)
Snapshotting(快照)
1、将存储在内存的数据以快照的方式写入二进制文件中,如默认dump.rdb中
2、save 900 1
#900秒内如果超过1个Key被修改,则启动快照保存
3、save 300 10
#300秒内如果超过10个Key被修改,则启动快照保存
4、save 60 10000
#60秒内如果超过10000个Key被修改,则启动快照保存
Append-only file(AOF)
1、使用AOF持久时,服务会将每个收到的写命令通过write函数追加到文件中(appendonly.aof)
2、AOF持久化存储方式参数说明
appendonly yes
#开启AOF持久化存储方式
appendfsync always
#收到写命令后就立即写入磁盘,效率最差,效果最好
appendfsync everysec
#每秒写入磁盘一次,效率与效果居中
appendfsync no
#完全依赖OS,效率最佳,效果没法保证
12、Redis 性能测试
自带相关测试工具
1 |
|
实际测试同时执行100万的请求
1 |
|
13、Redis的备份与恢复
Redis自动备份有两种方式
第一种是通过dump.rdb文件实现备份
第二种使用aof文件实现自动备份
dump.rdb备份
Redis服务默认的自动文件备份方式(AOF没有开启的情况下),在服务启动时,就会自动从dump.rdb文件中去加载数据。
**具体配置在redis.conf
save 900 1
save 300 10
save 60 10000**
也可以手工执行save命令实现手动备份
1 |
|
redis快照到dump文件时,会自动生成dump.rdb的文件
1 |
|
SAVE命令表示使用主进程将当前数据库快照到dump文件
BGSAVE命令表示,主进程会fork一个子进程来进行快照备份
两种备份不同之处,前者会阻塞主进程,后者不会。
恢复举例
1 |
|
将备份文件备份到其它目录
1 |
|
删除数据
1 |
|
关闭服务,将原备份文件拷贝回save备份目录
1 |
|
登录查看数据是否恢复
1 |
|
AOF自动备份
redis服务默认是关闭此项配置
1 |
|
配置文件的相关参数,前面已经详细介绍过。
AOF文件备份,是备份所有的历史记录以及执行过的命令,和mysql binlog很相似,在恢复时就是重新执次一次之前执行的命令,需要注意的就是在恢复之前,和数据库恢复一样需要手工删除执行过的del或误操作的命令。
AOF与dump备份不同
1、aof文件备份与dump文件备份不同
2、服务读取文件的优先顺序不同,会按照以下优先级进行启动
如果只配置AOF,重启时加载AOF文件恢复数据
如果同时 配置了RBD和AOF,启动是只加载AOF文件恢复数据
如果只配置RBD,启动时将加载dump文件恢复数据
注意:只要配置了aof,但是没有aof文件,这个时候启动的数据库会是空的
14、Redis 生产优化介绍
1、内存管理优化
1 |
|
在linux环境运行Redis时,如果系统的内存比较小,这个时候自动备份会有可能失败,需要修改系统的vm.overcommit_memory 参数,这个参数是linux系统的内存分配策略
0 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2 表示内核允许分配超过所有物理内存和交换空间总和的内存
Redis官方的说明是,建议将vm.overcommit_memory的值修改为1,可以用下面几种方式进行修改:
(1)编辑/etc/sysctl.conf 改vm.overcommit_memory=1,然后sysctl -p 使配置文件生效
(2)sysctl vm.overcommit_memory=1
(3)echo 1 > /proc/sys/vm/overcommit_memory
**2、内存预分配
3、持久化机制**
定时快照:效率不高,会丢失数据
AOF:保持数据完整性(一个实例的数量不要太大2G最大)
优化总结
1)根据业务需要选择合适的数据类型
2)当业务场景不需持久化时就关闭所有持久化方式(采用ssd磁盘来提升效率)
3)不要使用虚拟内存的方式,每秒实时写入AOF
4)不要让REDIS所在的服务器物理内存使用超过内存总量的3/5
5)要使用maxmemory
6)大数据量按业务分开使用多个redis实例
15、Redis集群应用
集群是将多个redis实例集中在一起,实现同一业务需求,或者实现高可用与负载均衡
到底有哪些集群方案呢??
1、haproxy+keepalived+redis集群
1)通过redis的配置文件,实现主从复制、读写分离
2)通过haproxy的配置,实现负载均衡,当从故障时也会及时从集群中T除
3)利用keepalived来实现负载的高可用
2、redis官方Sentinel集群管理工具
Redis集群生产环境高可用方案实战过程
1)sentinel负责对集群中的主从服务监控、提醒和自动故障转移
2)redis集群负责对外提供服务
关于redis sentinel cluster集群配置可参考
3、Redis Cluster
Redis Cluster是Redis的分布式解决方案,在Redis 3.0版本正式推出的,有效解决了Redis分布式方面的需求。Cluster架构可用于实现负载均衡,以解决单机内存、并发和流量等瓶颈问题。
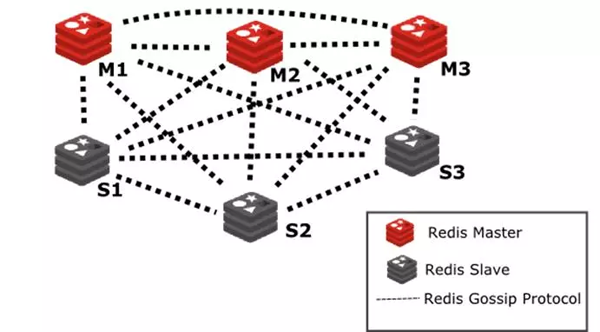
1)官方推荐,毋庸置疑。
2)去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。
3)管理方便,后续可自行增加或摘除节点,移动分槽等等。
4)简单,易上手。
The above is the detailed content of What are the introductory knowledge points for Redis?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
37
111
52
37
111

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
