

The clustered index is the primary key-based index structure created by innodb by default, and the data in the table is directly placed in the clustered index as the data page of the leaf node:
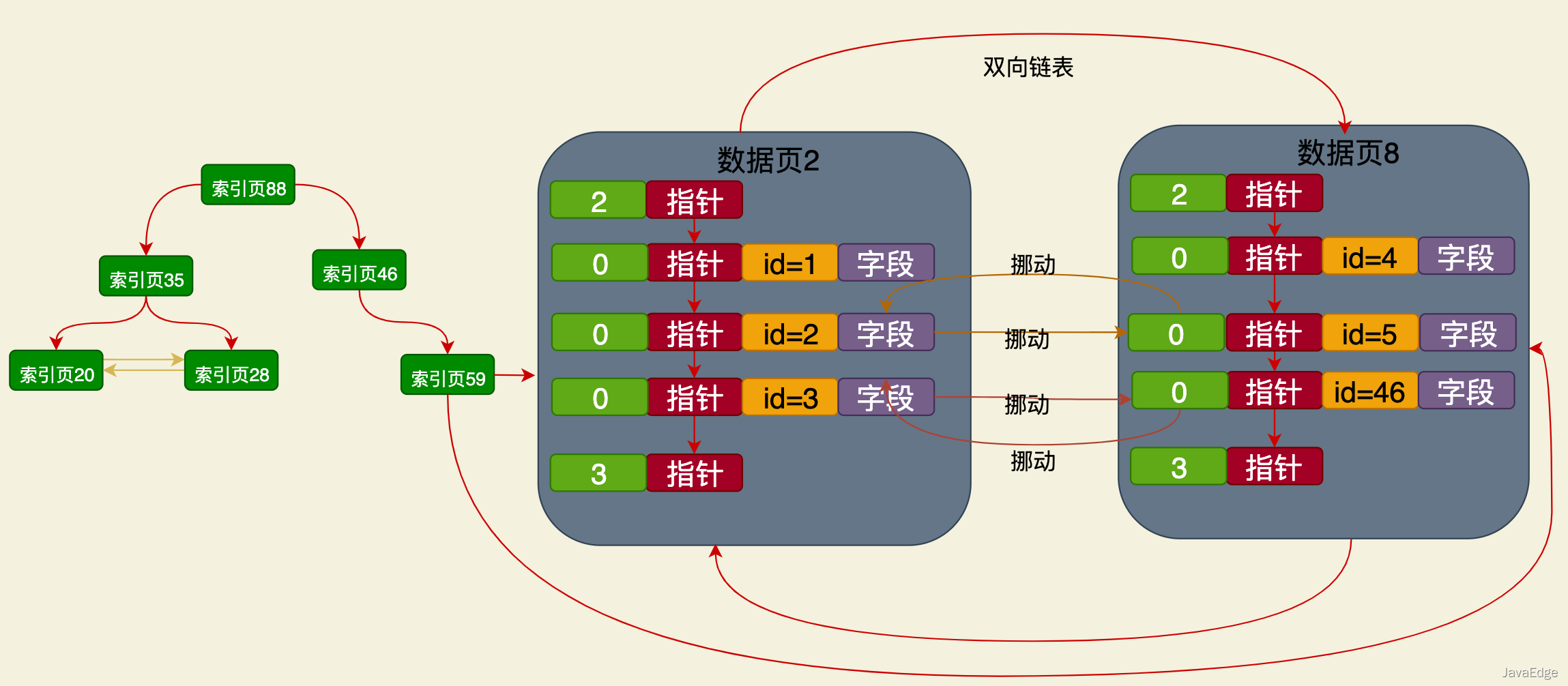
Data search based on primary key: Start a binary search from the root node of the clustered index, find the corresponding data page all the way, and directly locate the primary key target data based on the page directory.
If you want to create an index on other fields, or even create a joint index based on multiple fields, what is the index structure like at this time?
Assuming that other fields are indexed, such as name, age, etc., the same principle applies. For example, when you insert data:
Insert the complete data into the data page of the leaf node of the clustered index, and maintain the clustered index at the same time
For the indexes created for your other fields, re-create a B-tree
#For example, if you create an index based on the name field, when data is inserted, a B-tree will be re-created. , the leaf node of the B-tree is also a data page, but only the primary key field and the name field are placed in this data page:
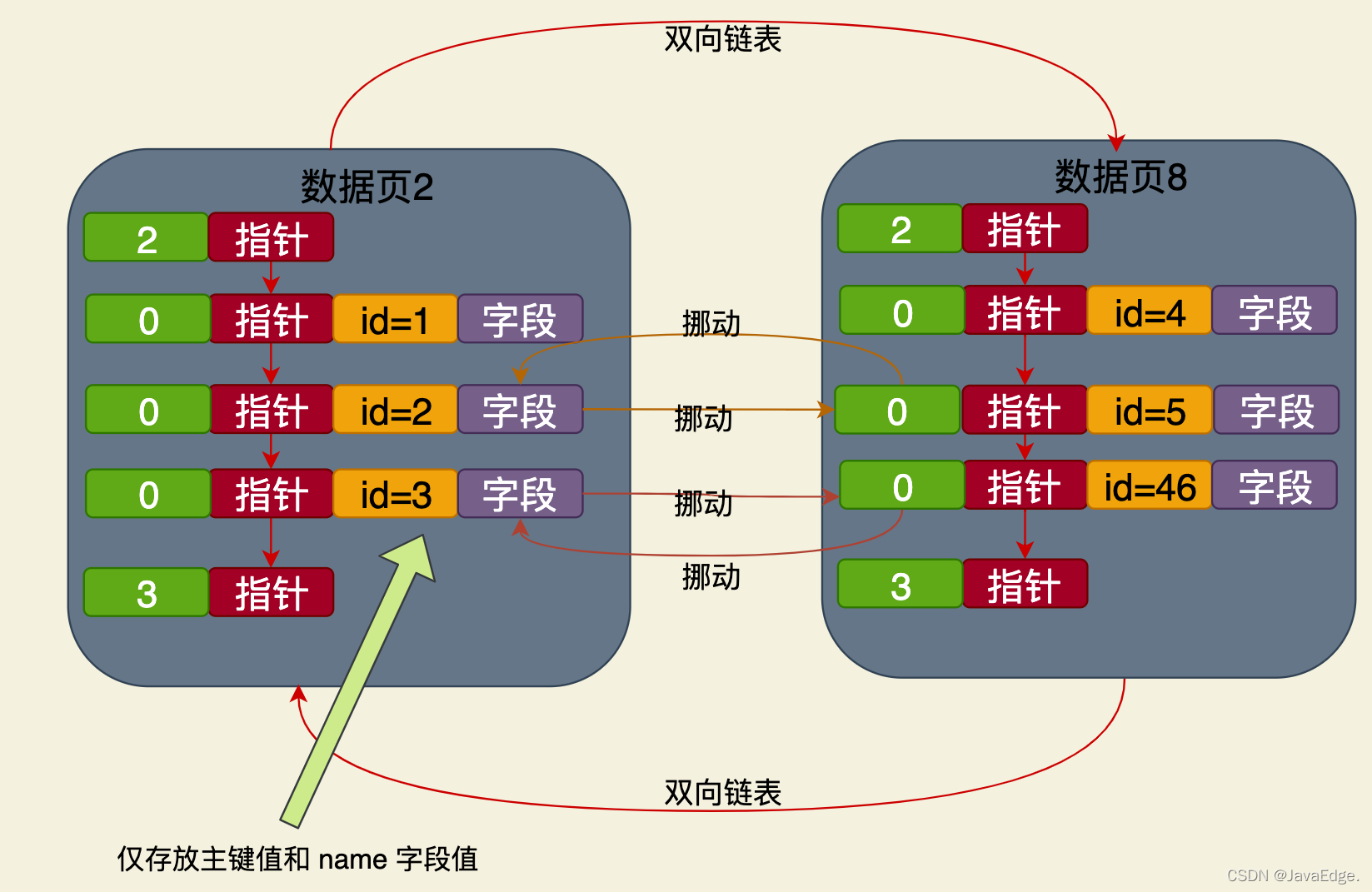
This is a name field based on the B-tree that is independent of the cluster The index structure of a cluster index, the data stored in its leaf nodes only contains the values of the primary key and name fields.
The overall sorting rules are the same as the sorting rules of the clustered index according to the primary key, that is:
The name values in the data pages of the leaf nodes are all sorted
The name field value in the next data page is > the name field value in the previous data page
The index B tree of the name field is also A multi-level index page will be constructed. The index page stores:
The page number of the next level
The minimum name field value, according to name Field value sorting.
So if you query data based on the name field, the process is the same. Start from the root node of the name index tree and search down layer by layer until you find the data page of the leaf node. Locate the primary key value corresponding to the name field value.
Then for statements like
select * from t where name='xx'
, first search in the name index tree based on the name value, and find the leaf node. Only the corresponding primary key value can be found, but this row of data cannot be found. all fields.
So we still need to return to the table: we need to go to the clustered index starting from the root node according to the primary key value, find the data page of the leaf node, and locate the complete data row corresponding to the primary key value. At this time Only then can all the field values required by select * be taken out.
For example, name age, the running process is the same, and an independent B tree is established. After the data page of the leaf node stores the id name age, it is sorted by name by default. For the same name, it is sorted by name. Age ranking, the same is true for the sorting of name age values between different data pages.
Then the index page of the B-tree of the joint index of this name age is stored:
The page number of the next layer node
The smallest name age value
So when you search based on name age, you will go through the name age joint index tree, search for the primary key, and then go to the clustered index based on the primary key. Go search.
The above is the detailed content of What is the MySQL secondary index query process?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



