

A deadlock occurred in the production environment. By checking the deadlock log, I saw that the deadlock was caused by two identical update statements (only the values in the where condition were different),
is as follows:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0;
It was difficult to understand at first. After a lot of inquiry and study, I analyzed the specific principles of deadlock formation. I would like to share it with everyone in the hope that it can help anyone who encounters it. Friends with the same problem.
Because there are many knowledge points in MySQL, many nouns will not be introduced too much here. Friends who are interested can follow up with special in-depth study.
*** (1) TRANSACTION: TRANSACTION 791913819, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 LOCK WAIT 4 lock struct(s), heap size 1184, 3 row lock(s) MySQL thread id 462005230, OS thread handle 0x7f55d5da3700, query id 2621313306 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx1' AND `status` = 0; *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913819 lock_mode X waiting Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) TRANSACTION: TRANSACTION 791913818, ACTIVE 0 sec starting index read, thread declared inside InnoDB 4999 mysql tables in use 3, locked 3 5 lock struct(s), heap size 1184, 4 row lock(s) MySQL thread id 462005231, OS thread handle 0x7f55cee63700, query id 2621313305 x.x.x.x test_user Searching rows for update UPDATE test_table SET `status` = 1 WHERE `trans_id` = 'xxx2' AND `status` = 0; *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 110 page no 39167 n bits 1056 index `idx_status` of table `test`.`test_table` trx id 791913818 lock_mode X Record lock, heap no 495 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 110 page no 41569 n bits 88 index `PRIMARY` of table `test`.`test_table` trx id 791913818 lock_mode X locks rec but not gap waiting Record lock, heap no 14 PHYSICAL RECORD: n_fields 30; compact format; info bits 0 *** WE ROLL BACK TRANSACTION (1)
Briefly analyze the above deadlock log:
1. The first content ( Lines 1 to 9), line 6 is the SQL statement executed by transaction (1), lines 7 and 8 mean that transaction (1) is waiting for the X lock on the idx_status index;
2. In the second block of content (line 11 to line 19), line 16 is the SQL statement executed by transaction (2), and lines 17 and 18 mean that transaction (2) holds the idx_status index The X lock on;
means: Transaction (2) is waiting to acquire the X lock on the PRIMARY index. (but not gap means not a gap lock)
4. The last sentence means that MySQL rolled back transaction (1).
CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `trans_id` varchar(21) NOT NULL, `status` int(11) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `uniq_trans_id` (`trans_id`) USING BTREE, KEY `idx_status` (`status`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
As can be seen from the table structure, there is a unique index on the trans_id columnuniq_trans_id ,status There is a normal index on the column idx_status, and the id column is the primary key index PRIMARY .
There are two kinds of indexes in the InnoDB engine:
Clustered index: Put the data storage and index together , the leaf nodes of the index structure store row data.
Auxiliary index: The auxiliary index leaf node stores the primary key value, which is the key value of the clustered index.
Primary key index PRIMARY is a clustered index, and row data will be stored in leaf nodes. uniq_trans_id Index and idx_status The index is an auxiliary index, and the leaf node stores the primary key value, which is the id column value.
When we search for row data through the auxiliary index, we first find the primary key id through the auxiliary index, then perform a secondary search through the primary key index (also called back to the table), and finally find the row data.
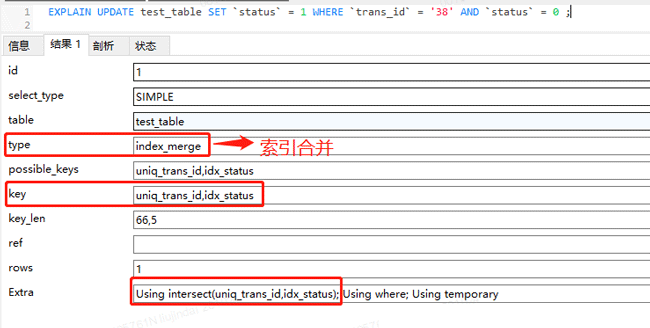
By looking at the execution plan, you can find that the update statement uses index merging, that is, this statement uses both uniq_trans_id Index is used again idx_status Index, Using intersect(uniq_trans_id,idx_status) means to obtain the intersection through two indexes.
Before MySQL5.0, a table could only use one index at a time, and multiple indexes could not be used at the same time for conditional scans. But starting from 5.1, index merge optimization technology has been introduced, and multiple indexes can be used to perform conditional scans on the same table.
For example, the statement in the execution plan:
UPDATE test_table SET `status` = 1 WHERE `trans_id` = '38' AND `status` = 0 ;
MySQL will use uniq_trans_id# based on the condition trans_id = ‘38’ ## The index finds the id value saved in the leaf node; at the same time, according to the condition status = 0, the idx_status index is used to find the id value saved in the leaf node; then the two found The group ID values are intersected, and finally the intersection ID is returned to the table, that is, the row data saved in the leaf node is found through the PRIMARY index.
uniq_trans_id is already a unique index. Only one piece of data can be found at most through this index. Then why does the MySQL optimizer use two Take the intersection of two indexes and then return to the table for query. Doesn't this add another idx_status index search process? Let's analyze the execution process of these two situations.
The first one only uses uniq_trans_id index:
, useuniq_trans_id Index finds the id value saved in the leaf node;
condition.
:
Query conditions, use uniq_trans_id index to find the id value saved in the leaf node;
Query conditions, use idx_status index to find the id value saved in the leaf node;
Take the intersection of the id values found in 1/2, and then use the PRIMARY index to find the row data saved in the leaf node
In the above two cases, The main difference is that the first method is to find the data through an index first, and then use other query conditions to filter; the second method is to first obtain the intersection of the id values found through the two indexes. If there is still an id value after the intersection, , then go back to the table to get the data.
When the optimizer believes that the execution cost of the second case is smaller than that of the first case, index merging will occur. (There is very little data in the production environment flow table with status = 0, which is one of the reasons why the optimizer considers the second case).
Why is it deadlocked after using index_merge
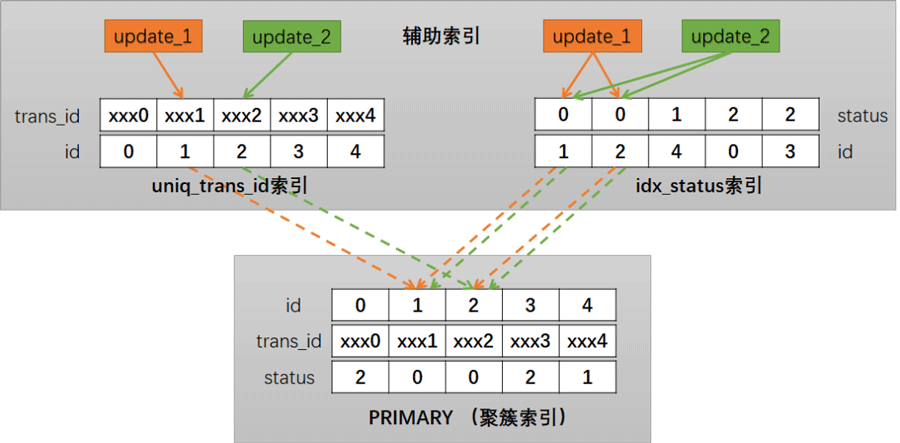
The above briefly draws the process of locking two update transactions. As can be seen in the figure, there are overlapping and intersecting parts on both the idx_status index and PRIMARY (clustered index), which creates conditions for deadlock.
For example, a deadlock will occur when the following timing is encountered:
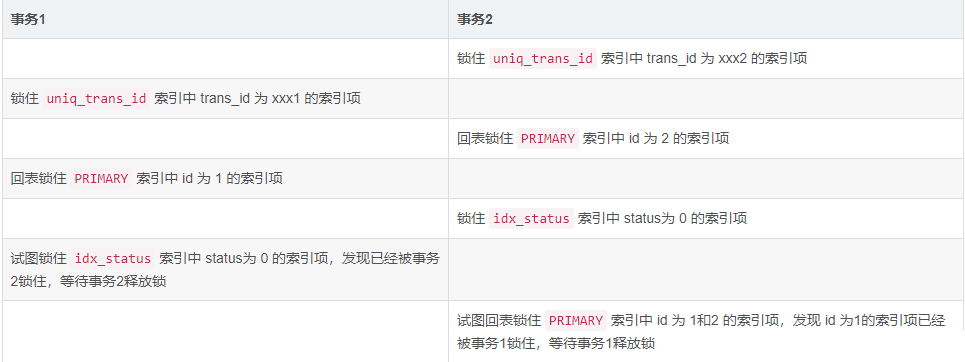
Transaction 1 waits for transaction 2 to release the lock, Transaction 2 waits for transaction 1 to release the lock, thus causing a deadlock.
After MySQL detects a deadlock, it will automatically roll back the transaction with the lower cost. As in the timing diagram above, if transaction 1 holds fewer locks than transaction 2, then MySQL will proceed with transaction 1. rollback.
#where query conditions, only pass trans_id to query the data Finally, determine whether the status is 0 at the code level;
Use force index(uniq_trans_id) Force the query statement to use the uniq_trans_id index;
where use the id field directly after the query condition and update it through the primary key.
or create a joint index containing these two columns;
Turn off the index merge optimization of the MySQL optimizer.
The above is the detailed content of How to solve the deadlock caused by MySQL optimization index merge. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



