

Python operation redis instance analysis

redis is a Key-Value database. Value supports string (string), list (list), set (set), zset (ordered set), hash (hash type) and other types.
1. Installation
pip install redis
2. Two ways to connect to redis
1. Method 1 regular connection to redis
import redis r = redis(host='localhost', port=6379, db=0) r.set('foo', 'bar') print(r.get('foo'))
The output result is:
b'bar'
2. Method 2 uses connection pool
By default, each Redis instance will maintain its own connection pool. You can directly establish a connection pool and then use it as a parameter to Redis, so that multiple Redis instances can share a connection pool.
import redis pool = redis.ConnectionPool(host='localhost', port=6379, db=0) r = redis.Redis(connection_pool=pool) r.set('foo', 'bar') print(r.get('foo')) r.close()# 记得关闭连接池
The output result is:
b'bar'
3. Output result modification
The result taken out by redis defaults to bytes, we can set decode_responses=TrueChange to string
import redis r = redis(host='localhost', port=6379, db=0, decode_responses=True) r.set('foo', 'bar') print(r.get('foo'))
The output result is:
'bar'
4. Six data types of redis
1. Usage scenarios of different data types of redis
1) String
Counter application
2) List
Operation to get the latest N data
Message queue
Delete and filter
Real-time analysis of what is happening, used for data statistics and spam prevention (combined with Set)
3) Set
Uniqe operation to obtain all data rankings for a certain period of time Heavy value
Real-time system, anti-spam system
Mutual friends, second-time friends
Using uniqueness, all independent IPs that visit the website can be counted
When recommending friends, find the intersection based on the tag. If it is greater than a certain threshold, you can recommend
4) Hashes
Store, read, and modify user attributes
5) Sorted Set
Ranking applications, take TOP N operations
Applications that need to accurately set the expiration time (timestamp as Score)
Elements with weight, such as a game User score ranking list
Processing of expired items, sorted by time
2. Examples of six different data types in redis
1) String type String
String in redis is stored in memory according to one name corresponding to one value. As shown in the figure:
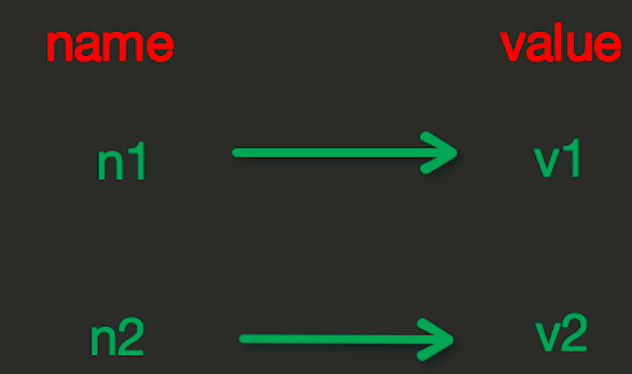
set(name, value, ex=None, px=None, nx=False, xx=False)
- ex - Expiration time (seconds)
- px - Expiration time (milliseconds)
- nx - If set to True, the current set operation will be executed only if name does not exist (newly created)
# 前提redis数据库db 当中没有key='foo' import redis r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True) r.set('foo', 'bar', nx=True) print(r.get('foo'))Copy after login
Output:'bar'
Copy after loginCopy after login - xx - If set to True, the current set operation will be executed (modified) only if name exists.
# 前提redis数据库db=3 当中没有key='foo'
import redis
r = redis.Redis(host='199.28.10.122', port=6389, db=3, password='test1234', decode_responses=True)
r.set('foo', 'bar', xx=True)
print(r.get('foo'))None
setnx(name, value)
# 前提redis数据库db当中没有key='too' import redis r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True) r.setnx('too', 'tar') print(r.get('too')) r.setnx('too', 'looktar') print(r.get('too'))
‘tar’ ‘tar’ # 因为第一个setnx已经添加了对应数据,所以执行setnx添加('too', 'looktar')是不执行的
setex(name, time, value)
import redis
import time
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.setex('foo', 5, 'bar')
print(r.get('foo'))
print('等待5秒')
time.sleep(5)
print(r.get('foo'))bar 等待5秒 None # 5秒之后数据过期了
psetex(name, time_ms, value)
import redis
import time
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.psetex('foo', 5000, 'bar')
print(r.get('foo'))
print('等待5秒')
time.sleep(5)
print(r.get('foo'))bar 等待5秒 None # 5秒之后数据过期了
mset(*args, **kwargs)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.mset({'k1': 'v1', 'k2': 'v2'})
print(r.mget("k1", "k2")) # 一次取出多个键对应的值
print(r.mget("k1"))['v1', 'v2'] ['v1']
mget(keys, *args)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.mset({'k1': 'v1', 'k2': 'v2'})
print(r.mget("k1", "k2")) # 一次取出多个键对应的值
# 或
print(r.mget(["k1", "k2"])) # 一次取出多个键对应的值
print(r.mget("k1"))['v1', 'v2'] ['v1', 'v2'] ['v1']
getset(name, value)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set('food', 'beef')
print(r.get('food'))
print(r.getset("food", "barbecue")) # 设置的新值是barbecue 设置前的值是beef
print(r.get('food'))beef # 原来的值 beef # return的是原来的值 barbecue # 重新获取“food”的值
getrange(key, start, end)
- name - Redis name
- start - starting position (bytes)
- end - ending position (bytes)
character Chinese character in Python occupies three bytes under utf-8 encoding, and occupies 3 bytes under gbk encoding Two bytes)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set("cn_name", "祖国万岁") # 汉字
print(r.getrange("cn_name", 0, 2)) # 取索引号是0-2 前3位的字节 祖 切片操作 (一个汉字3个字节 1个字母一个字节 每个字节8bit)
print(r.getrange("cn_name", 0, -1)) # 取所有的字节 祖国万岁 切片操作
r.set("en_name","zuguowansui") # 字母
print(r.getrange("en_name", 0, 2)) # 取索引号是0-2 前3位的字节 zug 切片操作 (一个汉字3个字节 1个字母一个字节 每个字节8bit)
print(r.getrange("en_name", 0, -1)) # 取所有的字节 uguowansui 切片操作Running results:
祖 祖国万岁 zug zuguowansui
1.9 setrange modifies the string content
setrange(name, offset, value)
Modifies the string content and replaces backward starting from the specified string index ( When the new value is too long, it will be added backward)
Parameters:
offset - the index of the string, bytes (one Chinese character is three bytes)
value - the value to be set
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.setrange("en_name", 1, "ccc")
print(r.get("en_name")) # zcccowansui 原始值是zuguowansui 从索引号是1开始替换成cccRunning result:
zcccowansui
1.10 setbit bit of the binary representation of the corresponding value of name Perform operations
setbit(name, offset, value)
Operation on the bits of the binary representation of the corresponding value of name
Parameters:
Note: If there is a corresponding in Redis: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
name - redis的name
offset - 位的索引(将值变换成二进制后再进行索引)
value - 值只能是 1 或 0
1.11 getbit 获取name对应的值的二进制表示中的某位的值 (0或1)
getbit(name, offset)
获取name对应的值的二进制表示中的某位的值 (0或1)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.getbit("foo1", 0)) # 0 foo1 对应的二进制 4个字节 32位 第0位是0还是11.12 bitcount获取name对应的值的二进制表示中 1 的个数
bitcount(key, start=None, end=None)
获取name对应的值的二进制表示中 1 的个数
参数:
key - Redis的name
start - 字节起始位置
end - 字节结束位置
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set('foo','baksks')
print(r.get("foo")) # goo1 01100111
print(r.bitcount("foo",0,1)) # 11运行结果:
baksks 6
1.13 bittop获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
bitop(operation, dest, *keys)
获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
参数:
operation - AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
dest - 新的Redis的name
*keys - 要查找的Redis的name
如:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set("n1", 'goo1')
r.set("n2", 'baaanew')
r.set("n3", 'appaanew')
r.bitop("AND", 'new_name', 'n1', 'n2', 'n3')
print(r.get('new_name'))运行结果:
```!
1.14 strlen返回name对应值的字节长度(一个汉字3个字节)
strlen(name)
返回name对应值的字节长度(一个汉字3个字节)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set('foo1s', 'flash')
print(r.strlen("foo1s"))运行结果:
5
1.15 incr自增 name 对应的值,当 name 不存在时,则创建 name=amount,否则,则自增
incr(self, name, amount=1)
自增 name 对应的值,当 name 不存在时,则创建 name=amount,否则,则自增。
参数:
name - Redis的name
amount - 自增数(必须是整数)
注:同 incrby
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set('foo1', 'flash')
r.set('foo2', 'fla2sh')
r.set("foo", 123)
print(r.mget("foo", "foo1", "foo2", "k1", "k2"))
r.incr("foo", amount=1)
print(r.mget("foo", "foo1", "foo2", "k1", "k2"))
r.incr("foono", amount=1) # 不存在‘foono’
print(r.mget("foono", "foo1", "foo2", "k1", "k2"))运行结果:
['123', 'flash', 'fla2sh', 'v1', 'v2'] ['124', 'flash', 'fla2sh', 'v1', 'v2'] ['1', 'flash', 'fla2sh', 'v1', 'v2'] # 当 name 不存在时,则创建 name=amount
应用场景:
假定我们对一系列页面需要记录点击次数。点击次数远远超过回帖次数,因此需要记录论坛的每个帖子的点击次数。如果使用关系数据库来存储点击,可能存在大量的行级锁争用。所以,点击数的增加使用redis的INCR命令最好不过了。
当redis服务器启动时,可以从关系数据库读入点击数的初始值(12306这个页面被访问了34634次)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set("visit:12306:totals", 34634)
print(r.get("visit:12306:totals"))
r.incr("visit:12306:totals")
print(r.get("visit:12306:totals"))
运行结果:
34634 34635
1.16 incrbyfloat自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
incrbyfloat(self, name, amount=1.0)
自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
参数:
name - Redis的name
amount - 自增数(浮点型)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set("foo1", "123.0")
r.set("foo2", "221.0")
print(r.mget("foo1", "foo2"))
r.incrbyfloat("foo1", amount=2.0)
r.incrbyfloat("foo2", amount=3.0)
print(r.mget("foo1", "foo2"))运行结果:
['123.0', '221.0'] ['125', '224']
1.17 decr自减 name 对应的值,当 name 不存在时,则创建 name=amount,否则,则自减。
decr(self, name, amount=1)
自减 name 对应的值,当 name 不存在时,则创建 name=amount,否则,则自减。
参数:
name - Redis的name
amount - 自减数(整数)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set("foo1", "123")
r.set("foo4", "221")
r.decr("foo4", amount=3) # 递减3
r.decr("foo1", amount=1) # 递减1
print(r.mget("foo1", "foo4"))运行结果:
['122', '218']
1.18 appen在 name对应的值后面追加内容
append(key, value)
在redis name对应的值后面追加内容
参数:
key - redis的name
value - 要追加的字符串
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.set("foo1", "123")
r.append("foo1", "haha") # 在name对应的值junxi后面追加字符串haha
print(r.mget("foo1"))运行结果:
['123haha']
2)hash
2.1 hset单个增加--修改(单个取出)--没有就新增,有的话就修改
hset(name, key, value)
name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
name - redis的name
key - name对应的hash中的key
value - name对应的hash中的value
注:hsetnx(name, key, value) 当name对应的hash中不存在当前key时则创建(相当于添加
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hset("hash1", "k1", "v1")
r.hset("hash1", "k2", "v2")
print(r.hkeys("hash1")) # 取hash中所有的key
print(r.hget("hash1", "k1")) # 单个取hash的key对应的值
print(r.hmget("hash1", "k1", "k2")) # 多个取hash的key对应的值
r.hsetnx("hash1", "k2", "v3") # 只能新建
print(r.hget("hash1", "k2"))运行结果:
['k1', 'k2'] v1 ['v1', 'v2'] v2 # 这里因为存在所以原值没有被修改,没有新增
2.2 hmset在name对应的hash中批量设置键值对
hmset(name, mapping)
在name对应的hash中批量设置键值对
参数:
name - redis的name
mapping - 字典,如:{'k1':'v1', 'k2': 'v2'}
如:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hget("hash2", 'k2'))运行结果:
v2
2.3 hmget在name对应的hash中获取多个key的值
hmget(name, keys, *args)
在name对应的hash中获取多个key的值
参数:
name - reids对应的name
keys - 要获取key集合,如:['k1', 'k2', 'k3']
*args - 要获取的key,如:k1,k2,k3
如:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hget("hash2", "k2")) # 单个取出"hash2"的key-k2对应的value
print(r.hmget("hash2", "k2", "k3")) # 批量取出"hash2"的key-k2 k3对应的value --方式1
print(r.hmget("hash2", ["k2", "k3"])) # 批量取出"hash2"的key-k2 k3对应的value --方式2运行结果:
v2 ['v2', 'v3'] ['v2', 'v3']
2.4 hgetall取出所有键值对
hgetall(name)
获取name对应hash的所有键值
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hgetall("hash2"))运行结果:
{'k2': 'v2', 'k3': 'v3'}2.5 hlen得到所有键值对的格式 hash长度
hlen(name)
获取name对应的hash中键值对的个数
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hlen("hash2"))运行结果:
2
2.6 hkeys得到所有的keys(类似字典的取所有keys)
hkeys(name)
获取name对应的hash中所有的key的值
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hkeys("hash2"))运行结果:
['k2', 'k3']
2.7 hvals得到所有的value(类似字典的取所有value)
hvals(name)
获取name对应的hash中所有的key的值
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hvals("hash2"))运行结果:
['v2', 'v3']
2.8 hvals判断成员是否存在(类似字典的in)
hexists(name, key)
检查 name 对应的 hash 是否存在当前传入的 key
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hmset("hash2", {"k2": "v2", "k3": "v3"})
print(r.hexists("hash2", "k4")) # False 不存在
print(r.hexists("hash2", "k2")) # True 存在运行结果:
False True
2.9 hdel删除键值对
hdel(name,*keys)
将name对应的hash中指定key的键值对删除
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.hgetall("hash1"))
r.hset("hash1", "k2", "v222") # 修改已有的key k2
r.hset("hash1", "k11", "v1") # 新增键值对 k11
r.hdel("hash1", "k1") # 删除一个键值对
print(r.hgetall("hash1"))运行结果:
{'k2': 'v222', 'k11': 'v1', 'k3': 'v22332', 'k1': 'v1'}
{'k2': 'v222', 'k11': 'v1', 'k3': 'v22332'} # k1被删除了2.10 hincrby自增自减整数(将key对应的value--整数 自增1或者2,或者别的整数 负数就是自减)
hincrby(name, key, amount=1)
自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
name - redis中的name
key - hash对应的key
amount - 自增数(整数)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.hset("hash1", "k3", 123)
r.hincrby("hash1", "k3", amount=-1)
print(r.hgetall("hash1"))
r.hincrby("hash1", "k4", amount=1) # 不存在的话,value默认就是1
print(r.hgetall("hash1"))运行结果:
{'k2': 'v222', 'k11': 'v1', 'k3': '122'}
{'k2': 'v222', 'k11': 'v1', 'k3': '122', 'k4': '1'}2.11 hscan取值查看--分片读取
hscan(name, cursor=0, match=None, count=None)
增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
参数:
name - redis的name
cursor - 游标(基于游标分批取获取数据)
match - 匹配指定key,默认None 表示所有的key
count - 每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.hgetall("hash1"))
print(r.hscan("hash1"))运行结果:
{'k2': 'v222', 'k11': 'v1', 'k3': '122', 'k4': '1'}
(0, {'k2': 'v222', 'k11': 'v1', 'k3': '122', 'k4': '1'})2.12 hscan_iter利用yield封装hscan创建生成器,实现分批去redis中获取数据
hscan_iter(name, match=None, count=None))
利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
match - 匹配指定key,默认None 表示所有的key
count - 每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.hgetall("hash1"))
for item in r.hscan_iter('hash1'):
print(item)
print(r.hscan_iter("hash1")) # 生成器内存地址运行结果:
{'k2': 'v222', 'k11': 'v1', 'k3': '122', 'k4': '1'}
('k2', 'v222')
('k11', 'v1')
('k3', '122')
('k4', '1')3)list
3.1 lpush增加(类似于list的append,只是这里是从左边新增加)--没有就新建
lpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最左边
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lpush("list1", 11, 22, 33)
print(r.lrange('list1', 0, -1))运行结果:
['33', '22', '11']
3.2 rpush增加(类似于list的append,只是这里是从右边新增加)--没有就新建
rpush(name,values)
在name对应的list中添加元素,每个新的元素都添加到列表的最右边
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.rpush("list2", 11, 22, 33)
print(r.lrange('list2', 0, -1))运行结果:
['11', '22', '33']
3.3 llen查询列表长度
llen(name)
在name对应的list中添加元素,每个新的元素都添加到列表的最右边
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.rpush("list2", 11, 22, 33)
print(r.llen("list2")) # 列表长度
print(r.lrange('list2', 0, -1))运行结果:
6 ['11', '22', '33', '11', '22', '33']
3.4 lpushx往已经有的name的列表的左边添加元素,没有的话无法创建
lpushx(name,value)
在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
更多:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lpushx("list10", 10) # 这里list10不存在
print(r.llen("list10")) # 0
print(r.lrange("list10", 0, -1)) # []
r.lpushx("list2", 77) # 这里"list2"之前已经存在,往列表最左边添加一个元素,一次只能添加一个
print(r.llen("list2")) # 列表长度
print(r.lrange("list2", 0, -1)) # 切片取出值,范围是索引号0到-1(最后一个元素运行结果:
0 [] 7 ['77', '11', '22', '33', '11', '22', '33']
3.5 rpushx往已经有的name的列表的右边添加元素,没有的话无法创建
rpushx(name,value)
在name对应的list中添加元素,只有name已经存在时,值添加到列表的最右边
更多:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.rpushx("list2", 99) # 这里"foo_list1"之前已经存在,往列表最右边添加一个元素,一次只能添加一个
print(r.llen("list2")) # 列表长度
print(r.lrange("list2", 0, -1)) # 切片取出值,范围是索引号0到-1(最后一个元素)运行结果:
8 ['77', '11', '22', '33', '11', '22', '33', '99']
3.6 linsert新增(固定索引号位置插入元素)
linsert(name, where, refvalue, value)
在name对应的列表的某一个值前或后插入一个新值
参数:
name - redis的name
where - BEFORE或AFTER
refvalue - 标杆值,即:在它前后插入数据
value - 要插入的数据
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.linsert("list2", "before", "11", "00") # 往列表中左边第一个出现的元素"11"前插入元素"00"
print(r.lrange("list2", 0, -1)) # 切片取出值,范围是索引号0-最后一个元素运行结果:
['77', '00', '11', '22', '33', '11', '22', '33', '99']
3.7 lset修改(指定索引号进行修改)
r.lset(name, index, value)
对name对应的list中的某一个索引位置重新赋值
参数:
name - redis的name
index - list的索引位置
value - 要设置的值
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lset("list2", 0, -11) # 把索引号是0的元素修改成-11
print(r.lrange("list2", 0, -1))运行结果:
['-11', '00', '11', '22', '33', '11', '22', '33', '99']
3.8 lset修改(指定索引号进行修改)
r.lset(name, index, value)
对name对应的list中的某一个索引位置重新赋值
参数:
name - redis的name
index - list的索引位置
value - 要设置的值
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lset("list2", 0, -11) # 把索引号是0的元素修改成-11
print(r.lrange("list2", 0, -1))运行结果(发现没成功,没找到原因):
['-11', '11', '-11', '00', '11', '22', '33', '11', '22', '33', '99']
3.9 lrem删除(指定值进行删除)
r.lrem(name, value, num)
在name对应的list中删除指定的值
参数:
name - redis的name
value - 要删除的值
num - num=0,删除列表中所有的指定值;
num=2 - 从前到后,删除2个, num=1,从前到后,删除左边第1个
num=-2 - 从后向前,删除2个
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lrem("list2", "11", 1) # 将列表中左边第一次出现的"11"删除
print(r.lrange("list2", 0, -1))
r.lrem("list2", "99", -1) # 将列表中右边第一次出现的"99"删除
print(r.lrange("list2", 0, -1))
r.lrem("list2", "22", 0) # 将列表中所有的"22"删除
print(r.lrange("list2", 0, -1))运行结果(发现没成功,没找到原因):
['-11', '11', '-11', '00', '11', '22', '33', '11', '22', '33', '99'] ['-11', '11', '-11', '00', '11', '22', '33', '11', '22', '33', '99'] ['-11', '11', '-11', '00', '11', '22', '33', '11', '22', '33', '99']
3.10 lpop删除并返回
r.lpop(name)
在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
更多:
rpop(name) 表示从右向左操作
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lrem("list2", "11", 1) # 将列表中左边第一次出现的"11"删除
print(r.lrange("list2", 0, -1))
r.lrem("list2", "99", -1) # 将列表中右边第一次出现的"99"删除
print(r.lrange("list2", 0, -1))
r.lrem("list2", "22", 0) # 将列表中所有的"22"删除
print(r.lrange("list2", 0, -1))运行结果:
['11', '-11', '00', '11', '22', '33', '11', '22', '33', '99'] ['11', '-11', '00', '11', '22', '33', '11', '22', '33']
3.11 ltrim删除索引之外的值
ltrim(name, start, end)
在name对应的列表中移除没有在start-end索引之间的值
参数:
name - redis的name
start - 索引的起始位置
end - 索引结束位置
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.lrange("list2", 0, -1))
r.ltrim("list2", 0, 2) # 删除索引号是0-2之外的元素,值保留索引号是0-2的元素
print(r.lrange("list2", 0, -1))运行结果:
['11', '-11', '00', '11', '22', '33', '11', '22', '33'] ['11', '-11', '00']
3.12 lindex取值(根据索引号取值)
lindex(name, index)
在name对应的列表中根据索引获取列表元素
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.lrange("list2", 0, -1))
print(r.lindex("list2", 0)) # 取出索引号是0的值运行结果:
['11', '-11', '00'] 11
3.13 rpoplpush移动 元素从一个列表移动到另外一个列表
rpoplpush(src, dst)
从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
src - 要取数据的列表的 name
dst - 要添加数据的列表的 name
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.lrange("list1", 0, -1))
print(r.lrange("list2", 0, -1))
r.rpoplpush("list1", "list2")
print(r.lrange("list2", 0, -1))运行结果:
['33', '22', '11'] ['11', '-11', '00'] ['11', '11', '-11', '00']
3.14 brpoplpush移动 元素从一个列表移动到另外一个列表 可以设置超时
brpoplpush(src, dst, timeout=0)
从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
src - 取出并要移除元素的列表对应的name
dst - 要插入元素的列表对应的name
timeout - 当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.lrange("list1", 0, -1))
print(r.lrange("list2", 0, -1))
r.brpoplpush("list1", "list2", timeout=2)
print(r.lrange("list2", 0, -1))运行结果:
['33', '22'] ['11', '11', '-11', '00'] ['22', '11', '11', '-11', '00']
3.15 blpop一次移除多个列表
blpop(keys, timeout)
将多个列表排列,按照从左到右去pop对应列表的元素
参数:
keys - redis的name的集合
timeout - 超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
更多:
r.brpop(keys, timeout) 同 blpop,将多个列表排列,按照从右像左去移除各个列表内的元素
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.lpush("list10", 3, 4, 5)
r.lpush("list11", 3, 4, 5)
while True:
r.blpop(["list10", "list11"], timeout=2)
print(r.lrange("list10", 0, -1), r.lrange("list11", 0, -1))运行结果:
['4', '3'] ['5', '4', '3'] ['3'] ['5', '4', '3'] [] ['5', '4', '3'] [] ['4', '3'] [] ['3'] [] [] [] [] [] [] [] [] [] [] [] [] [] [] [] [] [] []
3.16 自定义增量迭代:
由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要获取name对应的所有列表。
循环列表
但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.lrange("list2", 0, -1))
def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in range(list_count):
yield r.lindex(name, index)
# 使用
for item in list_iter('list2'): # 遍历这个列表
print(item)运行结果:
['22', '11', '11', '-11', '00'] 22 11 11 -11 00
4)set
4.1 sadd新增
sadd(name,values)
name - 对应的集合中添加元素
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.sadd("set1", 33, 44, 55, 66) # 往集合中添加元素
print(r.scard("set1")) # 集合的长度是4
print(r.smembers("set1")) # 获取集合中所有的成员运行结果:
4
{'66', '55', '44', '33'}4.2 scard.获取元素个数 类似于len
scard(name)
获取name对应的集合中元素个数
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.smembers("set1")) # 获取集合中所有的成员
print(r.scard("set1")) # 集合的长度是4运行结果:
{'55', '66', '33', '44'}
44.3 smembets获取集合中所有的成员
smembers(name)
获取name对应的集合的所有成员
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.smembers("set1")) # 获取集合中所有的成员
sscan(name, cursor=0, match=None, count=None)运行结果:
{'55', '66', '33', '44'}4.4 sscan获取集合中所有的成员--元组形式
sscan(name, cursor=0, match=None, count=None)
获取集合中所有的成员--元组形式
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.sscan("set1"))运行结果:
(0, ['33', '44', '55', '66'])
4.5 sscan_iter获取集合中所有的成员--迭代器的方式
sscan_iter(name, match=None, count=None)
获取集合中所有的成员--迭代器的方式
同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.sscan("set1"))运行结果:
33 44 55 66
4.6 sdiff差集
sdiff(keys, *args)
在第一个name对应的集合中且不在其他name对应的集合的元素集合
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.sadd("set2", 11, 22, 33)
print(r.smembers("set1")) # 获取集合中所有的成员
print(r.smembers("set2"))
print(r.sdiff("set1", "set2")) # 在集合set1但是不在集合set2中
print(r.sdiff("set2", "set1")) # 在集合set2但是不在集合set1中运行结果:
{'55', '33', '66', '44'}
{'22', '33', '11'}
{'55', '66', '44'}
{'22', '11'}4.6 sdiffstore差集--差集存在一个新的集合中
sdiffstore(dest, keys, *args)
获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.sdiffstore("set3", "set1", "set2") # 在集合set1但是不在集合set2中
print(r.smembers("set3"))运行结果:
{'55', '44', '66'}4.7 sinter交集
sinter(keys, *args)
获取多一个name对应集合的交集
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.sinter("set1", "set2")) # 取2个集合的交集运行结果:
{'33'}4.8 sunion并集
sunion(keys, *args)
获取多个name对应的集合的并集
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.sunion("set1", "set2")) # 取2个集合的并集运行结果:
{'66', '33', '44', '11', '22', '55'}4.9 sunionstore并集--并集存在一个新的集合
sunionstore(dest,keys, *args)
获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.sunionstore("set3", "set1", "set2")) # 取2个集合的并集
print(r.smembers("set3"))运行结果:
6
{'33', '66', '55', '22', '11', '44'}4.10 sismember判断是否是集合的成员 类似in
sismember(name, value)
检查value是否是name对应的集合的成员,结果为True和False
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.sismember("set1", 33)) # 33是集合的成员
print(r.sismember("set1", 23)) # 23不是集合的成员运行结果:
True False
4.11 smove移动
smove(src, dst, value)
将某个成员从一个集合中移动到另外一个集合
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.smove("set1", "set2", 44)
print(r.smembers("set1"))
print(r.smembers("set2"))运行结果:
{'66', '55', '33'}
{'44', '33', '22', '11'}4.11 spop删除--随机删除并且返回被删除值
spop(name)
从集合移除一个成员,并将其返回,说明一下,集合是无序的,所有是随机删除的
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.spop("set2")) # 这个删除的值是随机删除的,集合是无序的
print(r.smembers("set2"))运行结果:
44
{'11', '22', '33'}4.12 srem删除--指定值删除
srem(name, values)
在name对应的集合中删除某些值
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.srem("set2", 11)) # 从集合中删除指定值 11
print(r.smembers("set2"))运行结果:
1
{'22', '33'}5)有序set
Set操作,Set集合就是不允许重复的列表,本身是无序的。
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
5.1 新增
zadd(name, mapping, nx=False, xx=False, ch=False, incr=False)
在name对应的有序集合中添加元素
如:
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.zadd("zset1", {'n1':100, 'n2':99, 'n3':87})
r.zadd("zset2", {'m1':100, 'm2':99, 'm3':87})
print(r.zcard("zset1")) # 集合长度
print(r.zcard("zset2")) # 集合长度
print(r.zrange("zset1", 0, -1)) # 获取有序集合中所有元素
print(r.zrange("zset2", 0, -1, withscores=True)) # 获取有序集合中所有元素和分数运行结果:
3 3 ['n3', 'n2', 'n1'] [('m3', 87.0), ('m2', 99.0), ('m1', 100.0)]
5.2 zcard获取有序集合元素个数 类似于len
zcard(name)
获取name对应的有序集合元素的数量
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zcard("zset1")) # 集合长度运行结果:
3
5.3 zrange获取有序集合的所有元素
zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
按照索引范围获取name对应的有序集合的元素
参数:
name - redis的name
start - 有序集合索引起始位置(非分数)
end - 有序集合索引结束位置(非分数)
desc - 排序规则,默认按照分数从小到大排序
withscores - 是否获取元素的分数,默认只获取元素的值
score_cast_func - 对分数进行数据转换的函数
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zrange("zset1", 0, 1)) # 集合长度运行结果:
['n3', 'n2']
5.3 zrevrange从大到小排序(同zrange,集合是从大到小排序的)
zrevrange(name, start, end, withscores=False, score_cast_func=float)
从大到小排序(同zrange,集合是从大到小排序的)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zrevrange("zset1", 0, -1)) # 只获取元素,不显示分数
print(r.zrevrange("zset1", 0, -1, withscores=True)) # 获取有序集合中所有元素和分数,分数倒序运行结果:
['n1', 'n2', 'n3'] [('n1', 100.0), ('n2', 99.0), ('n3', 87.0)]
5.4 zrangebyscore按照分数范围获取name对应的有序集合的元素
zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
按照分数范围获取name对应的有序集合的元素
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
for i in range(1, 30):
element = 'n' + str(i)
r.zadd("zset3", {element: i})
print(r.zrangebyscore("zset3", 15, 25)) # # 在分数是15-25之间,取出符合条件的元素
print(r.zrangebyscore("zset3", 12, 22, withscores=True)) # 在分数是12-22之间,取出符合条件的元素(带分数)运行结果:
['n15', 'n16', 'n17', 'n18', 'n19', 'n20', 'n21', 'n22', 'n23', 'n24', 'n25'] [('n12', 12.0), ('n13', 13.0), ('n14', 14.0), ('n15', 15.0), ('n16', 16.0), ('n17', 17.0), ('n18', 18.0), ('n19', 19.0), ('n20', 20.0), ('n21', 21.0), ('n22', 22.0)]
5.5 zrevrangebyscore按照分数范围获取有序集合的元素并排序(默认从大到小排序)
zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
按照分数范围获取有序集合的元素并排序(默认从大到小排序)
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zrevrangebyscore("zset3", 22, 11, withscores=True)) # 在分数是22-11之间,取出符合条件的元素 按照运行结果:
[('n22', 22.0), ('n21', 21.0), ('n20', 20.0), ('n19', 19.0), ('n18', 18.0), ('n17', 17.0), ('n16', 16.0), ('n15', 15.0), ('n14', 14.0), ('n13', 13.0), ('n12', 12.0), ('n11', 11.0)]
5.6 zscan获取所有元素--默认按照分数顺序排序
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
获取所有元素--默认按照分数顺序排序
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zscan("zset3"))运行结果:
(0, [('n1', 1.0), ('n2', 2.0), ('n3', 3.0), ('n4', 4.0), ('n5', 5.0), ('n6', 6.0), ('n7', 7.0), ('n8', 8.0), ('n9', 9.0), ('n10', 10.0), ('n11', 11.0), ('n12', 12.0), ('n13', 13.0), ('n14', 14.0), ('n15', 15.0), ('n16', 16.0), ('n17', 17.0), ('n18', 18.0), ('n19', 19.0), ('n20', 20.0), ('n21', 21.0), ('n22', 22.0), ('n23', 23.0), ('n24', 24.0), ('n25', 25.0), ('n26', 26.0), ('n27', 27.0), ('n28', 28.0), ('n29', 29.0)])
5.7 zscan_iter获取所有元素--迭代器
zscan_iter(name, match=None, count=None,score_cast_func=float)
获取所有元素--迭代器
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zscan("zset3"))运行结果:
('n1', 1.0) ('n2', 2.0) ('n3', 3.0) ('n4', 4.0) ('n5', 5.0) ('n6', 6.0) ('n7', 7.0) ('n8', 8.0) ('n9', 9.0) ('n10', 10.0) ('n11', 11.0) ('n12', 12.0) ('n13', 13.0) ('n14', 14.0) ('n15', 15.0) ('n16', 16.0) ('n17', 17.0) ('n18', 18.0) ('n19', 19.0) ('n20', 20.0) ('n21', 21.0) ('n22', 22.0) ('n23', 23.0) ('n24', 24.0) ('n25', 25.0) ('n26', 26.0) ('n27', 27.0) ('n28', 28.0) ('n29', 29.0)
5.8 zcount获取name对应的有序集合中分数 在 [min,max] 之间的个数
zcount(name, min, max)
获取name对应的有序集合中分数 在 [min,max] 之间的个数
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zrange("zset3", 0, -1, withscores=True))
print(r.zcount("zset3", 11, 22))运行结果:
[('n1', 1.0), ('n2', 2.0), ('n3', 3.0), ('n4', 4.0), ('n5', 5.0), ('n6', 6.0), ('n7', 7.0), ('n8', 8.0), ('n9', 9.0), ('n10', 10.0), ('n11', 11.0), ('n12', 12.0), ('n13', 13.0), ('n14', 14.0), ('n15', 15.0), ('n16', 16.0), ('n17', 17.0), ('n18', 18.0), ('n19', 19.0), ('n20', 20.0), ('n21', 21.0), ('n22', 22.0), ('n23', 23.0), ('n24', 24.0), ('n25', 25.0), ('n26', 26.0), ('n27', 27.0), ('n28', 28.0), ('n29', 29.0)] 12
5.9 zincrby自增
zincrby(name, amount, value)
自增name对应的有序集合的 name 对应的分数
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.zincrby("zset3", 2, "n2") # 每次将n2的分数自增2
print(r.zrange("zset3", 0, -1, withscores=True))运行结果:
[('n1', 1.0), ('n3', 3.0), ('n2', 4.0), ('n4', 4.0), ('n5', 5.0), ('n6', 6.0), ('n7', 7.0), ('n8', 8.0), ('n9', 9.0), ('n10', 10.0), ('n11', 11.0), ('n12', 12.0), ('n13', 13.0), ('n14', 14.0), ('n15', 15.0), ('n16', 16.0), ('n17', 17.0), ('n18', 18.0), ('n19', 19.0), ('n20', 20.0), ('n21', 21.0), ('n22', 22.0), ('n23', 23.0), ('n24', 24.0), ('n25', 25.0), ('n26', 26.0), ('n27', 27.0), ('n28', 28.0), ('n29', 29.0)]
5.10 zrank获取值的索引号
zrank(name, value)
获取某个值在 name对应的有序集合中的索引(从 0 开始)
更多:
zrevrank(name, value),从大到小排序
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zrank("zset3", "n1")) # n1的索引号是0 这里按照分数顺序(从小到大)
print(r.zrank("zset3", "n6")) # n6的索引号是1
print(r.zrevrank("zset3", "n1")) # n1的索引号是29 这里安照分数倒序(从大到小)运行结果:
0 5 28
5.11 zrem删除--指定值删除
zrem(name, values)
删除name对应的有序集合中值是values的成员
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.zrem("zset3", "n3") # 删除有序集合中的元素n3 删除单个
print(r.zrange("zset3", 0, -1))运行结果:
['n1', 'n2', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14', 'n15', 'n16', 'n17', 'n18', 'n19', 'n20', 'n21', 'n22', 'n23', 'n24', 'n25', 'n26', 'n27', 'n28', 'n29']
5.12 zremrangebyrank删除--根据排行范围删除,按照索引号来删除
zremrangebyrank(name, min, max)
根据排行范围删除
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.zremrangebyrank("zset3", 0, 1) # 删除有序集合中的索引号是0, 1的元素
print(r.zrange("zset3", 0, -1))运行结果:
['n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14', 'n15', 'n16', 'n17', 'n18', 'n19', 'n20', 'n21', 'n22', 'n23', 'n24', 'n25', 'n26', 'n27', 'n28', 'n29']
5.13 zremrangebyscore删除--根据分数范围删除
zremrangebyscore(name, min, max)
根据排行范围删除--根据分数范围删除
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.zremrangebyscore("zset3", 11, 22) # 删除有序集合中的分数是11-22的元素
print(r.zrange("zset3", 0, -1))运行结果:
['n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n23', 'n24', 'n25', 'n26', 'n27', 'n28', 'n29']
5.14 zscore获取值对应的分数
zscore(name, value)
获取name对应有序集合中 value 对应的分数
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.zscore("zset3", "n27")) # 获取元素n27对应的分数27运行结果:
27.0
五、其他常用操作
1.删除
delete(*names)
根据删除redis中的任意数据类型(string、hash、list、set、有序set)
r.delete("gender") # 删除key为gender的键值对2.检查名字是否存在
exists(name)
检测redis的name是否存在,存在就是True,False 不存在
print(r.exists("zset1"))3.模糊匹配
keys(pattern='')
根据模型获取redis的name
更多:
KEYS * 匹配数据库中所有 key 。
KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
KEYS hllo 匹配 hllo 和 heeeeello 等。
KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
print(r.keys("foo*"))4.设置超时时间
expire(name ,time)
为某个redis的某个name设置超时时间
r.lpush("list5", 11, 22)
r.expire("list5", time=3)
print(r.lrange("list5", 0, -1))
time.sleep(3)
print(r.lrange("list5", 0, -1))5.重命名
rename(src, dst)
对redis的name重命名
r.lpush("list5", 11, 22)
r.rename("list5", "list5-1")6.随机获取name
randomkey()
随机获取一个redis的name(不删除)
print(r.randomkey())
7.获取类型
type(name)
获取name对应值的类型
print(r.type("set1"))
print(r.type("hash2"))8.查看所有元素
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.scan(cursor=0, match=None, count=None)
print(r.hscan("hash2"))
print(r.sscan("set3"))
print(r.zscan("zset2"))
print(r.getrange("foo1", 0, -1))
print(r.lrange("list2", 0, -1))
print(r.smembers("set3"))
print(r.zrange("zset3", 0, -1))
print(r.hgetall("hash1"))运行结果:
(0, {'k2': 'v2', 'k3': 'v3'})
(0, ['11', '22', '33', '44', '55', '66'])
(0, [('m3', 87.0), ('m2', 99.0), ('m1', 100.0)])
123haha
['22', '11', '11', '-11', '00']
{'66', '55', '11', '44', '22', '33'}
['n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n23', 'n24', 'n25', 'n26', 'n27', 'n28', 'n29']
{'k2': 'v222', 'k11': 'v1', 'k3': '122', 'k4': '1'}9.查看所有元素--迭代器
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
r.scan_iter(match=None, count=None)
for i in r.hscan_iter("hash1"):
print(i)
for i in r.sscan_iter("set3"):
print(i)
for i in r.zscan_iter("zset3"):
print(i)运行结果:
('k2', 'v222') ('k11', 'v1') ('k3', '122') ('k4', '1') 11 22 33 44 55 66 ('n4', 4.0) ('n5', 5.0) ('n6', 6.0) ('n7', 7.0) ('n8', 8.0) ('n9', 9.0) ('n10', 10.0) ('n23', 23.0) ('n24', 24.0) ('n25', 25.0) ('n26', 26.0) ('n27', 27.0) ('n28', 28.0) ('n29', 29.0)
六、other方法
import redis
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
print(r.get('name')) # 查询key为name的值
r.delete("gender") # 删除key为gender的键值对
print(r.keys()) # 查询所有的Key
print(r.dbsize()) # 当前redis包含多少条数据
r.save() # 执行"检查点"操作,将数据写回磁盘。保存时阻塞
# r.flushdb() # 清空r中的所有数据运行结果:
None ['set2', 'k2', 'food', 'visit:12306:totals', 'foo', 'foono', 'set3', 'list2', 'cn_name', 'foo2', 'n3', 'foo1', 'new_name', 'too', 'zset1', 'list1', 'set1', 'hash1', 'zset2', 'n1', 'hash2', 'foo4', 'n2', 'en_name', 'k1', 'zset3', 'foo1s'] 27
七、管道(pipeline)
redis默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
管道(pipeline)是redis在提供单个请求中缓冲多条服务器命令的基类的子类。它通过减少服务器-客户端之间反复的TCP数据库包,从而大大提高了执行批量命令的功能。
import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False) # 默认的情况下,管道里执行的命令可以保证执行的原子性,执行pipe = r.pipeline(transaction=False)可以禁用这一特性。
# pipe = r.pipeline(transaction=True)
pipe = r.pipeline() # 创建一个管道
pipe.set('name', 'jack')
pipe.set('role', 'sb')
pipe.sadd('faz', 'baz')
pipe.incr('num') # 如果num不存在则vaule为1,如果存在,则value自增1
pipe.execute()
print(r.get("name"))
print(r.get("role"))
print(r.get("num"))运行结果:
jack sb 1
管道的命令可以写在一起,如:
import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
pipe = r.pipeline() # 创建一个管道
pipe.set('hello', 'redis').sadd('faz', 'baz').incr('num').execute()
print(r.get("name"))
print(r.get("role"))
print(r.get("num"))运行结果:
jack sb 1
The above is the detailed content of Python operation redis instance analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download DeepSeek Xiaomi? Search for "DeepSeek" in the Xiaomi App Store. If it is not found, continue to step 2. Identify your needs (search files, data analysis), and find the corresponding tools (such as file managers, data analysis software) that include DeepSeek functions.
 How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
The key to using DeepSeek effectively is to ask questions clearly: express the questions directly and specifically. Provide specific details and background information. For complex inquiries, multiple angles and refute opinions are included. Focus on specific aspects, such as performance bottlenecks in code. Keep a critical thinking about the answers you get and make judgments based on your expertise.
 How to search deepseek
Feb 19, 2025 pm 05:18 PM
How to search deepseek
Feb 19, 2025 pm 05:18 PM
Just use the search function that comes with DeepSeek. Its powerful semantic analysis algorithm can accurately understand the search intention and provide relevant information. However, for searches that are unpopular, latest information or problems that need to be considered, it is necessary to adjust keywords or use more specific descriptions, combine them with other real-time information sources, and understand that DeepSeek is just a tool that requires active, clear and refined search strategies.
 How to program deepseek
Feb 19, 2025 pm 05:36 PM
How to program deepseek
Feb 19, 2025 pm 05:36 PM
DeepSeek is not a programming language, but a deep search concept. Implementing DeepSeek requires selection based on existing languages. For different application scenarios, it is necessary to choose the appropriate language and algorithms, and combine machine learning technology. Code quality, maintainability, and testing are crucial. Only by choosing the right programming language, algorithms and tools according to your needs and writing high-quality code can DeepSeek be successfully implemented.
 How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
Question: Is DeepSeek available for accounting? Answer: No, it is a data mining and analysis tool that can be used to analyze financial data, but it does not have the accounting record and report generation functions of accounting software. Using DeepSeek to analyze financial data requires writing code to process data with knowledge of data structures, algorithms, and DeepSeek APIs to consider potential problems (e.g. programming knowledge, learning curves, data quality)
 Which country is the Nexo exchange from? Where is it? A comprehensive introduction to the Nexo exchange
Mar 05, 2025 pm 05:09 PM
Which country is the Nexo exchange from? Where is it? A comprehensive introduction to the Nexo exchange
Mar 05, 2025 pm 05:09 PM
Nexo Exchange: Swiss cryptocurrency lending platform In-depth analysis Nexo is a platform that provides cryptocurrency lending services, supporting the mortgage and lending of more than 40 crypto assets, fiat currencies and stablecoins. It dominates the European and American markets and is committed to improving the efficiency, security and compliance of the platform. Many investors want to know where the Nexo exchange is registered, and the answer is: Switzerland. Nexo was founded in 2018 by Swiss fintech company Credissimo. Nexo Exchange Geographical Location and Regulation: Nexo is headquartered in Zug, Switzerland, a well-known cryptocurrency-friendly region. The platform actively cooperates with the supervision of various governments and has been in the US Financial Crime Law Enforcement Network (FinCEN) and Canadian Finance
 How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
Detailed explanation of DeepSeekAPI access and call: Quick Start Guide This article will guide you in detail how to access and call DeepSeekAPI, helping you easily use powerful AI models. Step 1: Get the API key to access the DeepSeek official website and click on the "Open Platform" in the upper right corner. You will get a certain number of free tokens (used to measure API usage). In the menu on the left, click "APIKeys" and then click "Create APIkey". Name your APIkey (for example, "test") and copy the generated key right away. Be sure to save this key properly, as it will only be displayed once
 Monitoring Redis Droplets Using Redis Exporter Service
Jan 06, 2025 am 10:19 AM
Monitoring Redis Droplets Using Redis Exporter Service
Jan 06, 2025 am 10:19 AM
Effective monitoring of Redis databases is essential for maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a robust utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you establish a monitoring solution seamlessly. By following this tutorial, you’ll achieve a fully operational monitoring setup to effectively monitor the performance metrics of your Redis database.
