
 Technology peripherals
AI
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
Technology peripherals
AI
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL

Deep learning models for visual tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images).
Generally, an application that completes visual tasks for multiple fields needs to build multiple models for each separate field and train them independently, without sharing data between different fields. , at inference time, each model will process domain-specific input data.
Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL).
In addition, MDL models can also be better than single-domain models. Additional training in one domain can improve the performance of the model in another domain. This is called "forward knowledge." Transfer", but may also produce negative knowledge transfer, depending on the training method and specific domain combination. Although previous work on MDL has demonstrated the effectiveness of cross-domain joint learning tasks, it involves a hand-crafted model architecture that is inefficient when applied to other tasks.

Paper link: https://arxiv.org/pdf/2010.04904.pdf
In order to solve this problem, in the article "Multi-path Neural Networks for On-device Multi-domain Visual Classification", Google researchers proposed a general MDL model.
The article states that this model can effectively achieve high accuracy, reduce negative knowledge transfer, and learn to enhance positive knowledge transfer, and can handle difficulties in various specific fields. When , the joint model can be effectively optimized.
To this end, the researchers proposed a multi-path neural architecture search (MPNAS) method to establish A unified model with heterogeneous network architectures.
This method extends the efficient neural structure search (NAS) method from single-path search to multi-path search to jointly find an optimal path for each field. A new loss function is also introduced, called Adaptive Balanced Domain Prioritization (ABDP), which adapts to domain-specific difficulties to help train models efficiently. The resulting MPNAS method is efficient and scalable.
The new model reduces model size and FLOPS by 78% and 32% respectively compared with single-domain methods while maintaining performance without degradation.
Multi-path neural structure search
In order to promote positive knowledge transfer and avoid negative transfer, the traditional solution is to establish an MDL model so that all domains can share it Most of the layers learn the shared features of each domain (called feature extraction), and then build some domain-specific layers on top. However, this feature extraction method cannot handle domains with significantly different characteristics (such as objects in natural images and artistic paintings). On the other hand, building a unified heterogeneous structure for each MDL model is time-consuming and requires domain-specific knowledge.
Multi-path neural search architecture framework NAS is a powerful paradigm for automatically designing deep learning architectures . It defines a search space consisting of various potential building blocks that may become part of the final model.
The search algorithm finds the best candidate architecture from the search space to optimize model goals, such as classification accuracy. Recent NAS methods, such as TuNAS, improve search efficiency by using end-to-end path sampling.
Inspired by TuNAS, MPNAS established an MDL model architecture in two stages: search and training.
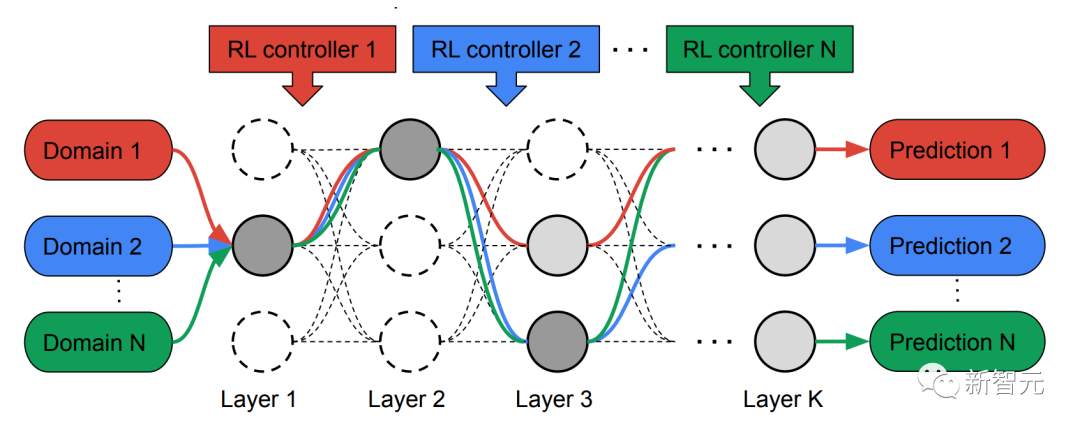
In the search phase, in order to jointly find an optimal path for each domain, MPNAS creates a separate reinforcement learning (RL) controller for each domain, which starts from the super network (i.e., defined by the search space Sample end-to-end paths (from the input layer to the output layer) from a superset of all possible subnetworks between candidate nodes.
Over multiple iterations, all RL controllers update paths to optimize RL rewards in all areas. At the end of the search phase, we obtain a subnetwork for each domain. Finally, all sub-networks are combined to create a heterogeneous structure for the MDL model, as shown in the figure below.
Since the subnetwork of each domain is searched independently, the Components can be shared by multiple domains (i.e. dark gray nodes), used by a single domain (i.e. light gray nodes), or not used by any subnetwork (i.e. point nodes).
The path of each domain can also skip any layer during the search process. The output network is both heterogeneous and efficient, given that subnetworks are free to choose which blocks to use along the way in a way that optimizes performance.
The following figure shows the search architecture of two areas of Visual Domain Decathlon.
Visual Domain Decathlon was tested as part of the PASCAL in Detail Workshop Challenge at CVPR 2017 Improves the ability of visual recognition algorithms to process (or exploit) many different visual domains. As can be seen, the subnetworks of these two highly related domains (one red, the other green) share most of the building blocks from their overlapping paths, but there are still differences between them.
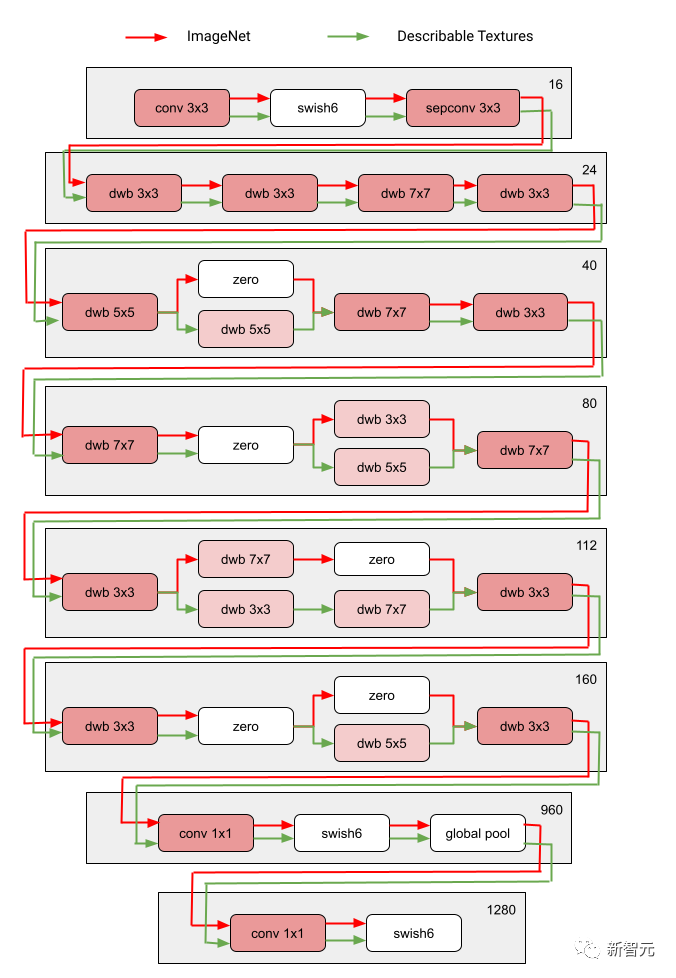
The red and green paths in the figure represent the subnetworks of ImageNet and Describable Textures respectively, and the dark pink nodes represent blocks shared by multiple domains. , light pink nodes represent the blocks used by each path. The "dwb" block in the diagram represents the dwbottleneck block. The Zero block in the figure indicates that the subnet skips the block The figure below shows the path similarity in the two areas mentioned above. Similarity is measured by the Jaccard similarity score between subnets for each domain, where higher means more similar paths.

The picture shows the confusion matrix of Jaccard similarity scores between paths in ten domains. The score ranges from 0 to 1. The larger the score, the more nodes the two paths share.
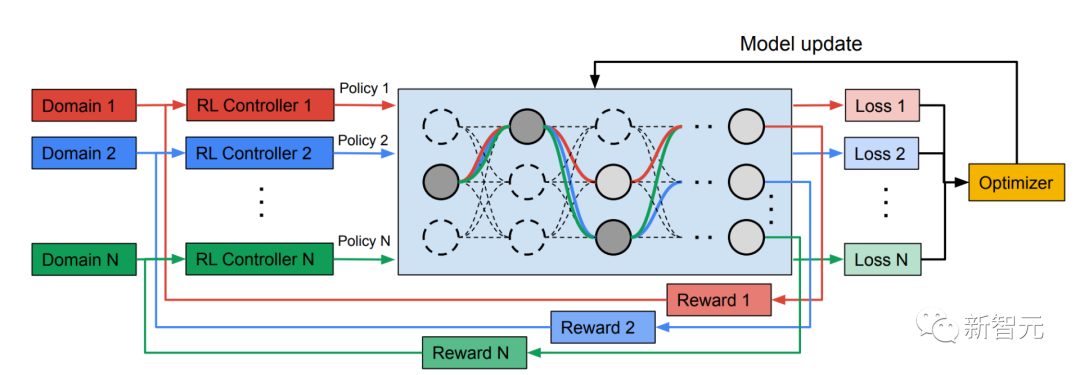
Training heterogeneous multi-domain models
In the second phase, the models produced by MPNAS will be trained from scratch for all domains. To do this, it is necessary to define a unified objective function for all domains. To successfully handle a wide variety of domains, the researchers designed an algorithm that adjusts throughout the learning process to balance losses across domains, called Adaptive Balanced Domain Prioritization (ABDP). Below shows the accuracy, model size and FLOPS of models trained under different settings. We compare MPNAS with three other methods:
Domain-independent NAS: models are searched and trained separately for each domain.
Single path multi-head: Use a pre-trained model as a shared backbone for all domains, with separate classification heads for each domain.
Multi-head NAS: Search a unified backbone architecture for all domains, with separate classification heads for each domain.
From the results, we can observe that NAS requires building a set of models for each domain, resulting in large models. Although single-path multi-head and multi-head NAS can significantly reduce model size and FLOPS, forcing domains to share the same backbone introduces negative knowledge transfer, thereby reducing overall accuracy.

In contrast, MPNAS can build small and efficient models while still maintaining high overall accuracy. The average accuracy of MPNAS is even 1.9% higher than the domain-independent NAS method because the model is able to achieve active knowledge transfer. The figure below compares the top-1 accuracy per domain of these methods.
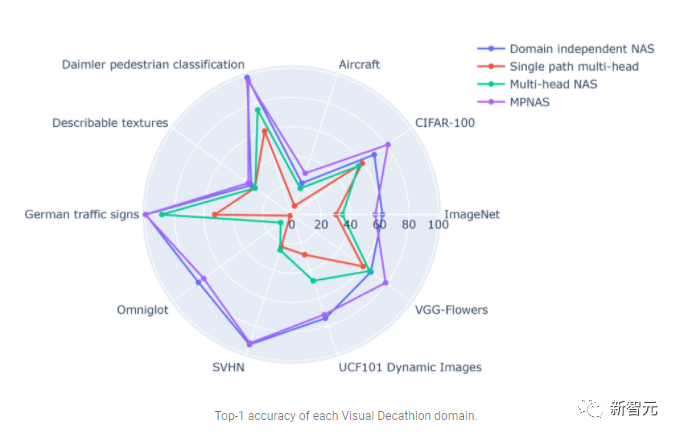
Evaluation shows that by using ABDP as part of the search and training stages, top-1 The accuracy increased from 69.96% to 71.78% (increment: 1.81%).
Future Direction
MPNAS is to build a heterogeneous network to solve the data imbalance, domain diversity, negative migration, domain availability of possible parameter sharing strategies in MDL Efficient solution for scalability and large search space. By using a MobileNet-like search space, the generated model is also mobile-friendly. For tasks that are incompatible with existing search algorithms, researchers are continuing to extend MPNAS for multi-task learning and hope to use MPNAS to build unified multi-domain models.
The above is the detailed content of Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1375
1375
 52
52

 YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
YOLO is immortal! YOLOv9 is released: performance and speed SOTA~
Feb 26, 2024 am 11:31 AM
Today's deep learning methods focus on designing the most suitable objective function so that the model's prediction results are closest to the actual situation. At the same time, a suitable architecture must be designed to obtain sufficient information for prediction. Existing methods ignore the fact that when the input data undergoes layer-by-layer feature extraction and spatial transformation, a large amount of information will be lost. This article will delve into important issues when transmitting data through deep networks, namely information bottlenecks and reversible functions. Based on this, the concept of programmable gradient information (PGI) is proposed to cope with the various changes required by deep networks to achieve multi-objectives. PGI can provide complete input information for the target task to calculate the objective function, thereby obtaining reliable gradient information to update network weights. In addition, a new lightweight network framework is designed
 This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
Some time ago, a tweet pointing out the inconsistency between the Transformer architecture diagram and the code in the Google Brain team's paper "AttentionIsAllYouNeed" triggered a lot of discussion. Some people think that Sebastian's discovery was an unintentional mistake, but it is also surprising. After all, considering the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times. Sebastian Raschka said in response to netizen comments that the "most original" code was indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified, but the architecture diagram was not updated at the same time. This is also the root cause of "inconsistent" discussions.
 Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Multi-path, multi-domain, all-inclusive! Google AI releases multi-domain learning general model MDL
May 28, 2023 pm 02:12 PM
Deep learning models for vision tasks (such as image classification) are usually trained end-to-end with data from a single visual domain (such as natural images or computer-generated images). Generally, an application that completes vision tasks for multiple domains needs to build multiple models for each separate domain and train them independently. Data is not shared between different domains. During inference, each model will handle a specific domain. input data. Even if they are oriented to different fields, some features of the early layers between these models are similar, so joint training of these models is more efficient. This reduces latency and power consumption, and reduces the memory cost of storing each model parameter. This approach is called multi-domain learning (MDL). In addition, MDL models can also outperform single
 What is the architecture and working principle of Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
What is the architecture and working principle of Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA is based on the JPA architecture and interacts with the database through mapping, ORM and transaction management. Its repository provides CRUD operations, and derived queries simplify database access. Additionally, it uses lazy loading to only retrieve data when necessary, thus improving performance.
 1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms takes 1.3ms! Tsinghua's latest open source mobile neural network architecture RepViT
Mar 11, 2024 pm 12:07 PM
Paper address: https://arxiv.org/abs/2307.09283 Code address: https://github.com/THU-MIG/RepViTRepViT performs well in the mobile ViT architecture and shows significant advantages. Next, we explore the contributions of this study. It is mentioned in the article that lightweight ViTs generally perform better than lightweight CNNs on visual tasks, mainly due to their multi-head self-attention module (MSHA) that allows the model to learn global representations. However, the architectural differences between lightweight ViTs and lightweight CNNs have not been fully studied. In this study, the authors integrated lightweight ViTs into the effective
 How steep is the learning curve of golang framework architecture?
Jun 05, 2024 pm 06:59 PM
How steep is the learning curve of golang framework architecture?
Jun 05, 2024 pm 06:59 PM
The learning curve of the Go framework architecture depends on familiarity with the Go language and back-end development and the complexity of the chosen framework: a good understanding of the basics of the Go language. It helps to have backend development experience. Frameworks that differ in complexity lead to differences in learning curves.
 Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
Do you know that programmers will be in decline in a few years?
Nov 08, 2023 am 11:17 AM
"ComputerWorld" magazine once wrote an article saying that "programming will disappear by 1960" because IBM developed a new language FORTRAN, which allows engineers to write the mathematical formulas they need and then submit them. Give the computer a run, so programming ends. A few years later, we heard a new saying: any business person can use business terms to describe their problems and tell the computer what to do. Using this programming language called COBOL, companies no longer need programmers. . Later, it is said that IBM developed a new programming language called RPG that allows employees to fill in forms and generate reports, so most of the company's programming needs can be completed through it.
 Exploring Siamese networks using contrastive loss for image similarity comparison
Apr 02, 2024 am 11:37 AM
Exploring Siamese networks using contrastive loss for image similarity comparison
Apr 02, 2024 am 11:37 AM
Introduction In the field of computer vision, accurately measuring image similarity is a critical task with a wide range of practical applications. From image search engines to facial recognition systems and content-based recommendation systems, the ability to effectively compare and find similar images is important. The Siamese network combined with contrastive loss provides a powerful framework for learning image similarity in a data-driven manner. In this blog post, we will dive into the details of Siamese networks, explore the concept of contrastive loss, and explore how these two components work together to create an effective image similarity model. First, the Siamese network consists of two identical subnetworks that share the same weights and parameters. Each sub-network encodes the input image into a feature vector, which
