func: The function that needs to operate on the iterable object must contain two parameters
When using func to operate on the iterable object When iterating objects to perform binocular operations, two parameters need to be provided. What is returned is an iterator. Similar to this method is the reduce under functools. Reduce and accumulate operate cumulatively. The difference is that reduce will only return the last element, while accumulate will display all elements, including the middle elements. The comparison is as follows:
| Difference |
reduce |
accumulate |
| Return value | Returns an element |
Returns an iterator (including intermediately processed elements) |
| The module it belongs to |
functools |
itertools |
| Performance |
Slightly worse |
Better than reduce |
##Initial value | The initial value can be set | The initial value can be set |
import time
from itertools import accumulate
from functools import reduce
l_data = [1, 2, 3, 4]
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(list(data))
start = time.time()
for i in range(100000):
data = accumulate(l_data, lambda x, y: x + y, initial=2)
print(time.time() - start)
start = time.time()
for i in range(100000):
data = reduce(lambda x, y: x + y, l_data)
print(time.time() - start)
#输出
[2, 3, 5, 8, 12]
0.027924537658691406
0.03989362716674805Copy after login
It can be seen from the above results that accumulate has slightly better performance than reduce, and it can also output the intermediate processing process.
chain(*iterables)
iterables: Receive multiple iterable objects
Return the elements of multiple iterable objects in turn, and return an iterator, for dictionary output element, the key of the dictionary will be output by default
from itertools import chain
import time
list_data = [1, 2, 3]
dict_data = {"a": 1, "b": 2}
set_data = {4, 5, 6}
print(list(chain(list_data, dict_data, set_data)))
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
start = time.time()
for i in range(100000):
chain(list_data, list_data2)
print(time.time() - start)
start = time.time()
for i in range(100000):
list_data.extend(list_data2)
print(time.time() - start)
#输出
[1, 2, 3, 'a', 'b', 4, 5, 6]
0.012955427169799805
0.013965129852294922Copy after login
combinations(iterable: Iterable, r)
iterable: the iterable object that needs to be operated
r: the extracted subsequence The number of elements
operates the iterable object and returns the subsequence according to the number of subsequences to be extracted. The elements in the subsequence are also ordered, non-repeatable and presented in the form of tuples.
from itertools import combinations
data = range(5)
print(tuple(combinations(data, 2)))
str_data = "asdfgh"
print(tuple(combinations(str_data, 2)))
#输出
((0, 1), (0, 2), (0, 3), (0, 4), (1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4))
(('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'g'), ('f', 'h'), ('g', 'h'))
Copy after login
combinations_with_replacement(iterable: Iterable, r)
is similar to the above combinations(iterable: Iterable, r), but the difference is that the elements of the subsequence of combinations_with_replacement can be repeated and are also ordered The details are as follows:
from itertools import combinations_with_replacement
data = range(5)
print(tuple(combinations_with_replacement(data, 2)))
str_data = "asdfgh"
print(tuple(combinations_with_replacement(str_data, 2)))
#输出
((0, 0), (0, 1), (0, 2), (0, 3), (0, 4), (1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4))
(('a', 'a'), ('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 's'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'd'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'f'), ('f', 'g'), ('f', 'h'), ('g', 'g'), ('g', 'h'), ('h', 'h'))
Copy after login
compress(data: Iterable, selectors: Iterable)
data: iterable object that needs to be operated
selectors: iterable to determine the true value Object, if it cannot be str, it is best to be a list, tuple, etc.
Output the element of the corresponding index in the data according to whether the element in the selectors is true, whichever is the shortest, and return an iterator .
from itertools import compress
data = "asdfg"
list_data = [1, 0, 0, 0, 1, 4]
print(list(compress(data, list_data)))
#输出
['a', 'g']
Copy after login
count(start, step)
start: The starting element
step: The step size of the growth element since the start
Generates an increasing iteration The starting point is start and the increment step is a given value. All elements will not be generated immediately. It is recommended to use the next() method to recursively obtain elements.
from itertools import count
c = count(start=10, step=20)
print(next(c))
print(next(c))
print(next(c))
print(next(c))
print(c)
#输出
10
30
50
70
count(90, 20)
Copy after login
cycle(iterable)
iterable: Iterable object that needs to be output by loop
Returns an iterator and loops out the elements of the iterable object. Like count, it is best not to convert the result into an iterable object. Because it is a loop, it is recommended to use next() or a for loop to obtain elements.
from itertools import cycle
a = "asdfg"
data = cycle(a)
print(next(data))
print(next(data))
print(next(data))
print(next(data))
#输出
a
s
d
f
Copy after login
dropwhile(predicate, iterable)
predicate: criterion for whether to drop elements
iterable: iterable object
By calculating the result of predicate Filter returns an iterator in which elements that evaluate to True are discarded. Regardless of whether the following element is True or False, it will be output when predicate is False.
from itertools import dropwhile
list_data = [1, 2, 3, 4, 5]
print(list(dropwhile(lambda i: i < 3, list_data)))
print(list(dropwhile(lambda x: x < 5, [1, 4, 6, 4, 1])))
#输出
[3, 4, 5]
[6, 4, 1]
Copy after login
filterfalse(predicate, iterable)
predicate: the criterion of whether to discard elements
iterable: iterable object
Generates an iterator. Before each element performs an operation, determine whether it satisfies the predicate condition. Similar to the filter method, but the opposite of filter.
import time
from itertools import filterfalse
print(list(filterfalse(lambda i: i % 2 == 0, range(10))))
start = time.time()
for i in range(100000):
filterfalse(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
start = time.time()
for i in range(100000):
filter(lambda i: i % 2 == 0, range(10))
print(time.time() - start)
#输出
[1, 3, 5, 7, 9]
0.276653528213501
0.2768676280975342Copy after login
It can be seen from the above results that the performance of filterfalse and filter are not much different
groupby(iterable, key=None)
iterable: Iterable object
key: Optional, the condition that needs to be judged on the element, the default is x == x.
Returns an iterator, returning consecutive keys and groups according to key (continuous elements that meet the key condition).
Note that you need to sort before using groupby to group.
from itertools import groupby
str_data = "babada"
for k, v in groupby(str_data):
print(k, list(v))
str_data = "aaabbbcd"
for k, v in groupby(str_data):
print(k, list(v))
def func(x: str):
print(x)
return x.isdigit()
str_data = "12a34d5"
for k, v in groupby(str_data, key=func):
print(k, list(v))
#输出
b ['b']
a ['a']
b ['b']
a ['a']
d ['d']
a ['a']
a ['a', 'a', 'a']
b ['b', 'b', 'b']
c ['c']
d ['d']
1
2
a
True ['1', '2']
3
False ['a']
4
d
True ['3', '4']
5
False ['d']
True ['5']Copy after login
islice(iterable, stop)\islice(iterable, start, stop[, step])
iterable: the iterable object that needs to be operated
start: start the operation The index position of
stop: the index position of the end operation
step: the step size
Returns an iterator. Similar to slicing, but its index does not support negative numbers.
from itertools import islice
import time
list_data = [1, 5, 4, 2, 7]
#学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
start = time.time()
for i in range(100000):
data = list_data[:2:]
print(time.time() - start)
start = time.time()
for i in range(100000):
data = islice(list_data, 2)
print(time.time() - start)
print(list(islice(list_data, 1, 3)))
print(list(islice(list_data, 1, 4, 2)))
#输出
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]
0.010963201522827148
0.01595783233642578
[5, 4]
[5, 2]Copy after login
It can be seen from the above results that slicing performance is slightly better than islice performance.
pairwise(iterable)
The iterable object that needs to be operated
Returns an iterator, which returns consecutive overlapping pairs in the iterable object. If there are less than two, it returns empty.
from itertools import pairwise
str_data = "asdfweffva"
list_data = [1, 2, 5, 76, 8]
print(list(pairwise(str_data)))
print(list(pairwise(list_data)))
#输出
[('a', 's'), ('s', 'd'), ('d', 'f'), ('f', 'w'), ('w', 'e'), ('e', 'f'), ('f', 'f'), ('f', 'v'), ('v', 'a')]
[(1, 2), (2, 5), (5, 76), (76, 8)]
Copy after login
permutations(iterable, r=None)
iterable: the iterable object that needs to be operated
r: the extracted subsequence
is similar to combinations , both extract subsequences of iterable objects. However, permutations are non-repeatable and unordered, just the opposite of combinations_with_replacement.
from itertools import permutations
data = range(5)
print(tuple(permutations(data, 2)))
str_data = "asdfgh"
print(tuple(permutations(str_data, 2)))
#输出
((0, 1), (0, 2), (0, 3), (0, 4), (1, 0), (1, 2), (1, 3), (1, 4), (2, 0), (2, 1), (2, 3), (2, 4), (3, 0), (3, 1), (3, 2), (3, 4), (4, 0), (4, 1), (4, 2), (4, 3))
(('a', 's'), ('a', 'd'), ('a', 'f'), ('a', 'g'), ('a', 'h'), ('s', 'a'), ('s', 'd'), ('s', 'f'), ('s', 'g'), ('s', 'h'), ('d', 'a'), ('d', 's'), ('d', 'f'), ('d', 'g'), ('d', 'h'), ('f', 'a'), ('f', 's'), ('f', 'd'), ('f', 'g'), ('f', 'h'), ('g', 'a'), ('g', 's'), ('g', 'd'), ('g', 'f'), ('g', 'h'), ('h', 'a'), ('h', 's'), ('h', 'd'), ('h', 'f'), ('h', 'g'))
Copy after login
product(*iterables, repeat=1)
iterables: iterable object, which can be multiple
repeat: the number of repetitions of the iterable object, that is, copying The number of times
Returns the iterator. Analogous permutations and combinations generate iterable objects of Cartesian products. Product function is similar to zip function, but while zip matches elements one-to-one, product creates a one-to-many relationship..
from itertools import product
list_data = [1, 2, 3]
list_data2 = [4, 5, 6]
print(list(product(list_data, list_data2)))
print(list(zip(list_data, list_data2)))
# 如下两个含义是一样的,都是将可迭代对象复制一份, 很方便的进行同列表的操作
print(list(product(list_data, repeat=2)))
print(list(product(list_data, list_data)))
# 同上述含义
print(list(product(list_data, list_data2, repeat=2)))
print(list(product(list_data, list_data2, list_data, list_data2)))
#输出
[(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]
[(1, 4), (2, 5), (3, 6)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
[(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
[(1, 4, 1, 4), (1, 4, 1, 5), (1, 4, 1, 6), (1, 4, 2, 4), (1, 4, 2, 5), (1, 4, 2, 6), (1, 4, 3, 4), (1, 4, 3, 5), (1, 4, 3, 6), (1, 5, 1, 4), (1, 5, 1, 5), (1, 5, 1, 6), (1, 5, 2, 4), (1, 5, 2, 5), (1, 5, 2, 6), (1, 5, 3, 4), (1, 5, 3, 5), (1, 5, 3, 6), (1, 6, 1, 4), (1, 6, 1, 5), (1, 6, 1, 6), (1, 6, 2, 4), (1, 6, 2, 5), (1, 6, 2, 6), (1, 6, 3, 4), (1, 6, 3, 5), (1, 6, 3, 6), (2, 4, 1, 4), (2, 4, 1, 5), (2, 4, 1, 6), (2, 4, 2, 4), (2, 4, 2, 5), (2, 4, 2, 6), (2, 4, 3, 4), (2, 4, 3, 5), (2, 4, 3, 6), (2, 5, 1, 4), (2, 5, 1, 5), (2, 5, 1, 6), (2, 5, 2, 4), (2, 5, 2, 5), (2, 5, 2, 6), (2, 5, 3, 4), (2, 5, 3, 5), (2, 5, 3, 6), (2, 6, 1, 4), (2, 6, 1, 5), (2, 6, 1, 6), (2, 6, 2, 4), (2, 6, 2, 5), (2, 6, 2, 6), (2, 6, 3, 4), (2, 6, 3, 5), (2, 6, 3, 6), (3, 4, 1, 4), (3, 4, 1, 5), (3, 4, 1, 6), (3, 4, 2, 4), (3, 4, 2, 5), (3, 4, 2, 6), (3, 4, 3, 4), (3, 4, 3, 5), (3, 4, 3, 6), (3, 5, 1, 4), (3, 5, 1, 5), (3, 5, 1, 6), (3, 5, 2, 4), (3, 5, 2, 5), (3, 5, 2, 6), (3, 5, 3, 4), (3, 5, 3, 5), (3, 5, 3, 6), (3, 6, 1, 4), (3, 6, 1, 5), (3, 6, 1, 6), (3, 6, 2, 4), (3, 6, 2, 5), (3, 6, 2, 6), (3, 6, 3, 4), (3, 6, 3, 5), (3, 6, 3, 6)]
Copy after login
repeat(object[, times])
object: any legal object
times: optional, the number of times the object object is generated, when times is not passed in, then Infinite loop
Returns an iterator, repeatedly generating object objects based on times.
from itertools import repeat
str_data = "assd"
print(repeat(str_data))
print(list(repeat(str_data, 4)))
list_data = [1, 2, 4]
print(repeat(list_data))
print(list(repeat(list_data, 4)))
dict_data = {"a": 1, "b": 2}
print(repeat(dict_data))
print(list(repeat(dict_data, 4)))
#输出
repeat('assd')
['assd', 'assd', 'assd', 'assd']
repeat([1, 2, 4])
[[1, 2, 4], [1, 2, 4], [1, 2, 4], [1, 2, 4]]
repeat({'a': 1, 'b': 2})
[{'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}, {'a': 1, 'b': 2}]Copy after login
starmap(function, iterable)
function: function of scope iterator object element
iterable: iterable object
Returns an iterator , apply the function to all elements of the iterable object (all elements must be iterable objects, even if there is only one value, they need to be wrapped with an iterable object, such as tuple (1, )), similar to the map function; when function When the parameters are consistent with the elements of the iterable object, use tuples instead of elements, such as pow(a, b), which corresponds to [(2,3), (3,3)].
The difference between map and starmap is that map usually operates when a function has only one parameter, while starmap can operate when a function has multiple parameters.
from itertools import starmap
list_data = [1, 2, 3, 4, 5]
list_data2 = [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]
list_data3 = [(1,), (2,), (3,), (4,), (5,)]
print(list(starmap(lambda x, y: x + y, list_data2)))
print(list(map(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data)))
print(list(starmap(lambda x: x * x, list_data3)))
#输出
[2, 4, 6, 8, 10]
[1, 4, 9, 16, 25]
Traceback (most recent call last):
File "c:\Users\ts\Desktop\2022.7\2022.7.22\test.py", line 65, in <module>
print(list(starmap(lambda x: x * x, list_data)))
TypeError: 'int' object is not iterableCopy after login
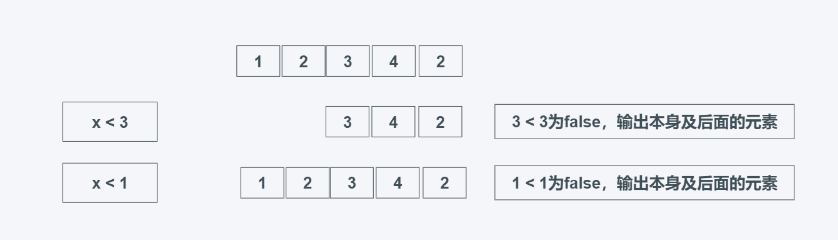
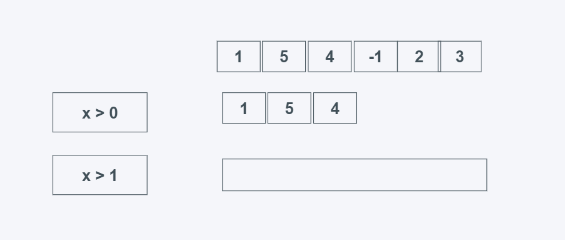
takewhile(predicate, iterable)
predicate:判断条件,为真就返回
iterable: 可迭代对象
当predicate为真时返回元素,需要注意的是,当第一个元素不为True时,则后面的无论结果如何都不会返回,找的前多少个为True的元素。
from itertools import takewhile
#学习中遇到问题没人解答?小编创建了一个Python学习交流群:725638078
list_data = [1, 5, 4, 6, 2, 3]
print(list(takewhile(lambda x: x > 0, list_data)))
print(list(takewhile(lambda x: x > 1, list_data)))
Copy after login
zip_longest(*iterables, fillvalue=None)
iterables:可迭代对象
fillvalue:当长度超过时,缺省值、默认值, 默认为None
返回迭代器, 可迭代对象元素一一对应生成元组,当两个可迭代对象长度不一致时,会按照最长的有元素输出并使用fillvalue补充,是zip的反向扩展,zip为最小长度输出。
from itertools import zip_longest
list_data = [1, 2, 3]
list_data2 = ["a", "b", "c", "d"]
print(list(zip_longest(list_data, list_data2, fillvalue="-")))
print(list(zip_longest(list_data, list_data2)))
print(list(zip(list_data, list_data2)))
[(1, 'a'), (2, 'b'), (3, 'c'), ('-', 'd')]
[(1, 'a'), (2, 'b'), (3, 'c'), (None, 'd')]
[(1, 'a'), (2, 'b'), (3, 'c')]
Copy after login
总结
accumulate(iterable: Iterable, func: None, initial:None):
进行可迭代对象元素的累计运算,可以设置初始值,类似于reduce,相比较reduce,accumulate可以输出中间过程的值,reduce只能输出最后结果,且accumulate性能略好于reduce。
chain(*iterables)
依次输出迭代器中的元素,不会循环输出,有多少输出多少。当输出字典元素时,默认会输出字典的键;而对于列表,则相当于使用extend函数。
combinations(iterable: Iterable, r):
抽取可迭代对象的子序列,其实就是排列组合,不过只返回有序、不重复的子序列,以元组形式呈现。
combinations_with_replacement(iterable: Iterable, r)
类似于combinations,从可迭代对象中提取子序列,但是返回的子序列是无序且不重复的,以元组的形式呈现。
compress(data: Iterable, selectors: Iterable)
根据selectors中的元素是否为True或者False返回可迭代对象的合法元素,selectors为str时,都为True,并且只会决定长度。
count(start, step):
从start开始安装step不断生成元素,是无限循环的,最好控制输出个数或者使用next(),send()等获取、设置结果
cycle(iterable)
循环输出可迭代对象的元素,相当于对chain函数进行无限循环。建议控制输出数据的数量,或使用next()、send()等函数获取或设置返回结果。
dropwhile(predicate, iterable)
根据predicate是否为False来返回可迭代器元素,predicate可以为函数, 返回的是第一个False及之后的所有元素,不管后面的元素是否为True或者False。这个函数适用于舍弃迭代器或可迭代对象的开头部分,比如在写入文件时忽略文档注释

filterfalse(predicate, iterable)
类似于filter方法,返回所有满足predicate条件的元素,作为一个可迭代对象。
groupby(iterable, key=None)
输出连续符合key要求的键值对,默认为x == x。
islice(iterable, stop)\islice(iterable, start, stop[, step])
对可迭代对象进行切片,和普通切片类似,但是这个不支持负数。这种方法适用于迭代对象的切片,比如你需要获取文件中的某几行内容
pairwise(iterable)
返回连续的重叠对象(两个元素), 少于两个元素返回空,不返回。
permutations(iterable, r=None)
从可迭代对象中抽取子序列,与combinations类似,不过抽取的子序列是无序、可重复。
product(*iterables, repeat=1)
输出可迭代对象的笛卡尔积,类似于排序组合,不可重复,是两个或者多个可迭代对象进行操作,当是一个可迭代对象时,则返回元素,以元组形式返回。
repeat(object[, times])
重复返回object对象,默认时无限循环
starmap(function, iterable)
批量操作可迭代对象中的元素,操作的可迭代对象中的元素必须也要是可迭代对象,与map类似,但是可以对类似于多元素的元组进行操作。
takewhile(predicate, iterable)
返回前多少个predicate为True的元素,如果第一个为False,则直接输出一个空。
zip_longest(*iterables, fillvalue=None)
将可迭代对象中的元素一一对应,组成元组形式存储,与zip方法类似,不过zip是取最短的,而zip_longest是取最长的,缺少的使用缺省值。
The above is the detailed content of How to use the itertools module in Python. For more information, please follow other related articles on the PHP Chinese website!















 1378
1378
 52
52

 Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
 The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
 How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
 How to view server version of Redis
Apr 10, 2025 pm 01:27 PM
How to view server version of Redis
Apr 10, 2025 pm 01:27 PM
 How secure is Navicat's password?
Apr 08, 2025 pm 09:24 PM
How secure is Navicat's password?
Apr 08, 2025 pm 09:24 PM
