

Example analysis of RDB persistence in Redis

1. Introduction to RDB
RDB is a method used by Redis for persistence. It writes a snapshot of the data set in the current memory to the disk, that is, a Snapshot snapshot (all key-value pairs in the database). data). During recovery, the snapshot file is read directly into memory.
2. Triggering method
RDB has two triggering methods, namely automatic triggering and manual triggering.
①. Automatic triggering
Under SNAPSHOTTING in the redis.conf configuration file, we have introduced it in this article.
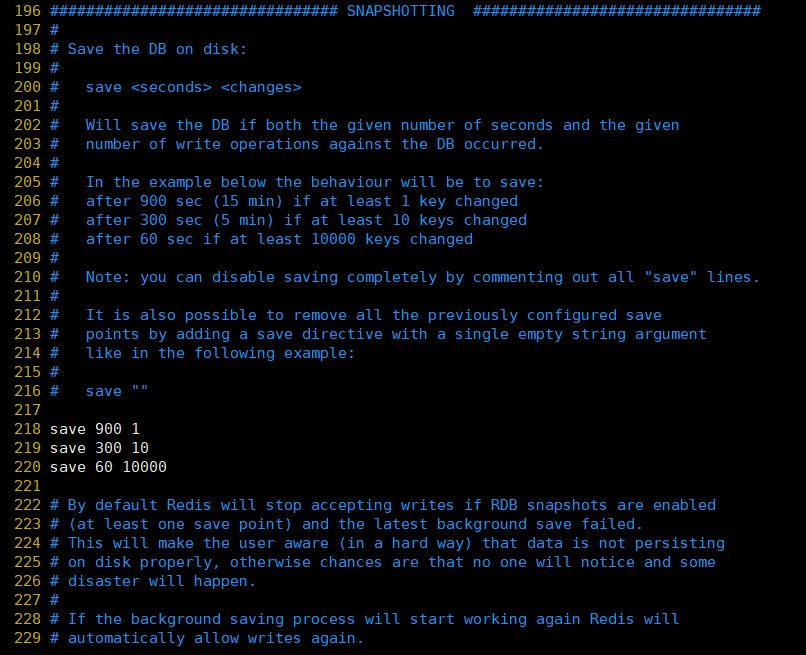
①.save:This is used to configure the RDB persistence conditions that trigger Redis, that is, when to save the data in the memory to the hard disk. . For example "save m n". Indicates that when the data set has been modified n times within m seconds, bgsave is automatically triggered (this command will be introduced below, and the command to manually trigger RDB persistence)
The default configuration is as follows:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
Of course, if you If you are just using the caching function of Redis and do not need persistence, you can comment out all save lines to disable the saving function. You can use save "" to disable
②, stop-writes-on-bgsave-error: The default value is yes. When RDB is enabled and the last background save of data fails, whether Redis stops receiving data. This would make the user aware that the data was not persisted to disk correctly, otherwise no one would notice that a disaster had occurred. If Redis restarts, it can start receiving data again
③, rdbcompression;The default value is yes. For snapshots stored on disk, you can set whether to compress them for storage. If so, redis will use the LZF algorithm for compression. If you don't want to consume CPU for compression, you can set this feature to off, but the snapshots stored on disk will be larger.
④, rdbchecksum: The default value is yes. After storing the snapshot, we can also let redis use the CRC64 algorithm for data verification, but this will increase performance consumption by about 10%. If you want to get the maximum performance improvement, you can turn off this function.
⑤、dbfilename:Set the file name of the snapshot, the default is dump.rdb
⑥、dir:Set the storage path of the snapshot file, This configuration item must be a directory, not a file name. The default is to save it in the same directory as the current configuration file.
That is to say, through the save method configured in the configuration file, when the actual operation meets the configuration form, RDB persistence will be performed, and the current memory snapshot will be saved in the directory configured by dir. The file name is Determined by the configured dbfilename.
②. Manual trigger
There are two commands to manually trigger Redis for RDB persistence:
1. save
This command will block the current Redis Server, during the execution of the save command, Redis cannot process other commands until the RDB process is completed.
Obviously, this command will cause long-term blocking for instances with relatively large memory. This is a fatal flaw. In order to solve this problem, Redis provides a second way.
2. bgsave
When executing this command, Redis will perform snapshot operations asynchronously in the background, and the snapshot can also respond to client requests. When the Redis process performs a fork operation to create a child process, the child process will be responsible for executing the RDB persistence process and automatically terminate after completion. Blocking only occurs during the fork phase and is generally very short-lived.
Basically all RDB operations inside Redis use the bgsave command.
ps: Executing the flushall command will also generate the dump.rdb file, but it is empty and meaningless
3. Restore data
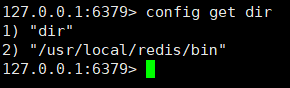
Move the backup file (dump.rdb) to the redis installation directory and start the service. Redis will automatically load the file data into memory. The Redis server will block during loading of the RDB file until the loading work is completed.
To obtain the installation directory of redis, you can use the config get dir command
4. Stop RDB persistence
In some cases, we only If you want to take advantage of the caching function of Redis, it is not like using the persistence function of Redis, so we'd better stop RDB persistence at this time. You can disable the save function by commenting out all the save lines in the configuration file redis.conf as mentioned above, or by directly using an empty string to disable it: save ""
You can also pass the command:
1 |
|
5. Advantages and Disadvantages of RDB
①、Advantages
The Redis data set is saved in an RDB file at a specific point in time. This file is very compact. This file is ideal for backup and disaster recovery.
2. When generating an RDB file, the redis main process will fork() a child process to handle all saving work. The main process does not need to perform any disk IO operations.
3.RDB is faster than AOF when restoring large data sets.
②、Disadvantages
1. RDB data cannot achieve real-time persistence/second-level persistence. Because every time bgsave runs, it must perform a fork operation to create a child process, which is a heavyweight operation (the data in the memory is cloned, and roughly 2 times the expansion needs to be considered). Frequent execution costs are too high (affecting performance)
2. RDB files are saved in a specific binary format. During the evolution of the Redis version, there are multiple formats of RDB versions. There is a problem that the old version of the Redis service is not compatible with the new version of the RDB format (version incompatibility)
3. Make a backup at a certain interval, so if redis accidentally goes down, all modifications after the last snapshot will be lost (data will be lost)
6. The principle of RDB automatic saving
Redis has a server status structure:
|
1 2 3 4 5 6 7 8 9 |
|
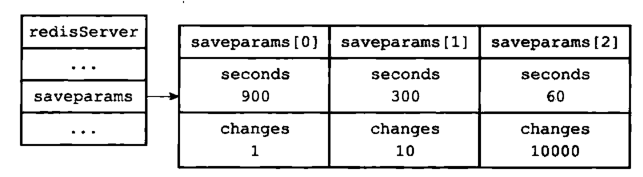
① First, look at the saveparam array that records the save conditions. Each element in it is A saveparams structure:
|
1 2 3 4 5 6 |
|
Previously we configured save in the redis.conf configuration file:
|
1 2 3 |
|
Then the saveparam array in the server status will be It looks like this:
②、Dirty counter and lastsave attribute
The dirty counter records the distance since the last successful execution of the save command or bgsave command. The Redis server performs How many times has it been modified (including writing, deleting, updating, etc.).
The lastsave attribute is a timestamp that records the last time the save command or bgsave command was successfully executed.
Through these two commands, when the server successfully performs a modification operation, the dirty counter will be incremented by 1, and the lastsave attribute records the time when save or bgsave was last executed. The Redis server also has a periodic operation function. severCron is executed every 100 milliseconds by default. This function will traverse and check all save conditions in the saveparams array. As long as one condition is met, the bgsave command will be executed.
After the execution is completed, the dirty counter is updated to 0, and lastsave is also updated to the completion time of the executed command.
The above is the detailed content of Example analysis of RDB persistence in Redis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
Redis, as a message middleware, supports production-consumption models, can persist messages and ensure reliable delivery. Using Redis as the message middleware enables low latency, reliable and scalable messaging.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
