

What are MySQL locks and classifications?


1. Database concurrency scenario
In high concurrency scenarios, without considering other middleware, the following scenarios will exist in the database:
Read: There is no problem and no concurrency control is required.
Reading and writing: There are thread safety issues, which may cause transaction isolation problems, and may encounter dirty reads, phantom reads, and non-repeatable reads.
Write: There are thread safety issues, and there may be update loss issues, such as the first type of update being lost and the second type of update being lost.
In response to the above problems, the SQL standard stipulates that different problems may occur under different isolation levels:
MySQL four major isolation levels:
| Isolation level | Dirty read | Non-repeatable read | Phantom read | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| READ UNCOMMITTED: Uncommitted read | May happen | May happen | May happen | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Solution | May happen | May happen | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Solution | Solution | Possible occurrence | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Solution | Solution | solve |

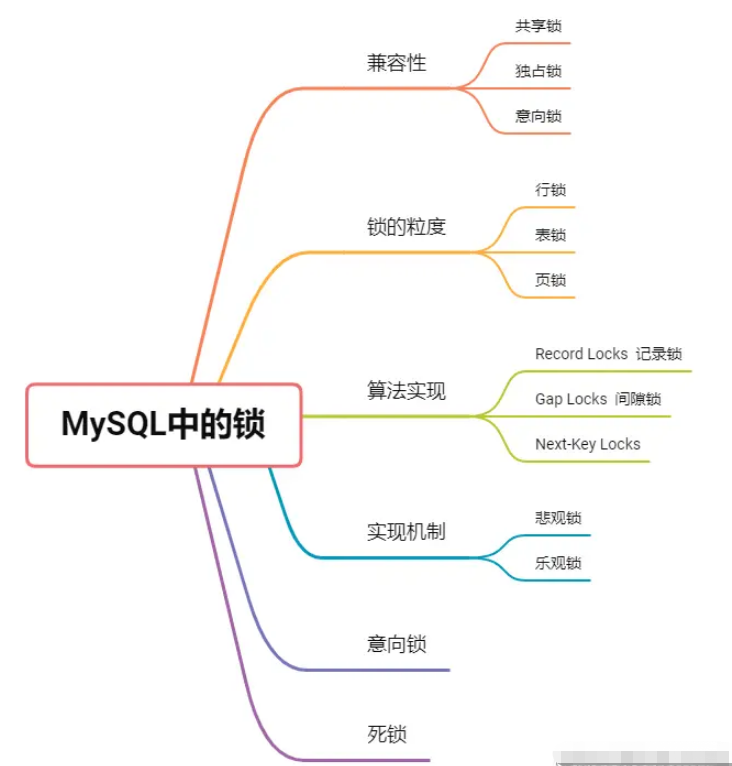
| Row lock | Table lock | Page lock | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lock granularity | small | 大 | between the two | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| add Lock efficiency | Slow | Fast | Between the two | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Conflict probability | Low | High | - | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| High | Low | General | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Big | Small | Between the two | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| whether or not |
| IS | X | IX | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Compatible | Compatible | Incompatible | Incompatible | ||||||||||||||||||||
| Compatible | Compatible | Incompatible | Incompatible | ||||||||||||||||||||
| Not compatible | Not compatible | Not compatible | Not compatible | ||||||||||||||||||||
| Compatible | Compatible | Incompatible | Incompatible |
| Row lock | Table lock | Page lock | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lock granularity | small | 大 | between the two | ||||||||||||||||||||
| add Lock efficiency | Slow | Fast | Between the two | ||||||||||||||||||||
| Conflict probability | Low | High | - | ||||||||||||||||||||
| High | Low | General | |||||||||||||||||||||
| Big | Small | Between the two | |||||||||||||||||||||
| whether or not |
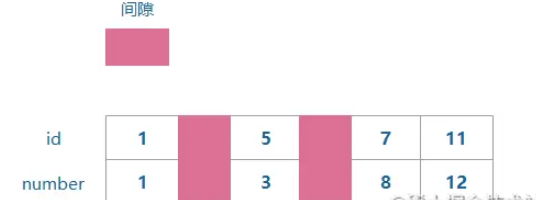
| A | B | |
|---|---|---|
| ① | BEGIN | |
| ② | BEGIN | |
| ③ | SELECT * FROM user WHERE name='a' FOR UPDATE |
|
| ④ | SELECT * FROM user WHERE name='b' FOR UPDATE |
|
| ⑤ | SELECT * FROM user WHERE name='b' FOR UPDATE |
|
| ⑥ | SELECT * FROM user WHERE name='a' FOR UPDATE |
1、开启 A、B 两个事务;
2、首先 A 先查询name='a'的数据,然后 B 也查询name='b'的数据;
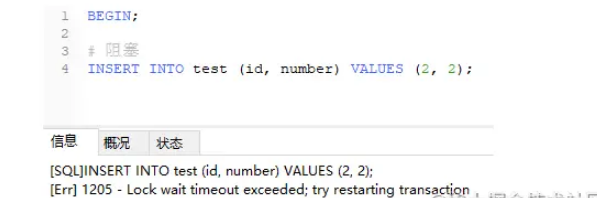
3、在 B 没释放锁的情况下,A 尝试对 name='b'的数据加锁,此时会阻塞;
4、若此时,事务 B 在没释放锁的情况下尝试对 name='a'的数据加锁,则产生死锁。

此时,MySQL 检测到了死锁,并结束了 B 中事务的执行,此时,切回事务 A,发现原本阻塞的 SQL 语句执行完成了。可通过show engine innodb status \G查看死锁。
如何避免
从上面的案例可以看出,死锁的关键在于:两个(或以上)的 Session 加锁的顺序不一致,所以我们在执行 SQL 操作的时候要让加锁顺序一致,尽可能一次性锁定所需的数据行。
The above is the detailed content of What are MySQL locks and classifications?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1379
1379
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
