

What are the knowledge points of redo log and undo log in MySQL logs?


Redo Log
REDO LOG is called a redo log. When the MySQL server unexpectedly crashes or goes down, Ensure that committed transactions are persisted to disk (persistence).
InnoDB operates records in units of pages. Additions, deletions, modifications and queries will load the entire page into the buffer pool (disk -> memory). The modification operation in the transaction does not directly modify the data in the disk. Instead, the data in the buffer pool in memory is modified first, and the background thread asynchronously refreshes it to the disk every once in a while.
Buffer pool: It can store indexes and data, accelerate reading and writing, directly operate data pages in memory, and has a dedicated thread to write dirty pages in the buffer pool to disk.
Why not directly modify the data on the disk?
Because if you directly modify the disk data, it is random IO. The modified data is distributed in different locations on the disk and needs to be searched back and forth. Therefore, the hit rate is low and the consumption is high. Moreover, a small modification cannot The entire page is not refreshed to the disk, and the utilization rate is low;
In contrast, sequential IO, the disk data is distributed in one part of the disk, so the search process is omitted and the seek time is saved.
Using background threads to refresh the disk at a certain frequency can reduce the frequency of random IO and increase throughput. This is the fundamental reason for using the buffer pool.
The problem of modifying the memory and then asynchronously synchronizing it to the disk:
Because the buffer pool is an area in the memory, the data may be lost if the system crashes unexpectedly, and some dirty data may not be refreshed in time. Disk, transaction durability is not guaranteed. Therefore, redo log was introduced. When modifying data, an additional log is recorded, which shows that the xx offset of page xx has changed by xx. When the system crashes, it can be recovered based on the log content.
The difference between writing logs and directly refreshing the disk is: writing logs is append writing, sequential IO, faster, and the written content is relatively smaller
The redo log is composed of two parts :
redo log buffer (memory level, default 16M, can be modified through the innodb_log_buffer_size parameter)
redo log file (persistent, disk Level)
The general process of the modification operation:
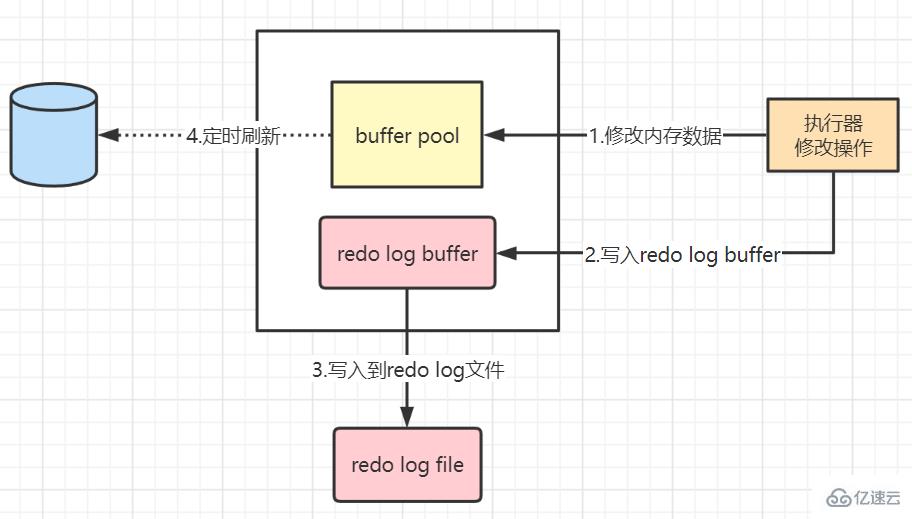
Step 1: First read the original data from the disk into the memory , modify the memory copy of the data and generate dirty data
Step 2: Generate a redo log and write it into the redo log buffer, recording the modified value of the data
Step 3 : By default, the contents of the redo log buffer will be flushed to the redo log file after the transaction is submitted, and the redo log file will be appended to write
Step 4: Regularly refresh the modified data in the memory to the disk ( What we are talking about here is the dirty data that has not been flushed by the background thread in time)
The commonly referred to as Write-Ahead Log (pre-log persistence) refers to the process of persisting a data page before persisting it. The corresponding log page is persisted in memory.
Benefits of redo log:
Reduced disk refresh frequency
redo log takes up little space
redo log writing speed is fast
Can redo log definitely guarantee the durability of transactions?
Not necessarily, this depends on the redo log flushing strategy, because the redo log buffer is also in memory. If the transaction is submitted, the redo log buffer has not had time to refresh the data to the redo log file for persistence. ization, if a downtime occurs at this time, data will still be lost. How to solve? Sweep strategy.
redo log flush strategy
InnoDB provides three strategies for the innodb_flush_log_at_trx_commit parameter to control when the redo log buffer is flushed to the redo log file:
The value is 0: start a background thread, refresh to the disk every 1s, there is no need to refresh when submitting the transaction
The value is 1: synchronize the refresh when committing ( Default value), truly ensuring the persistence of data
The value is 2: When committing, it is only flushed into the os kernel buffer, and the specific flushing time is uncertain
If the value is 0:
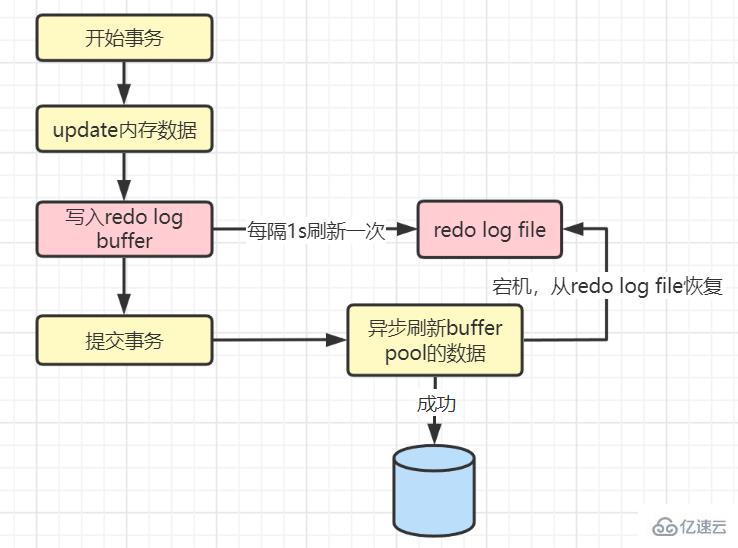
Because there is an interval of 1s, 1 second of data will be lost in the worst case.
When the value is 1:
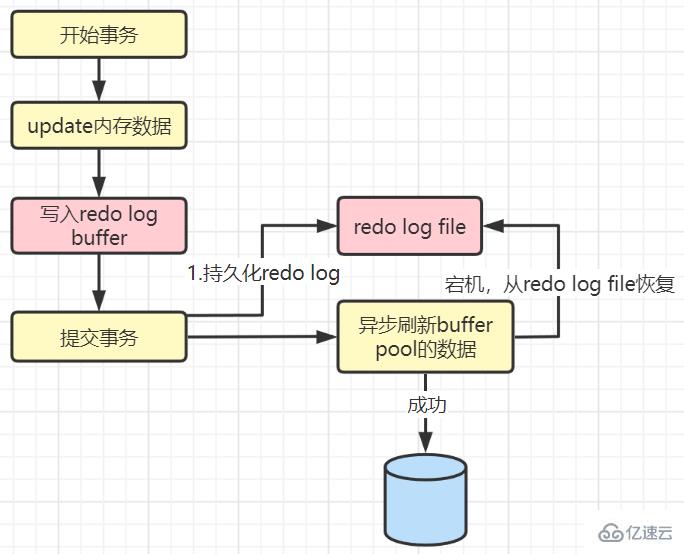
#When committing, you need to actively refresh the redo log buffer to the redo log file. If it crashes in the middle, the transaction will If it fails, there will be no loss, and the durability of the transaction can truly be guaranteed. But the efficiency is the worst.
If the value is 2: it is determined based on the os.
Can be adjusted to 0 or 2 to improve transaction performance, but the ACID characteristics are lost
Other parameters
innodb_log_group_home_dir: Specify the path where the redo log file group is located. The default value is ./, which means it is in the data directory of the database. There are two files named ib_logfile0 and ib_logfile1 in the default data directory of MySQL. The logs in the log buffer are flushed to these two disk files by default.
innodb_log_files_in_group: Specify the number of redo log files. The naming method is such as: ib_logfile0, iblogfile1... iblogfilen. Default is 2, maximum is 100.
By default, the size of innodb_log_file_size is set to 48M, which is used to set the size of a single redo log file.
Undo Log
undo log is used to ensure the atomicity and consistency of transactions. It has two functions: ① Provide rollback operation ② Multi-version control MVVC
Rollback operation
As mentioned in the redo log earlier, the background thread will refresh the data in the buffer pool from time to time. to the disk, but if various errors (downtime) occur during the execution of the transaction or a rollback statement is executed, then the previously brushed operations need to be rolled back to ensure atomicity. The undo log provides transaction rollback.
MVVC
When a read row is locked by other transactions, it can analyze the previous data version of the row record from the undo log, so that users can read it To the data before the current transaction operation - snapshot read.
Snapshot reading: The data read by SQL is the historical version, no locking is required, ordinary SELECT is snapshot reading.
Components of undo log:
When inserting a record, the primary key value of the record must be recorded so that the data can be deleted during rollback. .
When updating records, all modified old values must be recorded, and then updated to the old values during rollback.
When deleting, all records must be recorded, and the records of the content must be re-inserted when rolling back.
The select operation will not generate undo log
Rollback segment and undo page
In the InnoDB storage engine, the undo log uses rollback segment to roll back Segments are stored, and each rollback segment contains 1024 undo log segments. After MySQL5.5, there are a total of 128 rollback segments. That is, a total of 128 * 1024 undo operations can be recorded.
Each transaction will only use one rollback segment, and one rollback segment may serve multiple transactions at the same time.
Deleting the undo log cannot be performed immediately after committing the transaction, because some transactions may want to read the previous data version (snapshot read). Therefore, when a transaction is committed, the undo log is put into a linked list, called a version chain. Whether the undo log is deleted or not is judged by a thread called purge.
Undo type
undo log is divided into:
insert undo log
Because the record of insert operation is only visible to the transaction itself, not to other transactions It can be seen (this is a requirement of transaction isolation), so the undo log can be deleted directly after the transaction is committed. No purge operation is required.
update undo log
Undo logs record the changes made to delete and update operations.. In order to support the MVCC mechanism, the undo log cannot be deleted immediately when the transaction is committed. When submitting, add it to the undo log list and wait for the cleanup thread to perform final deletion.
Life cycle of undo log
Suppose there are 2 values, A=1 and B=2, and then a transaction modifies A to 3 and B to 4. The modification process Can be simplified to:
1.begin
2. Record A=1 to undo log
3.update A=3
4. Record A=3 to redo log
5. Record B=2 to undo log
6.update B=4
7. Record B=4 to redo log
8. Refresh redo log to disk
9.commit
If the system crashes in any step 1-8 and the transaction is not committed, the transaction will not have any impact on the data on the disk.
If it goes down between 8-9, you can choose to roll back after recovery, or you can choose to continue to complete the transaction submission, because the redo log has been persisted at this time.
If the system goes down after 9 and the data changed in the memory map is not flushed back to the disk, then after the system recovers, the data can be flushed back to the disk according to the redo log.
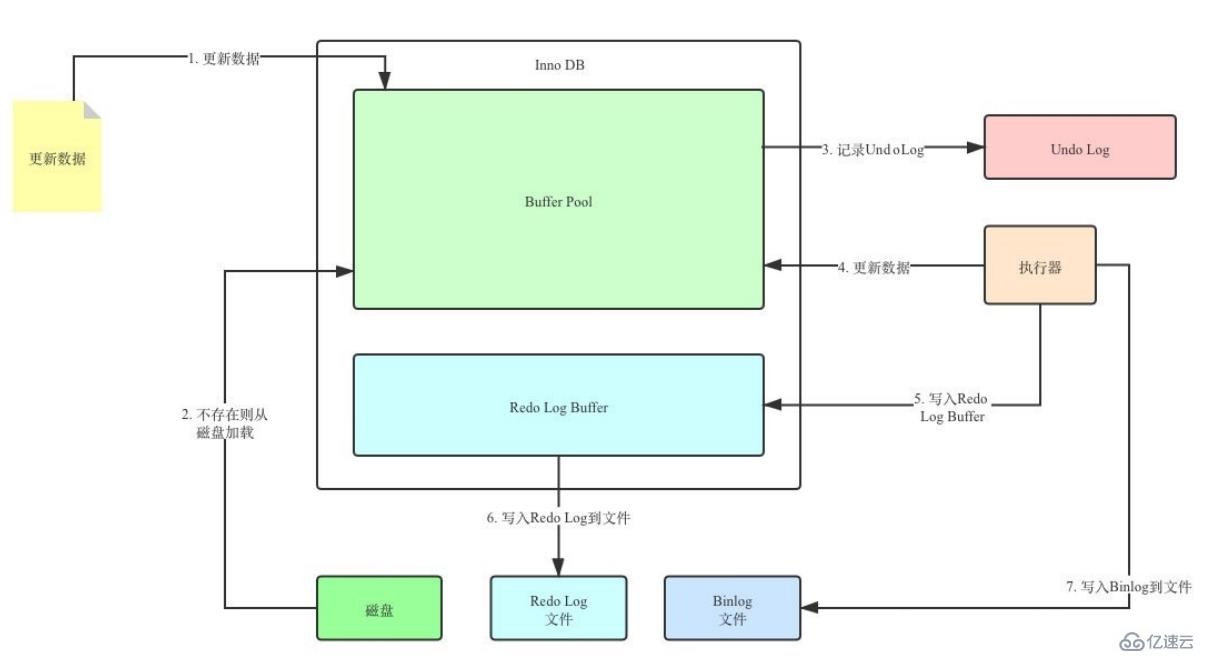
Detailed generation process
For the InnoDB engine, in addition to the data of the record itself, each row record also has Several hidden columns:
DB_ROW_ID: the primary key id of the record.
DB_TRX_ID: Transaction ID. When a record is modified, the ID of the transaction will be recorded.
DB_ROLL_PTR: rollback pointer, pointer in the version chain.

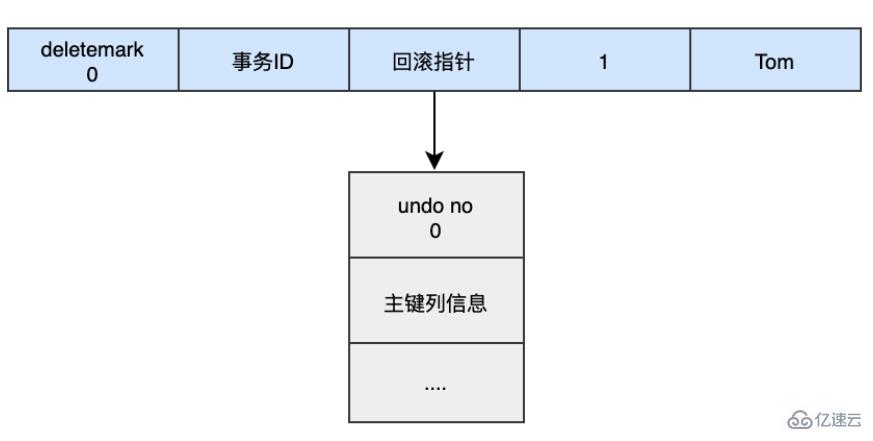
When we execute INSERT:
begin; INSERT INTO user (name) VALUES ('tom');
Every time data is inserted, an undo log of the insertion operation will be created, and the rollback pointer of the data will point to this log. The undo log will record the serial number of the undo log, the column and value of the primary key inserted... Then when performing rollback, the corresponding data can be deleted directly through the primary key.
When we execute UPDATE:
When performing an update operation, an update undo log will be generated, including two situations: updating the primary key and not updating the primary key. . Assume that the update operation is now performed:
UPDATE user SET name='Sun' WHERE id=1;
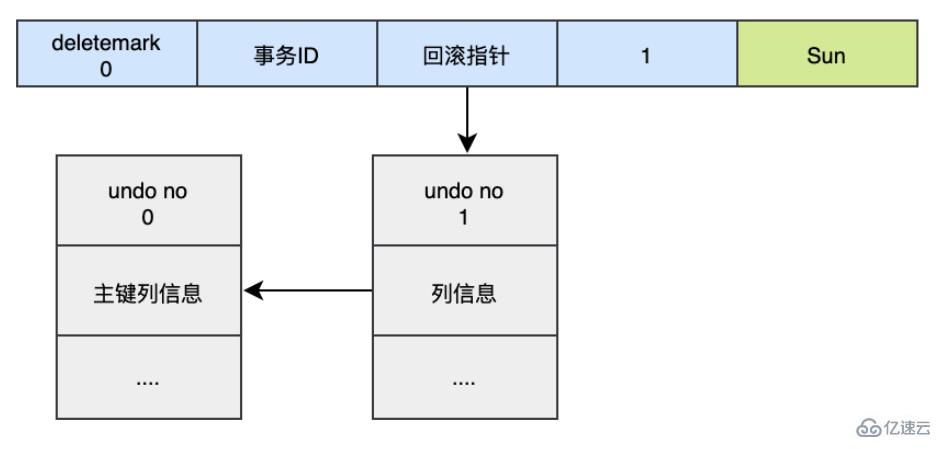
At this time, the new undo log record will be added to the version chain, its undo no is 1, and the new undo log The rollback pointer will point to the old undo log (undo no=0).
Assume now:
UPDATE user SET id=2 WHERE id=1;
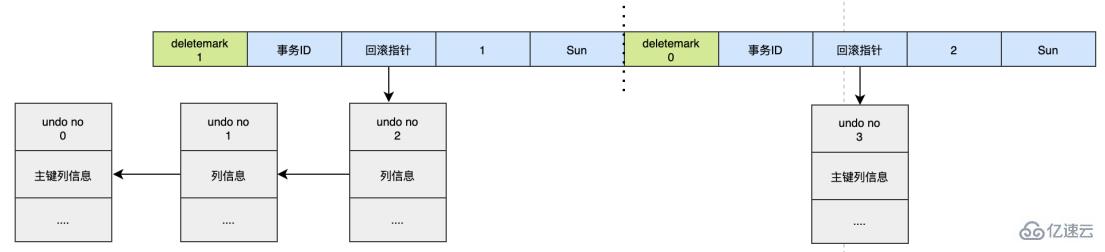
For the operation of updating the primary key, the original data deletemark will be opened first, and the data will not be actually deleted at this time. , the actual deletion will be left to the cleaning thread to judge, and then a new data will be inserted later. The new data will also generate an undo log, and the sequence number of the undo log will be incremented.
It can be found that every change to data will generate an undo log. When a record is changed multiple times, multiple undo logs will be generated. The undo log records the log before the change, and The sequence number of each undo log is increasing, so when you want to roll back, push forward according to the sequence number to find our original data.
How undo log is rolled back
Based on the above example, assuming rollback is executed, the corresponding process should be like this:
1. Pass undo no= Use the log of 3 to delete the data with id=2
2. Use the log of undo no=2 to restore the deletemark of the data with id=1 to 0
3. Use the undo no=1 The log restores the name of the data with id=1 to Tom
4. Delete the data with id=1 through the undo no=0 log
MySQL MVVC multi-version concurrency control
Extension
bin log
Binary log, also known as update log, is a type of log file in binary format that records changes made to a database.. It records all update statements executed by the database.
Main application scenarios of binlog:
Data recovery: If MySQL stops unexpectedly, you can use this log for recovery and backup
Data replication: master passes its binary log to slaves to achieve master-slave data consistency
show variables like '%log_bin%';
View bin log log:
mysqlbinlog -v "/var/lib/mysql/binlog/xxx.000002"
Use log recovery Data:
mysqlbinlog [option] filename|mysql –uuser -ppass;
Delete binary log:
PURGE {MASTER | BINARY} LOGS TO ‘指定日志文件名'
PURGE {MASTER | BINARY} LOGS BEFORE ‘指定日期'Writing timing
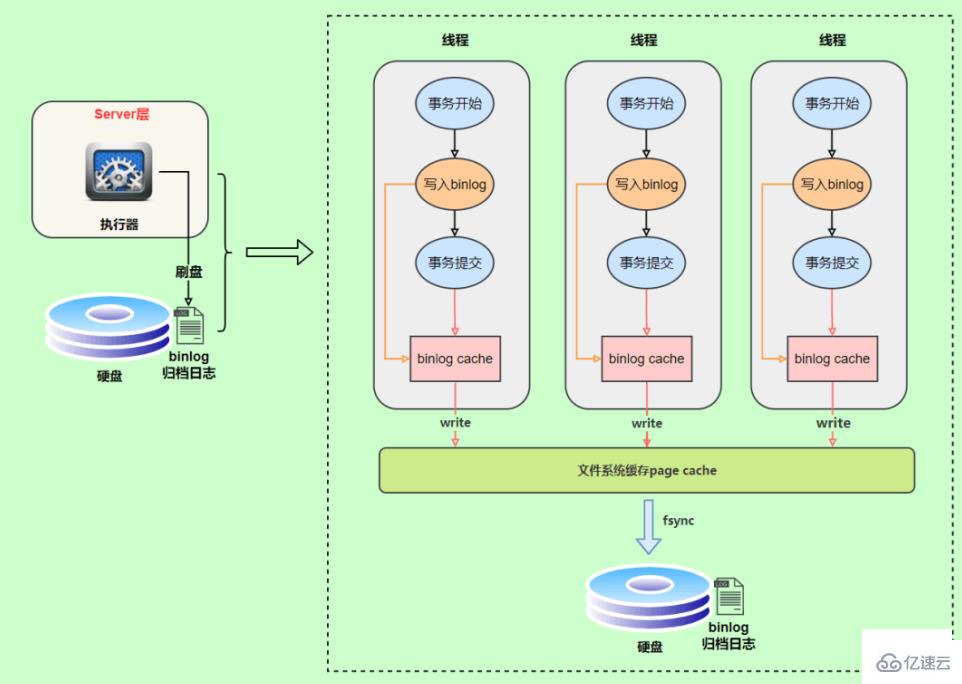
During transaction execution, the log is first written to the bin log cache, and when the transaction is submitted, The binlog cache is written to the binlog file. Because the binlog of a transaction cannot be split, no matter how big the transaction is, it must be written once, so the system will allocate a block of memory to each thread as the binlog cache.
Comparison between binlog and redo log
The redo log generated by the InnoDB storage engine layer is a physical log used to record " What modifications were made to which data pages?"
The binlog is a logical log, and the recorded content is the original logic of the statement. It is similar to adding 1 to the c field of the line with ID=2, which belongs to the service layer.
The two focuses are also different. Redo log gives InnoDB the ability to recover from crashes, and binlog ensures the data consistency of the MySQL cluster architecture.
Two-stage submission
During the execution of the update statement, two logs, redo log and binlog, will be recorded. Based on basic transactions, the redo log can be continuously written during the transaction execution process. Binlog is only written when a transaction is committed, so the writing timing of redo log and binlog is different.
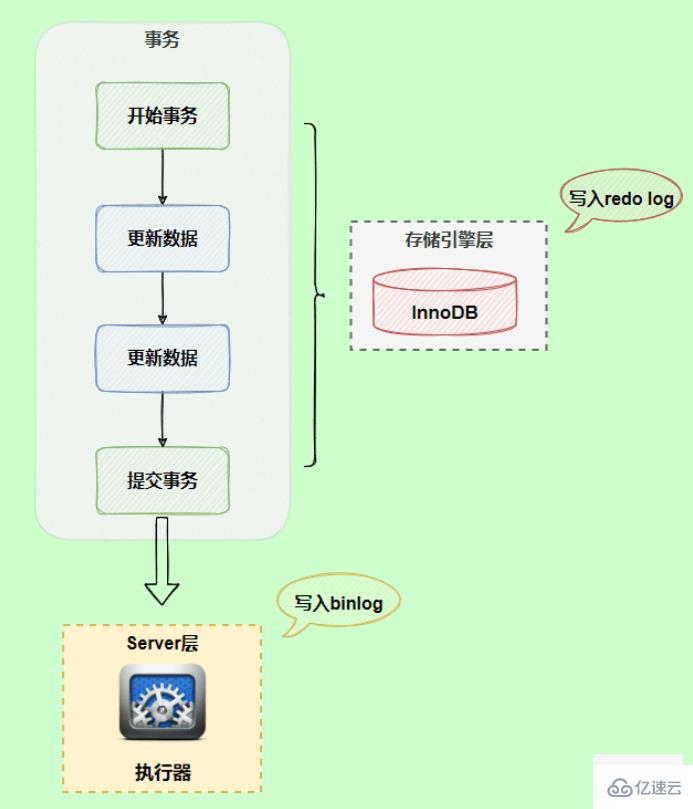
If the logic between redo log and binlog is inconsistent, what problems will occur?
Take the update statement as an example. Assume that for the record with id=2, the field c value is 0. Update the field c value to 1. The SQL statement is update T set c=1 where id=2.
Assume that after the redo log is written during the execution process, an exception occurs during the binlog log writing. What will happen?
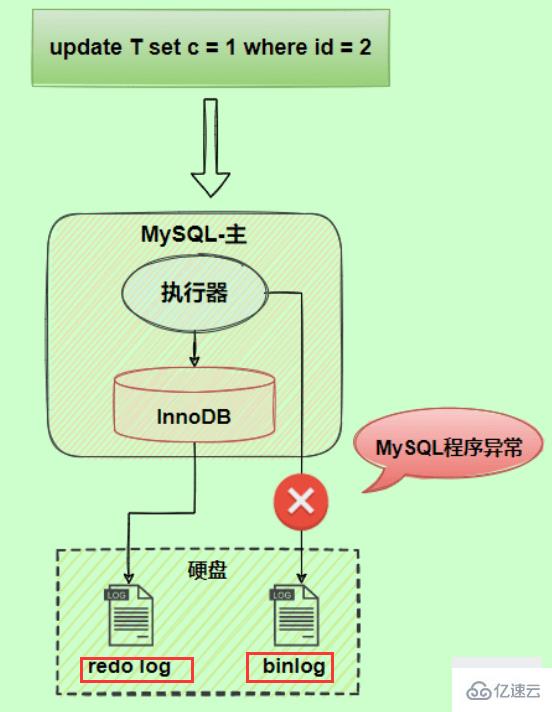
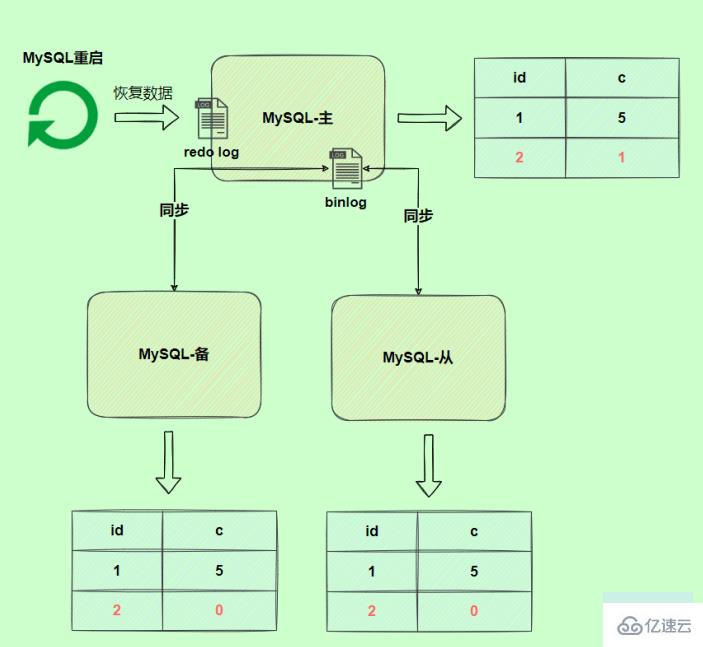
Because the binlog is interrupted abnormally Write, so there is no corresponding modification record. Therefore, when the binlog log is used to restore data or the slave reads the master's binlog, this update will be omitted. The c value of the restored row is 0, while in the original database, due to the redo log restore, the c value of this row is 1. The final data is inconsistent.
The InnoDB storage engine uses a two-phase commit scheme to deal with the logical consistency problem between the two logs. Two-stage submission refers to dividing the redo log into two steps: prepare and commit.
Let the final commits of redo log and bin log be bound together. As mentioned before, when a transaction is committed, by default, the redo log needs to be synchronized before the commit is successful, so if they are bound together, bin Log also has this feature, which ensures that data will not be lost.
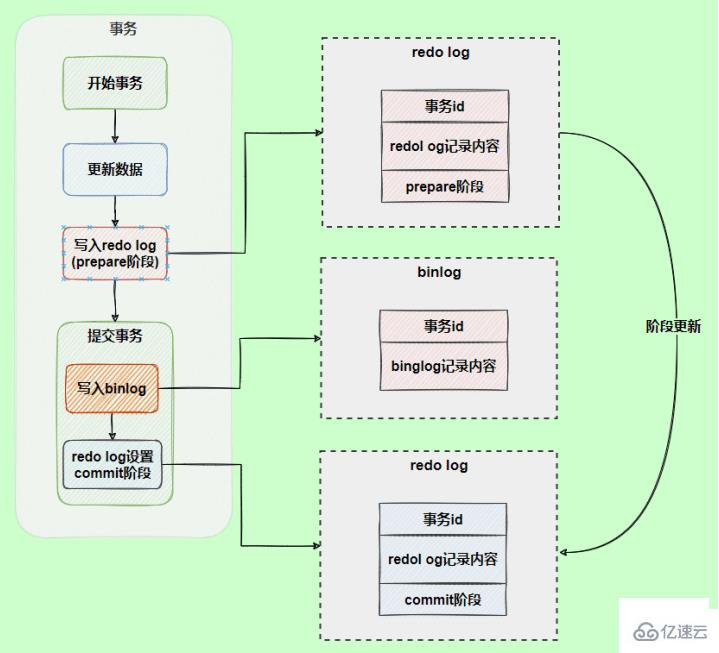
After using two-phase commit, there will be no impact if an exception occurs when writing the binlog, because when MySQL restores data based on the redo log log, it finds that the redo log is still in the prepare stage. And if there is no corresponding binlog log, the submission will fail and the data will be rolled back.
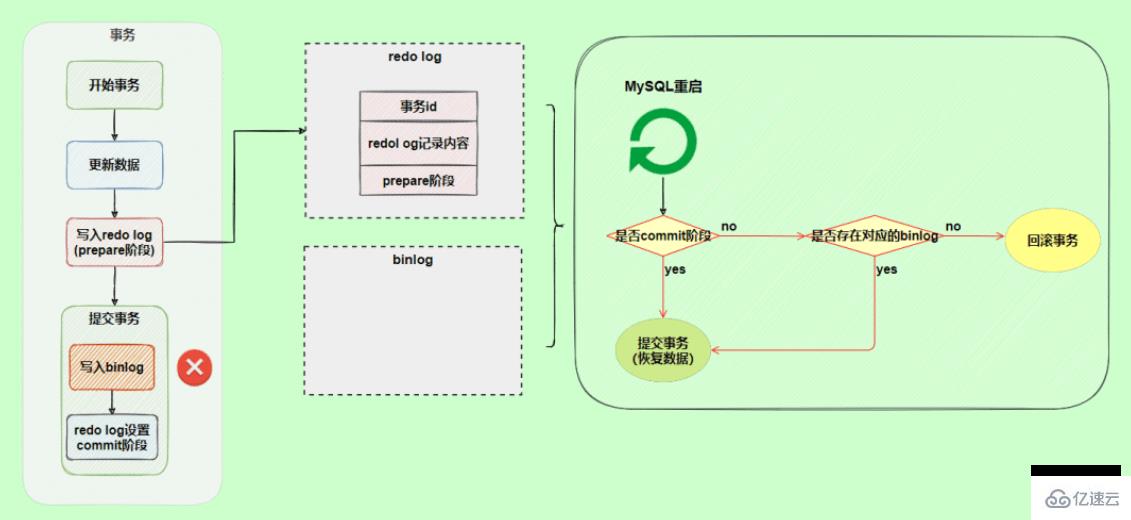
In another scenario, an exception occurs during the commit phase of the redo log. Will the transaction be rolled back?
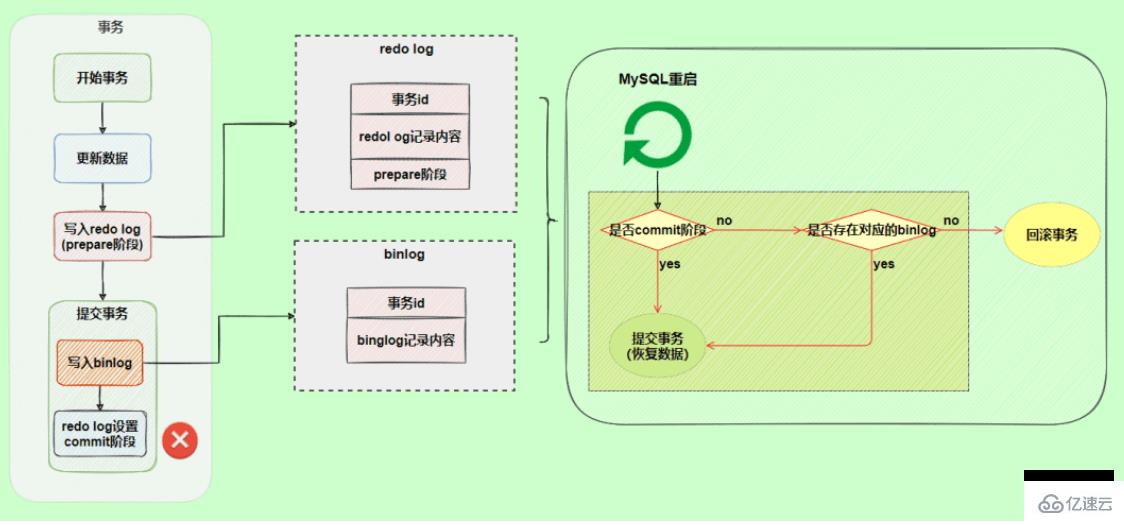
will not roll back the transaction, it will execute the logic framed in the above figure. Although the redo log is in the prepare stage, the corresponding binlog log can be found through the transaction ID. , so MySQL thinks it is complete and will submit the transaction to restore the data.
The above is the detailed content of What are the knowledge points of redo log and undo log in MySQL logs?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
