

Common statistical totals, calculation of tie values and other operations can be implemented using aggregate functions , common aggregate functions are:
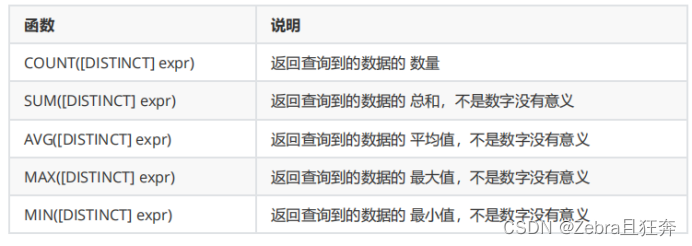

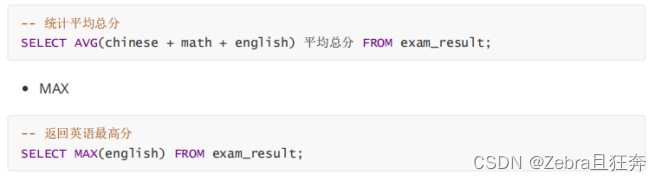


Note:
1. count: You can use count (*), count (0), count (1). To put it bluntly, it is actually the same as selecting 1 from the entire table. The 0 and 1 in this count are just passed in as parameters. , first select 1, and then count the value of count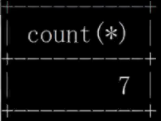
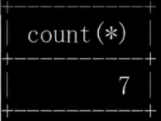
 ##2.sum, max, Neither min nor avg can be passed in *, fields or expressions must be passed in using
##2.sum, max, Neither min nor avg can be passed in *, fields or expressions must be passed in using
3. avg can be combined with sum, and multiple aggregate functions can be used together
2. GROUP BY clause

##The field specified by Select must be after group by Yes and no can only appear in aggregate functions, otherwise problems will occur 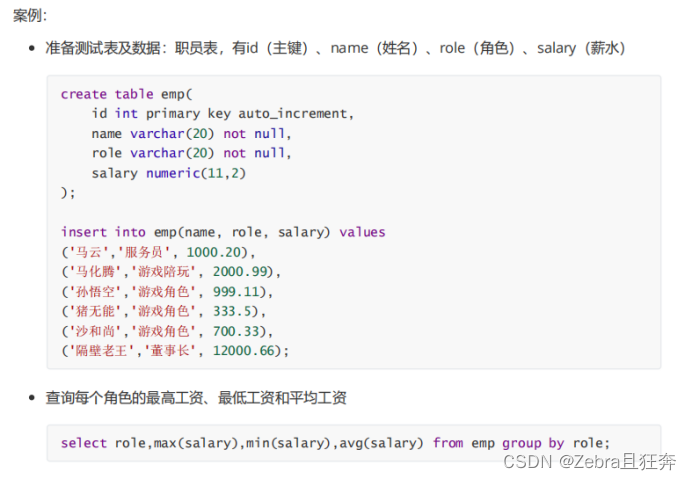
GROUP BY Notes
1. The essence of the Group by statement is grouping, often Use it with aggregate query
2. As long as there is an aggregate function, it may be grouped3. In the grouping operation, the query allows grouping fields and aggregate functions, and other non-grouping fields need to be guaranteed There are no multiple rows after grouping (such as student ID grouping, the query field can have student names, because after student ID grouping, there is only one row) 4. Use where to filter conditions before grouping, and use having after grouping (the code is the order Execution) Execution order: from > on> join > where > group by > with > having >select > distinct > order by > limitThe execution starts from from first, so aliases are generally named here. You can also name them in select, but select is executed later and the front is named. None of those places are used for execution.

Syntax:

You may not be able to distinguish the difference between the connection conditions and the filtering result set conditions in the second method. You can use either one, but give priority to the first one, in order to correspond to the subsequent outer joins. Inner join is equivalent to giving the connection condition on the obtained Cartesian product
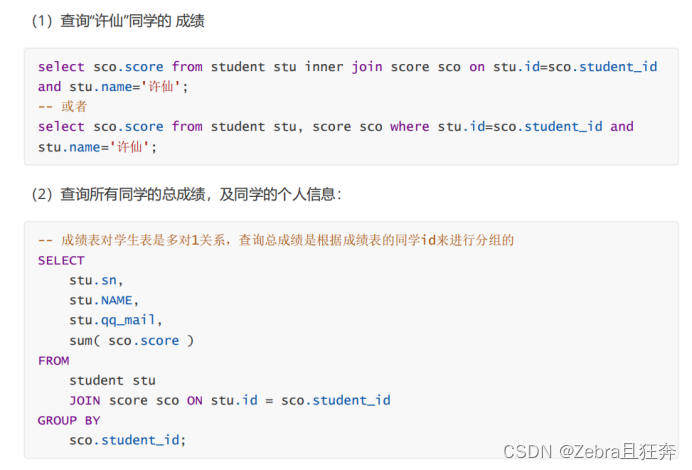
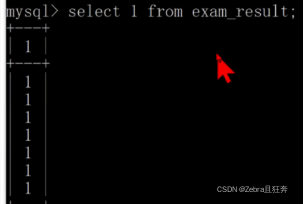
If group by is not used here, there will be only one line like the following, which is equivalent to Add up all the scores of all students. Since what we need is the total score of each student, we need to group them according to the student ID first.

Outer joins are divided into left outer joins and right outer joins. The left outer join is a connection method when the table on the left is completely displayed when a joint query is performed; the right outer join is a connection method when the table on the right is fully displayed when a joint query is performed.
Note:
Left join: The data in the left table will not be based on the joining condition (the part after on, including the and) Filter and display all, other conditions can still be filtered, such as adding where and other conditions later.
If there is data in the right table with values that do not meet the connection conditions, the data in the right table will display null and the left table will display all
Syntax: (Note: On can also be followed by where)


The same query method, this time it can show that the 8th place result is For empty student information, all the data in the left table, that is, the student table, will be displayed and will not be affected by the connection condition stu.id = sco.student_id. If it is within the previous When connecting , cannot display the information of the student "Foreigner Learning Chinese" , because there is no ID of the student "Foreigner Learning Chinese" in the sco table.
Self-join refers to querying by connecting itself in the same table.
Usage scenario: Compare multiple rows in the same table.
Note: Self-join queries can also be queried using the join on statement.
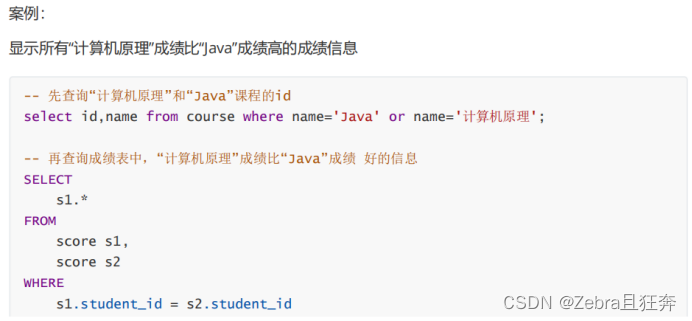
Subquery refers to a select statement embedded in other sql statements, also called a nested query
Query and classmates of "do not want to graduate" students: (self-join)

Multi-row subquery: subquery that returns multiple rows of records (used frequently)
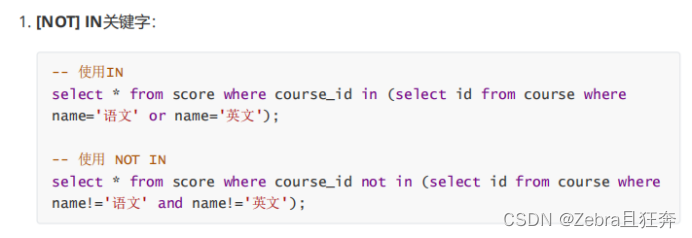
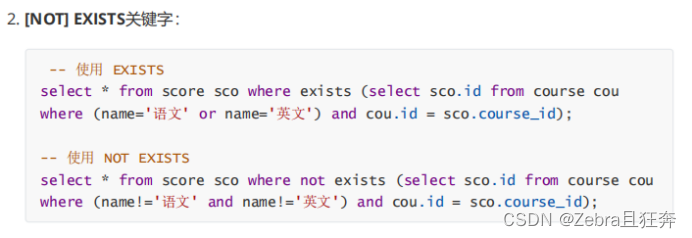
Case: Query the score information of "Chinese" or "English" courses: (internal connection)
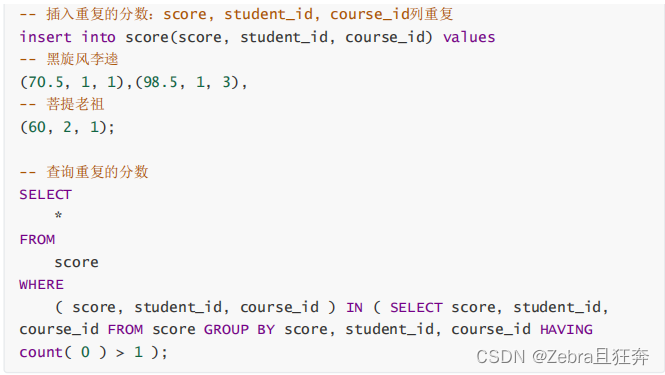
group by here It does not play a role in merging, but it plays a role in grouping
In practical applications, in order to merge the execution of multiple selects As a result, the set operators union, union all can be used. When using UNION and UNION ALL, the fields in the result sets of before and after the query must be consistent.
**In some cases, multiple tables cannot be related, but you need to query data in the same field
**Union is more efficient than or
union
This operator is used to obtain the union of two result sets. This operator will automatically eliminate duplicate rows in the result set, and will automatically deduplicate when the data content is exactly the same.
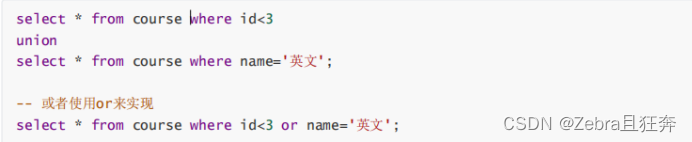
Case: Query courses with ID less than 3, or courses named "English":
union all
This operator is used to obtain the union of two result sets. When this operator is used, duplicate rows in the result set are not removed. (When the data obtained is exactly the same, it will be displayed and no duplication will be performed)
Case: Query for courses with an ID less than 3 or with the name "Java"

The above is the detailed content of Example analysis of MySQL aggregation query and union query operations. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



