
 Technology peripherals
AI
7nm process, more efficient than GPU, Meta releases first-generation AI inference accelerator
Technology peripherals
AI
7nm process, more efficient than GPU, Meta releases first-generation AI inference accelerator
7nm process, more efficient than GPU, Meta releases first-generation AI inference accelerator

Machine Heart Report
Heart of Machine Editorial Department
Recently, Meta revealed its latest progress in artificial intelligence.
When people think of Meta, they usually think of its apps, including Facebook, Instagram, WhatsApp, or the upcoming Metaverse. But what many people don't know is that this company designs and builds very sophisticated data centers to operate these services.
Unlike cloud service providers such as AWS, GCP or Azure, Meta is not required to disclose details about its silicon selection, infrastructure or data center design, except that its OCP is designed to impress buyers. Meta's users want a better, more consistent experience, regardless of how it's achieved.
At Meta, AI workloads are everywhere and form the basis for a wide range of use cases, including content understanding, information flow, generative AI, and ad ranking. These workloads run on PyTorch, with best-in-class Python integration, eager-mode development, and API simplicity. In particular, deep learning recommendation models (DLRMs) are very important for improving Meta’s services and application experience. But as the size and complexity of these models increase, the underlying hardware systems need to provide exponential increases in memory and computing power while remaining efficient.
Meta found that for current scale AI operations and specific workloads, GPUs are inefficient and not the best choice. Therefore, the company proposed the inference accelerator MTIA to help train AI systems faster.
MTIA V1
MTIA v1 (inference) chip (die)
In 2020, Meta designed the first generation MTIA ASIC inference accelerator for its internal workloads. The inference accelerator is part of its full-stack solution, which includes silicon, PyTorch and recommendation models.
The MTIA accelerator is fabricated on the TSMC 7nm process and runs at 800 MHz, delivering 102.4 TOPS at INT8 precision and 51.2 TFLOPS at FP16 precision. It has a thermal design power (TDP) of 25 W.
MTIA accelerators consist of processing elements (PEs), on-chip and off-chip memory resources, and interconnects. The accelerator is equipped with a dedicated control subsystem running system firmware. The firmware manages available compute and memory resources, communicates with the host through a dedicated host interface, and coordinates job execution on the accelerator.
The memory subsystem uses LPDDR5 as an off-chip DRAM resource, expandable to 128 GB. The chip also has 128 MB of on-chip SRAM, shared by all PEs, providing higher bandwidth and lower latency for frequently accessed data and instructions.
The MTIA accelerator grid consists of 64 PEs organized in an 8x8 configuration that are connected to each other and to the memory blocks via a mesh network. The entire grid can be used as a whole to run a job, or it can be divided into multiple sub-grids that can run independent jobs.
Each PE is equipped with two processor cores (one of which is equipped with vector extensions) and a number of fixed-function units that are optimized to perform critical operations such as matrix multiplication, accumulation, data movement, and nonlinear function calculations. The processor core is based on the RISC-V open instruction set architecture (ISA) and is heavily customized to perform the necessary computing and control tasks.
Each PE also has 128 KB of local SRAM memory for fast storage and manipulation of data. This architecture maximizes parallelism and data reuse, which are fundamental to running workloads efficiently.
The chip provides both thread- and data-level parallelism (TLP and DLP), leverages instruction-level parallelism (ILP), and enables massive memory-level parallelism (MLP) by allowing large numbers of memory requests to be processed simultaneously.
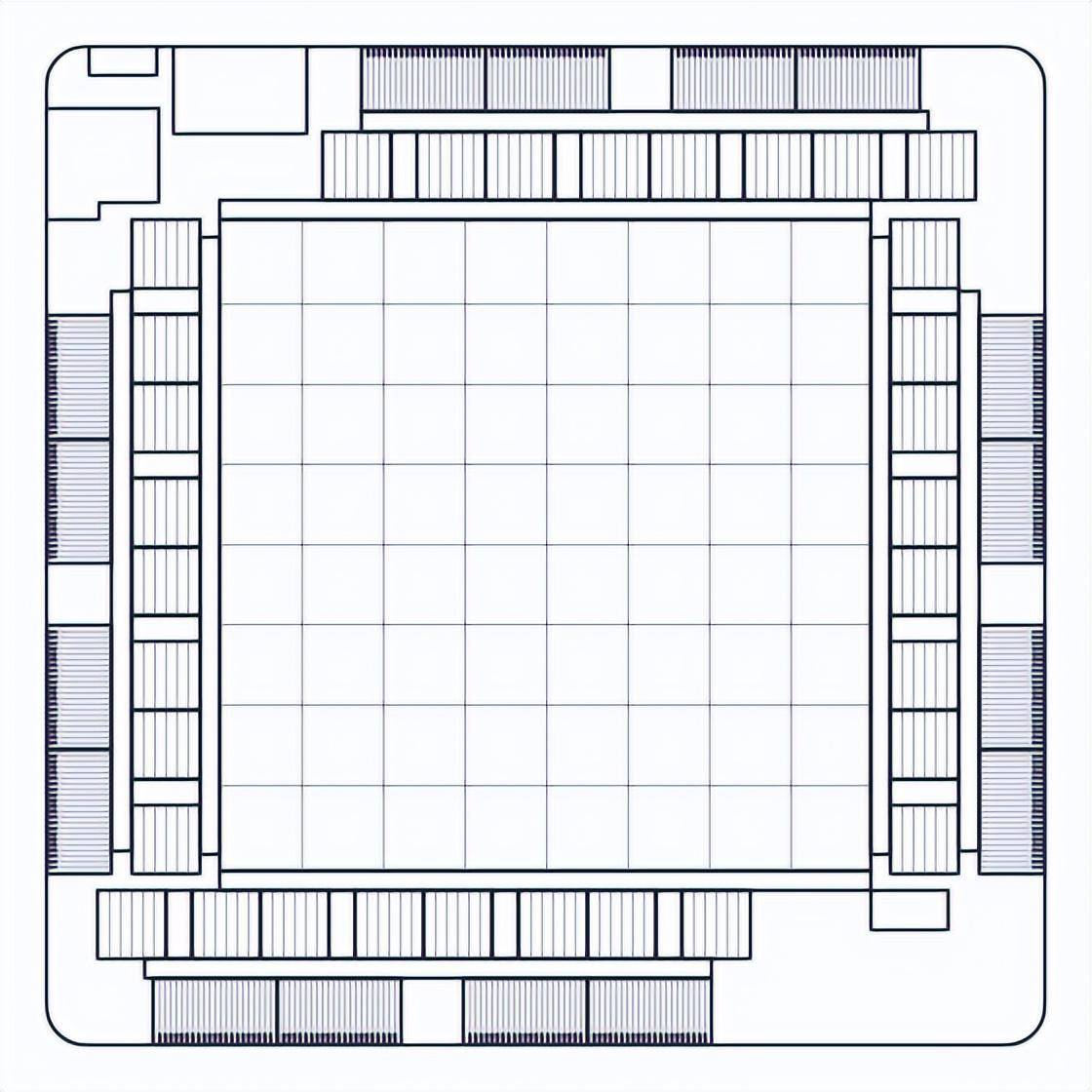
MTIA v1 system design
MTIA accelerators are mounted on small dual M.2 boards for easier integration into servers. The boards use a PCIe Gen4 x8 link to connect to the host CPU on the server, consuming as little as 35 W.

Sample test board with MTIA
The servers hosting these accelerators use the Yosemite V3 server specification from the Open Compute Project. Each server contains 12 accelerators that are connected to the host CPU and to each other using a PCIe switch hierarchy. Therefore, communication between different accelerators does not need to involve the host CPU. This topology allows workloads to be distributed across multiple accelerators and run in parallel. The number of accelerators and server configuration parameters are carefully selected to best execute current and future workloads.
MTIA Software Stack
MTIA software (SW) stack is designed to provide developers with better development efficiency and high-performance experience. It is fully integrated with PyTorch, giving users a familiar development experience. Using PyTorch with MTIA is as easy as using PyTorch with a CPU or GPU. And, thanks to the thriving PyTorch developer ecosystem and tools, the MTIA SW stack can now use PyTorch FX IR to perform model-level transformations and optimizations, and LLVM IR for low-level optimizations, while also supporting MTIA accelerator custom architectures and ISAs .
The following picture is the MTIA software stack framework diagram:
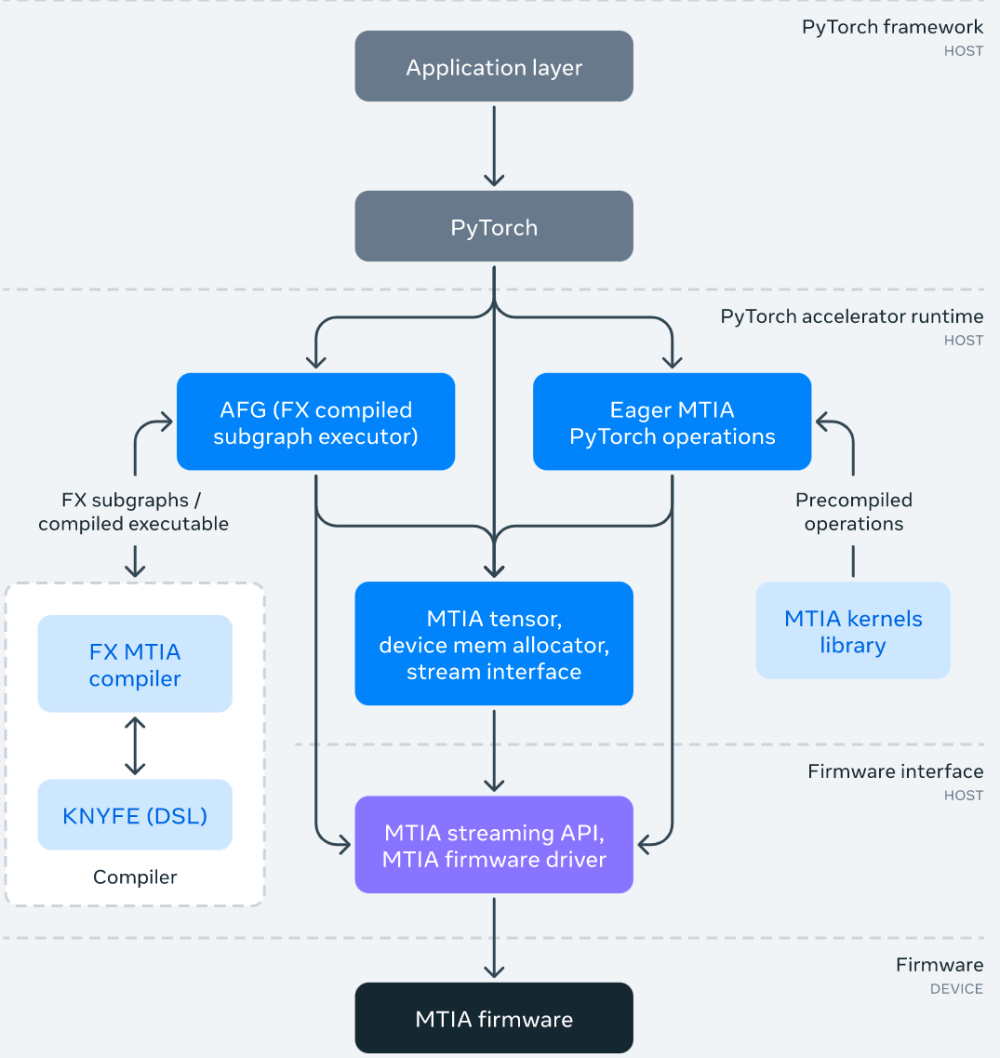
As part of the SW stack, Meta has also developed a hand-tuned and highly optimized kernel library for performance-critical ML kernels, such as fully connected and embedded package operators. Higher levels in the SW stack have the option of instantiating and using these highly optimized kernels during compilation and code generation.
Additionally, the MTIA SW stack continues to evolve with integration with PyTorch 2.0, which is faster and more Pythonic, but as dynamic as ever. This will enable new features such as TorchDynamo and TorchInductor. Meta is also extending the Triton DSL to support the MTIA accelerator and use MLIR for internal representation and advanced optimization.
MTIA Performance
Meta compared the performance of MTIA with other accelerators and the results are as follows:
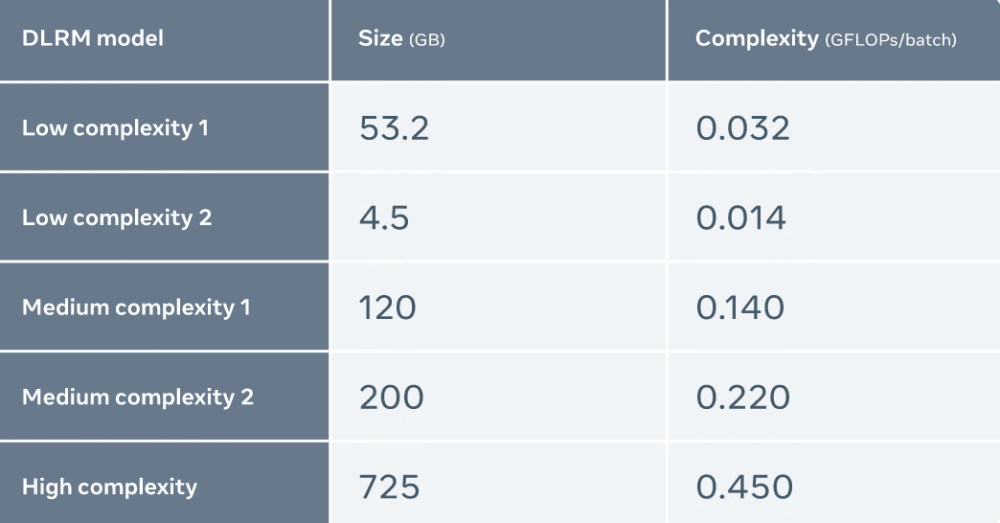
Meta uses five different DLRMs (from low to high complexity) to evaluate MTIA
In addition, Meta also compared MTIA with NNPI and GPU, and the results are as follows:

The evaluation found that MTIA is more efficient at processing low-complexity (LC1 and LC2) and medium-complexity (MC1 and MC2) models than NNPI and GPU. In addition, Meta has not been optimized for MTIA for high complexity (HC) models.
Reference link:
https://ai.facebook.com/blog/meta-training-inference-accelerator-AI-MTIA/
The above is the detailed content of 7nm process, more efficient than GPU, Meta releases first-generation AI inference accelerator. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
How to Use DALL-E 3: Tips, Examples, and Features
Mar 09, 2025 pm 01:00 PM
DALL-E 3: A Generative AI Image Creation Tool Generative AI is revolutionizing content creation, and DALL-E 3, OpenAI's latest image generation model, is at the forefront. Released in October 2023, it builds upon its predecessors, DALL-E and DALL-E 2
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Elon Musk & Sam Altman Clash over $500 Billion Stargate Project
Mar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman Clash over $500 Billion Stargate Project
Mar 08, 2025 am 11:15 AM
The $500 billion Stargate AI project, backed by tech giants like OpenAI, SoftBank, Oracle, and Nvidia, and supported by the U.S. government, aims to solidify American AI leadership. This ambitious undertaking promises a future shaped by AI advanceme
 Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google DeepMind's GenCast: A Revolutionary AI for Weather Forecasting Weather forecasting has undergone a dramatic transformation, moving from rudimentary observations to sophisticated AI-powered predictions. Google DeepMind's GenCast, a groundbreak
 Sora vs Veo 2: Which One Creates More Realistic Videos?
Mar 10, 2025 pm 12:22 PM
Sora vs Veo 2: Which One Creates More Realistic Videos?
Mar 10, 2025 pm 12:22 PM
Google's Veo 2 and OpenAI's Sora: Which AI video generator reigns supreme? Both platforms generate impressive AI videos, but their strengths lie in different areas. This comparison, using various prompts, reveals which tool best suits your needs. T
 Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
The article discusses AI models surpassing ChatGPT, like LaMDA, LLaMA, and Grok, highlighting their advantages in accuracy, understanding, and industry impact.(159 characters)
