

What is the entire process of executing a statement in Mysql?

1. The logical architecture of Mysql
The logical architecture of Mysql is as follows. The whole is divided into two parts, the Server layer and the storage engine layer.
Operations unrelated to the storage engine are completed at the Server layer, and the storage engine layer is responsible for data access.
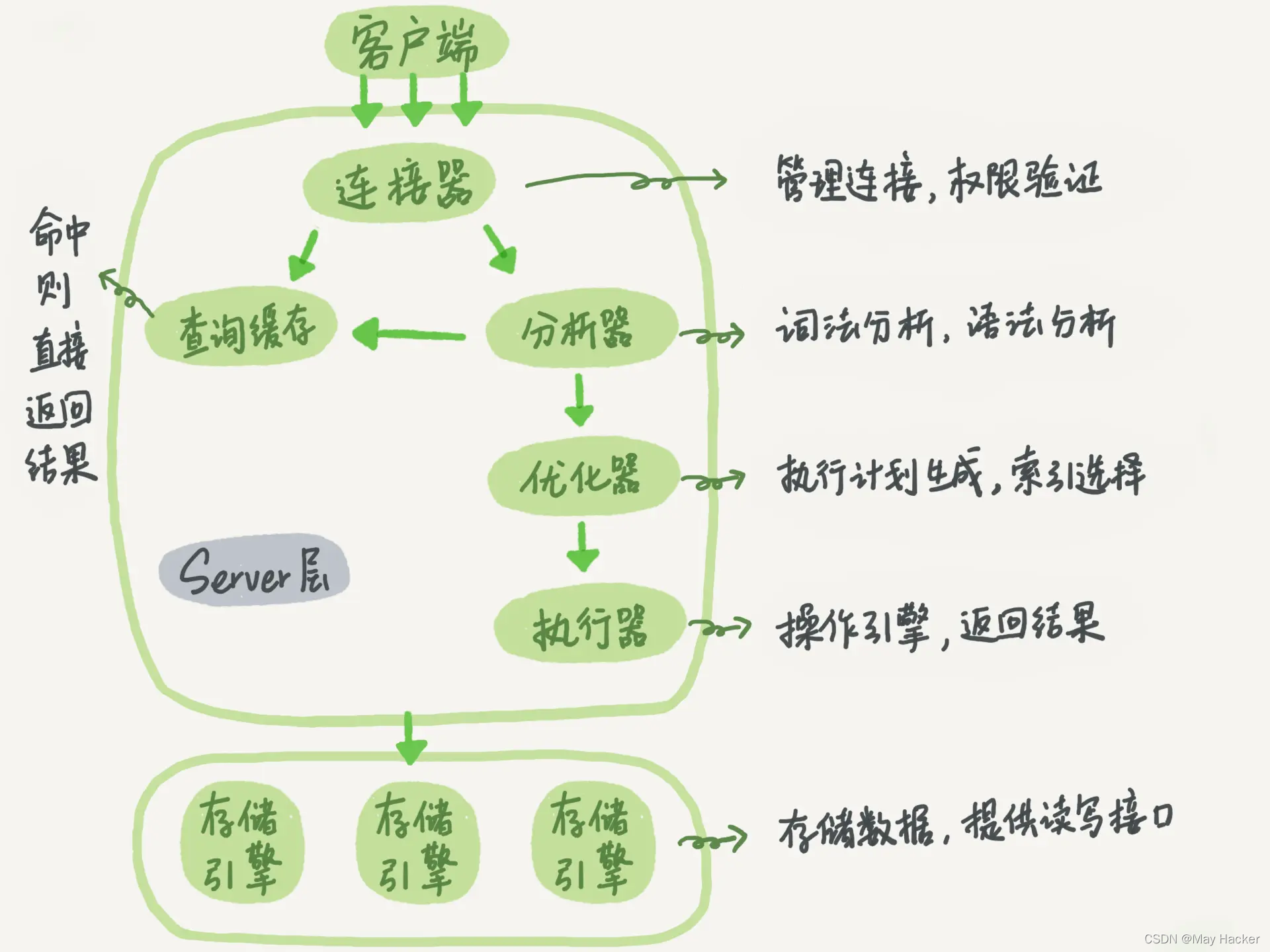
The following will introduce the function of each step according to the process in the above figure. Here we take querying a record as an example.
2. Connector
This step is mainly to manage connections and permission verification.
is responsible for managing the client's connection, such as mysql -u root -p, which is done between the client and the connector. The connection is divided into long connection and short connection. It is recommended to use long connection , because establishing a connection is a relatively complicated process. However, long connections also have room for optimization. That is, if there are too many long connections, more memory will be occupied as large query operations are executed.
After the connection is established, the connector will determine the user's permissions, and then the user's operations will be determined based on permissions to determine whether they are allowed.
3. Analyzer
This step is mainly lexical analysis and syntax analysis.
Lexical analysis is mainly used to determine what the user wants to do. For example, select means to query.
Grammar analysis is mainly to determine whether the SQL entered by the user conforms to the syntax of Mysql.
4. Optimizer
After the analyzer, Mysql already knows what the user wants to do, but for the same SQL statement, there may be many ways to implement it in Mysql Implementation and efficiency are also different.
In the optimizer step, mysql needs to determine how to execute for optimal efficiency.
5. Executor
This step is mainly to operate the engine and return results. Operate the storage engine layer to traverse the data table, find data that meets the criteria and return it to the client.
6.Mysql process of executing an update statement
The same as a SQL query statement, Mysql also needs to go through the connector, analyzer, optimizer, and executor, as well as A storage engine is used to access data.
The difference is that the update statement needs to involve two important log modules, redo log and binlog
7.redo log
A restaurant's business is booming, but as a restaurant, it is inevitable to have credit accounts and debt repayments every day.
If there are a large number of credit accounts and debt repayments, the boss will not be able to use a pink board to record one month's credit records.
So the boss thought that he could write all the credit records in the ledger, and what was written on the pink board were for a short period of time. After get off work, he would use the pink board to reconcile the ledger.
In this example, the pink board is redo log, and the ledger is the record in mysql. Let’s use the repayment analogy to compare the update process of mysql. If someone updates it every time, we will This record was found in mysql, and the efficiency is very low, so mysql's idea is consistent with this boss. The update operation is first placed in redo log, and then slowly digested after a while.
This idea is called WAL technology, that is, Write Ahead Logging technology, which writes the log first and then writes to the disk.
The boss must stop what he is doing if the pink board is full and the boss has not left work yet. The redo log in mysql can record a total of 4GB of operations
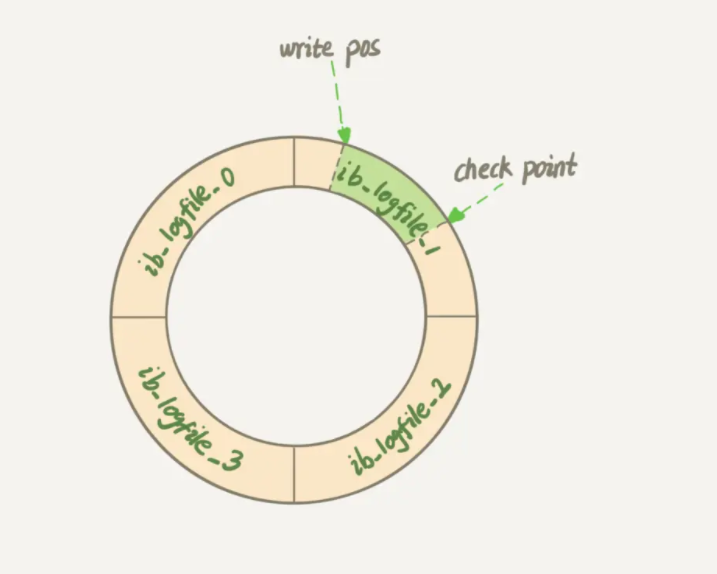
When write pos catches up with check point, the boss of mysql will have to deal with the redo log .
In addition, with redo log persistence, the database will not lose logs even if it restarts abnormally. This is the crash safe mechanism, but it still needs Note that redo log is unique to the innodb storage engine.
8.bin log
Binlog is the server layer log and can be applied to all storage engines.
Now that there is a binlog, why do we need to create a redo log exclusive to the innodb storage engine?
Because mysql did not have an innodb engine at the beginning, but the myisam engine, which used binlog, but the binlog was limited to archiving and did not have a crash safe mechanism, so I added a redo log.
redo log is unique to the innodb storage engine, while binlog is unique to the server layer
redo log stores physical logs, and binlog is Logical log
The redo log, as mentioned above, supports 4GB in size. If there is more, it must be processed and overwritten. The binlog log should be filled with one log
## After the
The following takes the update of a row of data with ID 2 as an example:
The light box in the figure indicates that it is executed inside InnoDB, and the dark box indicates that it is executed executed in the server.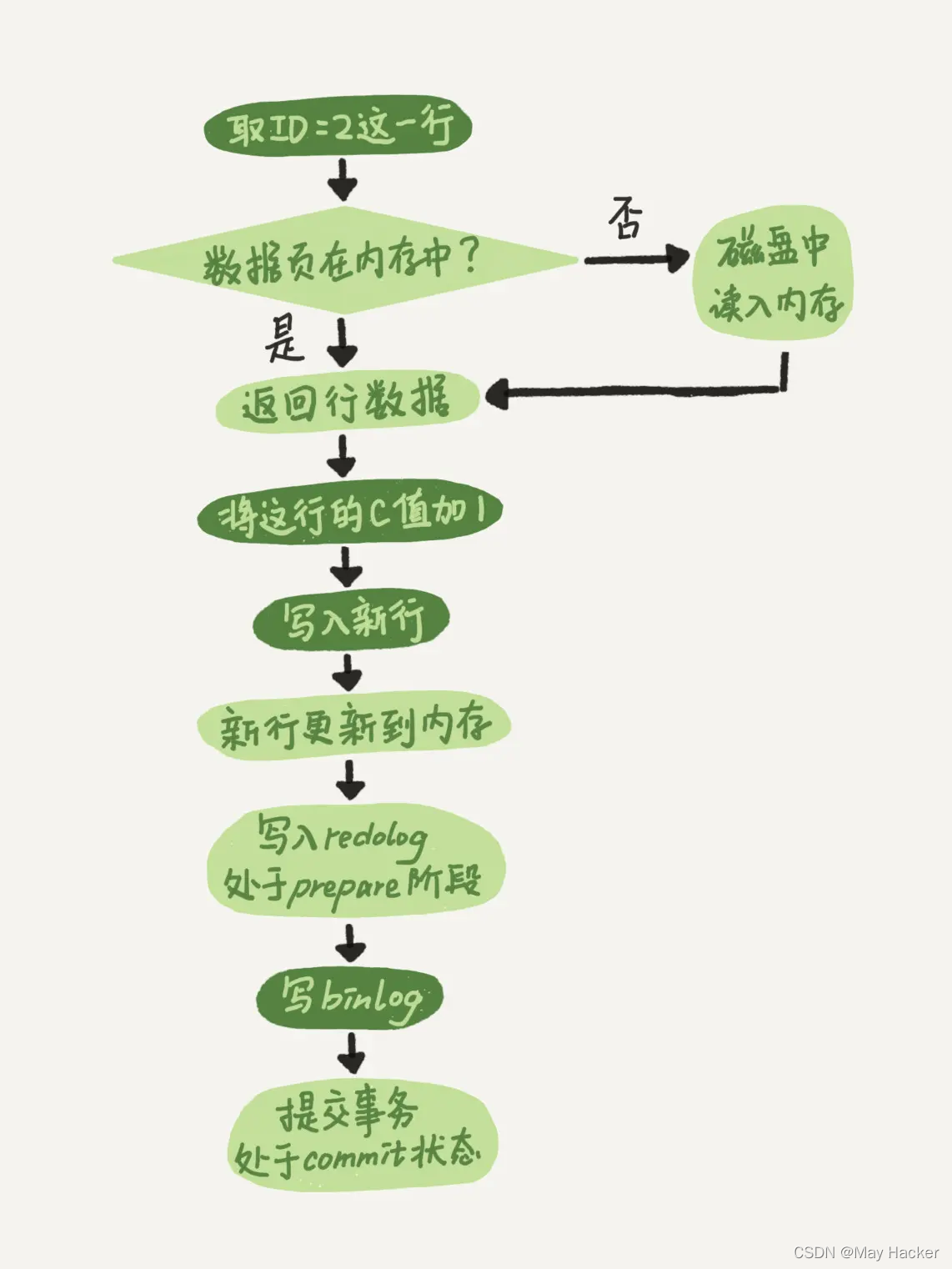
The executor first looks for the engine to get the line ID=2. ID is the primary key, and the engine directly uses tree search to find this row. If the data page where the ID=2 row is located is already in the memory, it will be returned directly to the executor; otherwise, it needs to be read into the memory from the disk and then returned.
The executor gets the row data given by the engine, adds 1 to this value, for example, it used to be N, but now it is N 1, gets a new row of data, and then calls the engine interface to write Enter this row of new data.
The engine updates this new row of data into the memory and records the update operation into the redo log. At this time, the redo log is in the prepare state. Then inform the executor that the execution is completed and the transaction can be submitted at any time. During the execution of the operation, the executor generates a binlog and writes it to disk.
The executor calls the engine's commit transaction interface, and the engine changes the redo log just written to the commit state, and the update is completed.
The above is the detailed content of What is the entire process of executing a statement in Mysql?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 PHP's big data structure processing skills
May 08, 2024 am 10:24 AM
PHP's big data structure processing skills
May 08, 2024 am 10:24 AM
Big data structure processing skills: Chunking: Break down the data set and process it in chunks to reduce memory consumption. Generator: Generate data items one by one without loading the entire data set, suitable for unlimited data sets. Streaming: Read files or query results line by line, suitable for large files or remote data. External storage: For very large data sets, store the data in a database or NoSQL.
 How to use MySQL backup and restore in PHP?
Jun 03, 2024 pm 12:19 PM
How to use MySQL backup and restore in PHP?
Jun 03, 2024 pm 12:19 PM
Backing up and restoring a MySQL database in PHP can be achieved by following these steps: Back up the database: Use the mysqldump command to dump the database into a SQL file. Restore database: Use the mysql command to restore the database from SQL files.
 How to optimize MySQL query performance in PHP?
Jun 03, 2024 pm 08:11 PM
How to optimize MySQL query performance in PHP?
Jun 03, 2024 pm 08:11 PM
MySQL query performance can be optimized by building indexes that reduce lookup time from linear complexity to logarithmic complexity. Use PreparedStatements to prevent SQL injection and improve query performance. Limit query results and reduce the amount of data processed by the server. Optimize join queries, including using appropriate join types, creating indexes, and considering using subqueries. Analyze queries to identify bottlenecks; use caching to reduce database load; optimize PHP code to minimize overhead.
 How to insert data into a MySQL table using PHP?
Jun 02, 2024 pm 02:26 PM
How to insert data into a MySQL table using PHP?
Jun 02, 2024 pm 02:26 PM
How to insert data into MySQL table? Connect to the database: Use mysqli to establish a connection to the database. Prepare the SQL query: Write an INSERT statement to specify the columns and values to be inserted. Execute query: Use the query() method to execute the insertion query. If successful, a confirmation message will be output.
 How to create a MySQL table using PHP?
Jun 04, 2024 pm 01:57 PM
How to create a MySQL table using PHP?
Jun 04, 2024 pm 01:57 PM
Creating a MySQL table using PHP requires the following steps: Connect to the database. Create the database if it does not exist. Select a database. Create table. Execute the query. Close the connection.
 How to use MySQL stored procedures in PHP?
Jun 02, 2024 pm 02:13 PM
How to use MySQL stored procedures in PHP?
Jun 02, 2024 pm 02:13 PM
To use MySQL stored procedures in PHP: Use PDO or the MySQLi extension to connect to a MySQL database. Prepare the statement to call the stored procedure. Execute the stored procedure. Process the result set (if the stored procedure returns results). Close the database connection.
 How to fix mysql_native_password not loaded errors on MySQL 8.4
Dec 09, 2024 am 11:42 AM
How to fix mysql_native_password not loaded errors on MySQL 8.4
Dec 09, 2024 am 11:42 AM
One of the major changes introduced in MySQL 8.4 (the latest LTS release as of 2024) is that the "MySQL Native Password" plugin is no longer enabled by default. Further, MySQL 9.0 removes this plugin completely. This change affects PHP and other app
 The difference between oracle database and mysql
May 10, 2024 am 01:54 AM
The difference between oracle database and mysql
May 10, 2024 am 01:54 AM
Oracle database and MySQL are both databases based on the relational model, but Oracle is superior in terms of compatibility, scalability, data types and security; while MySQL focuses on speed and flexibility and is more suitable for small to medium-sized data sets. . ① Oracle provides a wide range of data types, ② provides advanced security features, ③ is suitable for enterprise-level applications; ① MySQL supports NoSQL data types, ② has fewer security measures, and ③ is suitable for small to medium-sized applications.
