

Use the import wizard function of the navicat tool. This software can support a variety of file formats, and can automatically create tables based on file fields or insert data into existing tables, which is very fast and convenient.
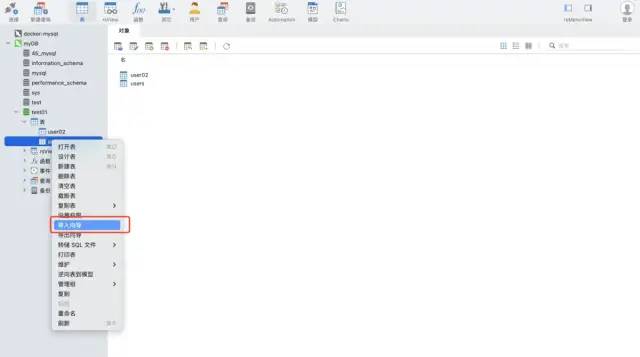
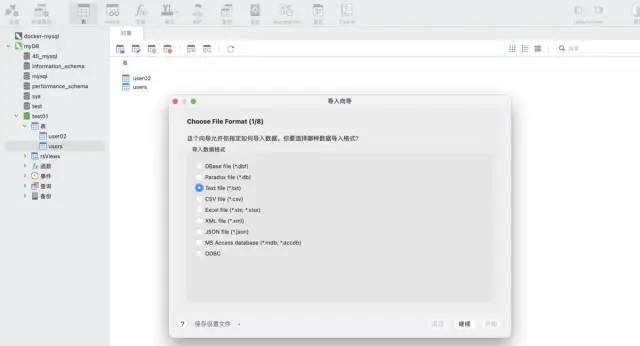
test Data: csv format, about 12 million rows
import pandas as pd data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.shape
Print results:

##Method 1:python ➕ pymysql library
Install pymysql command:
pip install pymysql
Code implementation:
import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')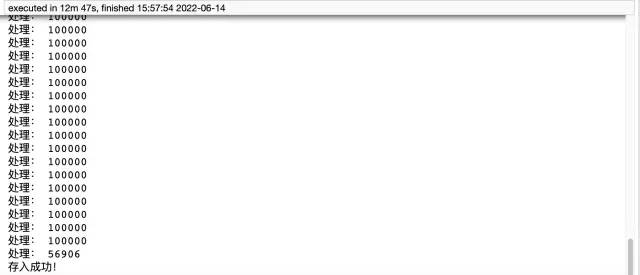
Method 2: pandas ➕ sqlalchemy: pandas needs to introduce sqlalchemy to support sql. With the support of sqlalchemy, it can implement queries, updates and other operations of all common database types.
Code implementation:
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01') data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.to_sql('user02',engine,chunksize=100000,index=None) print('存入成功!')
The three most complete methods of storing data into the MySQL database:
The above is the detailed content of How to use Python to read tens of millions of data and automatically write it to a MySQL database. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



