What is the MVCC principle of MySQL InnoDB?


MVCC's full name is Multi-Version Concurrency Control, which is multi-version concurrency control, mainly to improve the concurrency performance of the database. When a read or write request occurs for the same row of data, it will be locked and blocked. MVCC uses a more optimized method to handle read and write requests, and can handle read and write request conflicts without locking. This refers to snapshot reading, not current reading, which is a pessimistic locking mechanism. We will learn in the following studies how to perform read and write operations without locking, and the concepts of snapshot read and current read will also be analyzed.
MySQL can largely avoid phantom read problems under the REPEATABLE READ isolation level. How does MySQL do this?
Version chain
We know that for tables using the InnoDB storage engine, its clustered index records contain two necessary hidden columns (row_id It is not necessary. The row_id column will not be included when the table we create has a primary key or a non-NULL UNIQUE key):
trx_id: Each time a transaction clusters a certain When the index record is modified, the transaction ID of the transaction will be assigned to the trx_id hidden column.
roll_pointer: Every time a clustered index record is changed, the old version will be written to the undo log, and then this hidden column is equivalent to a pointer. Use it to find the information before the record was modified.
In order to illustrate this problem, we create a demonstration table:
CREATE TABLE `teacher` ( `number` int(11) NOT NULL, `name` varchar(100) DEFAULT NULL, `domain` varchar(100) DEFAULT NULL, PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
Then insert a piece of data into this table:
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
The current data This is it:
mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | J | Java | +--------+------+--------+ 1 row in set (0.00 sec)
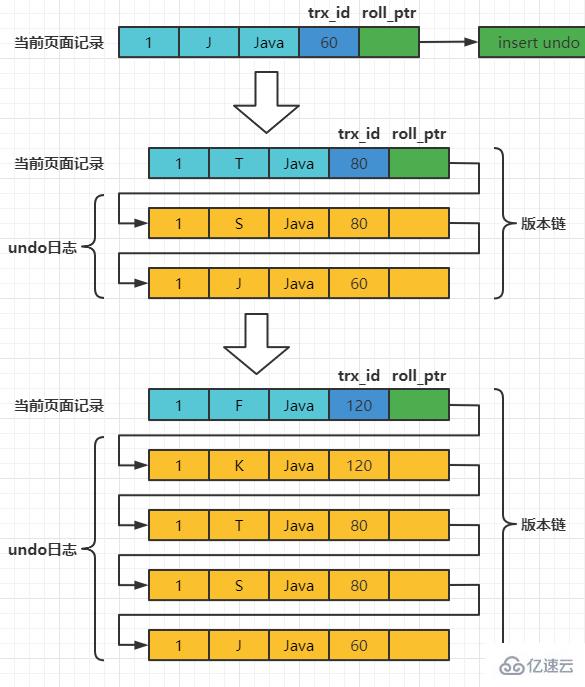
Assume that the transaction ID of inserting the record is 60, then the diagram of the record at this moment is as follows:

Assume that the next two A transaction with transaction IDs of 80 and 120 performs an UPDATE operation on this record. The operation process is as follows:
| Trx80 | Trx120 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| begin | ||||||||||||||
| ##commit | ||||||||||||||
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id。于是可以利用这个记录的版本链来控制并发事务访问相同记录的行为,那么这种机制就被称之为多版本并发控制(Mulit-Version Concurrency Control MVCC)。 ReadView对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。 对于使用SERIALIZABLE隔离级别的事务来说,InnoDB使用加锁的方式来访问记录。 对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:READ COMMITTED和REPEATABLE READ隔离级别在不可重复读和幻读上的区别,这两种隔离级别关键是需要判断一下版本链中的哪个版本是当前事务可见的。 为此,InnoDB提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
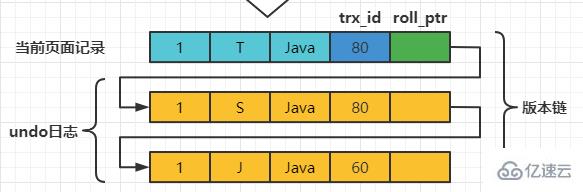
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。 我们还是以表teacher为例,假设现在表teacher中只有一条由事务id为60的事务插入的一条记录,接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。 READ COMMITTED每次读取数据前都生成一个ReadView假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 set session transaction isolation level read committed; begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; Copy after login 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行: set session transaction isolation level read committed; # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' Copy after login 这个SELECE1的执行过程如下:
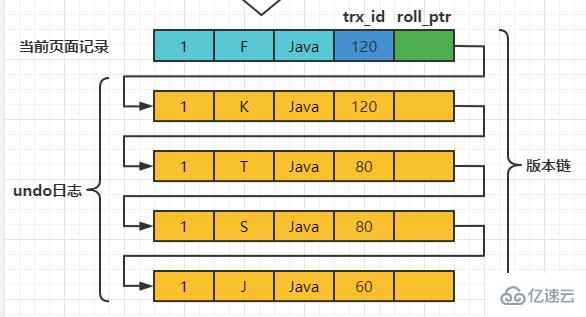
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: set session transaction isolation level read committed; # Transaction 120 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; Copy after login 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number 为1的记录,如下: # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'T' Copy after login 这个SELECE2 的执行过程如下:
以此类推,如果之后事务id为120的记录也提交了,再次在使用READCOMMITTED隔离级别的事务中查询表teacher中number值为1的记录时,得到的结果就是’F’了,具体流程我们就不分析了。 总结一下就是:使用READCOMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。 REPEATABLE READ —— 在第一次读取数据时生成一个ReadView对于使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。 假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; Copy after login 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' Copy after login 这个SELECE1的执行过程如下(与READ COMMITTED的过程一致):
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: # Transaction 80 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; Copy after login 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' Copy after login 这个SELECE2的执行过程如下:
可重复读的意思是两次SELECT查询的结果相同,记录的列值均为'J'。 如果我们之后再把事务id为120的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,得到的结果还是’J’,具体执行过程大家可以自己分析一下。 MVCC下的幻读现象和幻读解决前面我们已经知道了,REPEATABLE READ隔离级别下MVCC可以解决不可重复读问题,那么幻读呢?MVCC是怎么解决的?幻读是一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录,而这个记录来自另一个事务添加的新记录。 我们可以想想,在REPEATABLE READ隔离级别下的事务T1先根据某个搜索条件读取到多条记录,然后事务T2插入一条符合相应搜索条件的记录并提交,然后事务T1再根据相同搜索条件执行查询。结果会是什么?按照ReadView中的比较规则: 无论事务T2是否先于事务T1开启,事务T1都无法观察到T2的提交。请根据以上所述的版本历史、阅读视图与可视性判断规则,自行进行分析。 但是,在REPEATABLE READ隔离级别下InnoDB中的MVCC可以很大程度地避免幻读现象,而不是完全禁止幻读。怎么回事呢?我们来看下面的情况:
Well, what's going on? Transaction T1 obviously has a phantom read phenomenon. Under the REPEATABLE READ isolation level, T1 generates a ReadView when executing a normal SELECT statement for the first time, and then T2 inserts a new record into the teacher table and submits it. ReadView cannot prevent T1 from executing the UPDATE or DELETE statement to modify the newly inserted record (since T2 has already submitted, changing the record will not cause blocking), but in this way, the value of the trx_id hidden column of this new record will be It becomes the transaction id of T1. After that, T1 can see this record when it uses an ordinary SELECT statement to query this record, and can return this record to the client. MVCC cannot completely eliminate phantom reads because of the existence of this special phenomenon. MVCC SummaryWe can see from the above description that the so-called MVCC (Multi-Version ConcurrencyControl, multi-version concurrency control) refers to the use of READ COMMITTD and REPEATABLE READ. This isolation level transaction accesses the recorded version chain when performing a normal SELECT operation. This allows read-write and write-read operations of different transactions to be executed concurrently, thus improving system performance. A big difference between the two isolation levels of READ COMMITTD and REPEATABLE READ is that the timing of generating ReadView is different. READ COMMITTD will generate a ReadView before each ordinary SELECT operation, while REPEATABLE READ will only generate a ReadView after the normal SELECT operation. Just generate a ReadView before performing a normal SELECT operation, and reuse this ReadView for subsequent query operations, thus basically avoiding the phenomenon of phantom reading. We said before that executing a DELETE statement or an UPDATE statement that updates the primary key will not immediately completely delete the corresponding record from the page. Instead, it will perform a so-called delete mark operation, which is equivalent to just marking the record with a mark. Delete the flag bit, which mainly serves MVCC. In addition, the so-called MVCC only takes effect when we perform ordinary SEELCT queries. All SELECT statements we have seen so far are ordinary queries. As for what is an extraordinary query, we will talk about it later. The above is the detailed content of What is the MVCC principle of MySQL InnoDB?. For more information, please follow other related articles on the PHP Chinese website! Statement of this Website
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn

Hot AI Tools
Undresser.AI UndressAI-powered app for creating realistic nude photos 
AI Clothes RemoverOnline AI tool for removing clothes from photos. 
Undress AI ToolUndress images for free 
Clothoff.ioAI clothes remover 
AI Hentai GeneratorGenerate AI Hentai for free. 
Hot Article
R.E.P.O. Energy Crystals Explained and What They Do (Yellow Crystal)
3 weeks ago
By 尊渡假赌尊渡假赌尊渡假赌
R.E.P.O. Best Graphic Settings
3 weeks ago
By 尊渡假赌尊渡假赌尊渡假赌
Assassin's Creed Shadows: Seashell Riddle Solution
1 weeks ago
By DDD
R.E.P.O. How to Fix Audio if You Can't Hear Anyone
3 weeks ago
By 尊渡假赌尊渡假赌尊渡假赌
Where to find the Crane Control Keycard in Atomfall
1 weeks ago
By DDD
Hot Tools
Notepad++7.3.1Easy-to-use and free code editor 
SublimeText3 Chinese versionChinese version, very easy to use 
Zend Studio 13.0.1Powerful PHP integrated development environment 
Dreamweaver CS6Visual web development tools 
SublimeText3 Mac versionGod-level code editing software (SublimeText3)
Hot Topics
CakePHP Tutorial
 1371
1371
 52
52
 Unable to log in to mysql as root
Apr 08, 2025 pm 04:54 PM
Unable to log in to mysql as root
Apr 08, 2025 pm 04:54 PM
The main reasons why you cannot log in to MySQL as root are permission problems, configuration file errors, password inconsistent, socket file problems, or firewall interception. The solution includes: check whether the bind-address parameter in the configuration file is configured correctly. Check whether the root user permissions have been modified or deleted and reset. Verify that the password is accurate, including case and special characters. Check socket file permission settings and paths. Check that the firewall blocks connections to the MySQL server.  mysql whether to change table lock table
Apr 08, 2025 pm 05:06 PM
mysql whether to change table lock table
Apr 08, 2025 pm 05:06 PM
When MySQL modifys table structure, metadata locks are usually used, which may cause the table to be locked. To reduce the impact of locks, the following measures can be taken: 1. Keep tables available with online DDL; 2. Perform complex modifications in batches; 3. Operate during small or off-peak periods; 4. Use PT-OSC tools to achieve finer control.  The relationship between mysql user and database
Apr 08, 2025 pm 07:15 PM
The relationship between mysql user and database
Apr 08, 2025 pm 07:15 PM
In MySQL database, the relationship between the user and the database is defined by permissions and tables. The user has a username and password to access the database. Permissions are granted through the GRANT command, while the table is created by the CREATE TABLE command. To establish a relationship between a user and a database, you need to create a database, create a user, and then grant permissions.  Query optimization in MySQL is essential for improving database performance, especially when dealing with large data sets
Apr 08, 2025 pm 07:12 PM
Query optimization in MySQL is essential for improving database performance, especially when dealing with large data sets
Apr 08, 2025 pm 07:12 PM
1. Use the correct index to speed up data retrieval by reducing the amount of data scanned select*frommployeeswherelast_name='smith'; if you look up a column of a table multiple times, create an index for that column. If you or your app needs data from multiple columns according to the criteria, create a composite index 2. Avoid select * only those required columns, if you select all unwanted columns, this will only consume more server memory and cause the server to slow down at high load or frequency times For example, your table contains columns such as created_at and updated_at and timestamps, and then avoid selecting * because they do not require inefficient query se  Can mysql run on android
Apr 08, 2025 pm 05:03 PM
Can mysql run on android
Apr 08, 2025 pm 05:03 PM
MySQL cannot run directly on Android, but it can be implemented indirectly by using the following methods: using the lightweight database SQLite, which is built on the Android system, does not require a separate server, and has a small resource usage, which is very suitable for mobile device applications. Remotely connect to the MySQL server and connect to the MySQL database on the remote server through the network for data reading and writing, but there are disadvantages such as strong network dependencies, security issues and server costs.  Do mysql need to pay
Apr 08, 2025 pm 05:36 PM
Do mysql need to pay
Apr 08, 2025 pm 05:36 PM
MySQL has a free community version and a paid enterprise version. The community version can be used and modified for free, but the support is limited and is suitable for applications with low stability requirements and strong technical capabilities. The Enterprise Edition provides comprehensive commercial support for applications that require a stable, reliable, high-performance database and willing to pay for support. Factors considered when choosing a version include application criticality, budgeting, and technical skills. There is no perfect option, only the most suitable option, and you need to choose carefully according to the specific situation.  How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
How to optimize MySQL performance for high-load applications?
Apr 08, 2025 pm 06:03 PM
MySQL database performance optimization guide In resource-intensive applications, MySQL database plays a crucial role and is responsible for managing massive transactions. However, as the scale of application expands, database performance bottlenecks often become a constraint. This article will explore a series of effective MySQL performance optimization strategies to ensure that your application remains efficient and responsive under high loads. We will combine actual cases to explain in-depth key technologies such as indexing, query optimization, database design and caching. 1. Database architecture design and optimized database architecture is the cornerstone of MySQL performance optimization. Here are some core principles: Selecting the right data type and selecting the smallest data type that meets the needs can not only save storage space, but also improve data processing speed.  RDS MySQL integration with Redshift zero ETL
Apr 08, 2025 pm 07:06 PM
RDS MySQL integration with Redshift zero ETL
Apr 08, 2025 pm 07:06 PM
Data Integration Simplification: AmazonRDSMySQL and Redshift's zero ETL integration Efficient data integration is at the heart of a data-driven organization. Traditional ETL (extract, convert, load) processes are complex and time-consuming, especially when integrating databases (such as AmazonRDSMySQL) with data warehouses (such as Redshift). However, AWS provides zero ETL integration solutions that have completely changed this situation, providing a simplified, near-real-time solution for data migration from RDSMySQL to Redshift. This article will dive into RDSMySQL zero ETL integration with Redshift, explaining how it works and the advantages it brings to data engineers and developers. 
|