

How to implement Redis BloomFilter Bloom filter

Bloom Filter Concept
A man named Bloom proposed the Bloom filter (English name: Bloom Filter) in 1970. It's actually a long binary vector and a series of random mapping functions. Bloom filters can be used to retrieve whether an element is in a collection. Its advantage is that space efficiency and query time are far higher than those of ordinary algorithms. Its disadvantage is that it has a certain misrecognition rate and difficulty in deletion.
Bloom Filter Principle
The principle of the Bloom filter is that when an element is added to the set, the element is mapped into K points in a bit array through K hash functions. , set them to 1. When retrieving, we only need to look at whether these points are all 1 to (approximately) know whether it is in the set: if any of these points has 0, then the checked element must not be there; if they are all 1, then the checked element Most likely. This is the basic idea of Bloom filter.
The difference between Bloom Filter and single hash function Bit-Map is that Bloom Filter uses k hash functions, and each string corresponds to k bits. Thereby reducing the probability of conflict
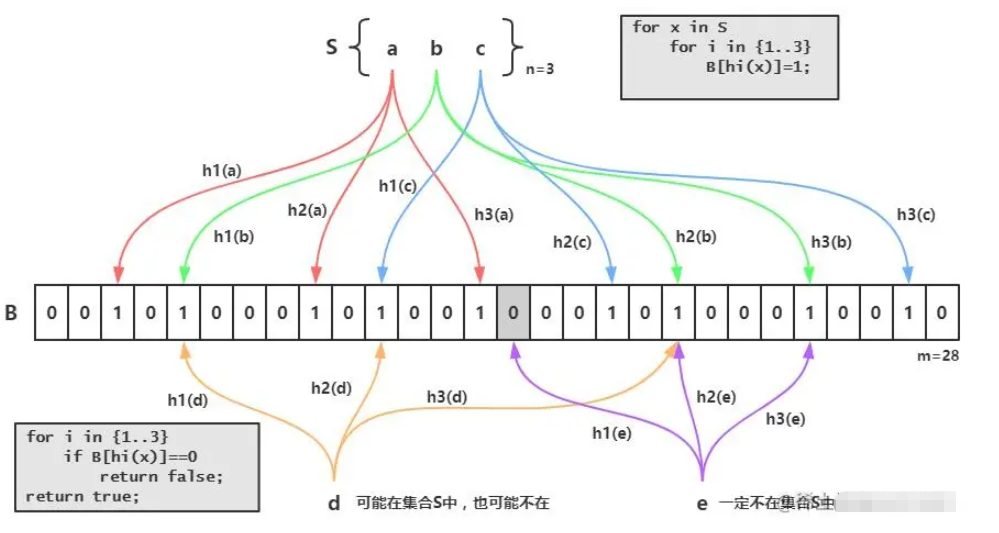
Cache penetration
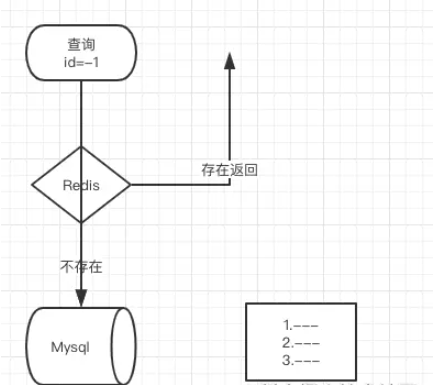
In short, in a nutshell, we first load all the data from our database into our filter. For example, the id of the database now has: 1, 2, 3 Then use id: 1 is an example. After hashing three times in the above picture, he changed the three places where the original value was 0 to 1. The next time the data comes in for query, if the value of id is 1, then I will change it to 1. Take three hashes and find that the values of the three hashes are exactly the same as the three positions above, which can prove that there is 1 in the filter. On the contrary, if they are different, it means that it does not exist So where are the application scenarios? Generally we will use it to prevent cache breakdownTo put it simply, the id of your database starts with 1 and then increases by itself. Then I know that your interface is queried by id, so I will use negative numbers to query. At this time, you will find that the data is not in the cache, and I go to the database to check it, but it is not found. One request is like this, what about 100, 1,000, or 10,000? Basically your DB can't handle it. If you add this to the cache, it will no longer exist. If you judge that there is no such data, you won't check it. Wouldn't it be better to just return the data as empty? If this thing is so good, what are the drawbacks? Yes, let’s go on to see Disadvantages of Bloom FilterThe reason why bloom filter can be more efficient in time and space is because it sacrifices the accuracy of judgment. Convenience of deletionAlthough the container may not contain the elements that should be searched, due to the hash operation, the values of these elements in k hash positions are all 1, so it may lead to misjudgment. By establishing a whitelist to store elements that may be misjudged, when the Bloom Filter stores a blacklist, the misjudgement rate can be reduced. Deletion is difficult. An element placed in the container is mapped to 1 in the k positions of the bit array. When deleting, it cannot be simply set to 0 directly, as it may affect the judgment of other elements. You can use Counting Bloom FilterFAQ1. Why use multiple hash functions? If only one hash function is used, the Hash itself will often conflict. For example, for an array with a length of 100, if only one hash function is used, after adding one element, the probability of conflict when adding the second element is 1%, and the probability of conflict when adding the third element is 2%... But if two elements are used, the probability of collision is 1%. A hash function, after adding an element, the probability of conflict when adding the second element is reduced to 4 out of 10,000 (four possible conflict situations, total number of situations 100x100) go language implementation
package main
import (
"fmt"
"github.com/bits-and-blooms/bitset"
)
//设置哈希数组默认大小为16
const DefaultSize = 16
//设置种子,保证不同哈希函数有不同的计算方式
var seeds = []uint{7, 11, 13, 31, 37, 61}
//布隆过滤器结构,包括二进制数组和多个哈希函数
type BloomFilter struct {
//使用第三方库
set *bitset.BitSet
//指定长度为6
hashFuncs [6]func(seed uint, value string) uint
}
//构造一个布隆过滤器,包括数组和哈希函数的初始化
func NewBloomFilter() *BloomFilter {
bf := new(BloomFilter)
bf.set = bitset.New(DefaultSize)
for i := 0; i < len(bf.hashFuncs); i++ {
bf.hashFuncs[i] = createHash()
}
return bf
}
//构造6个哈希函数,每个哈希函数有参数seed保证计算方式的不同
func createHash() func(seed uint, value string) uint {
return func(seed uint, value string) uint {
var result uint = 0
for i := 0; i < len(value); i++ {
result = result*seed + uint(value[i])
}
//length = 2^n 时,X % length = X & (length - 1)
return result & (DefaultSize - 1)
}
}
//添加元素
func (b *BloomFilter) add(value string) {
for i, f := range b.hashFuncs {
//将哈希函数计算结果对应的数组位置1
b.set.Set(f(seeds[i], value))
}
}
//判断元素是否存在
func (b *BloomFilter) contains(value string) bool {
//调用每个哈希函数,并且判断数组对应位是否为1
//如果不为1,直接返回false,表明一定不存在
for i, f := range b.hashFuncs {
//result = result && b.set.Test(f(seeds[i], value))
if !b.set.Test(f(seeds[i], value)) {
return false
}
}
return true
}
func main() {
filter := NewBloomFilter()
filter.add("asd")
fmt.Println(filter.contains("asd"))
fmt.Println(filter.contains("2222"))
fmt.Println(filter.contains("155343"))
}Copy after login
The output results are as follows:
package main
import (
"fmt"
"github.com/bits-and-blooms/bitset"
)
//设置哈希数组默认大小为16
const DefaultSize = 16
//设置种子,保证不同哈希函数有不同的计算方式
var seeds = []uint{7, 11, 13, 31, 37, 61}
//布隆过滤器结构,包括二进制数组和多个哈希函数
type BloomFilter struct {
//使用第三方库
set *bitset.BitSet
//指定长度为6
hashFuncs [6]func(seed uint, value string) uint
}
//构造一个布隆过滤器,包括数组和哈希函数的初始化
func NewBloomFilter() *BloomFilter {
bf := new(BloomFilter)
bf.set = bitset.New(DefaultSize)
for i := 0; i < len(bf.hashFuncs); i++ {
bf.hashFuncs[i] = createHash()
}
return bf
}
//构造6个哈希函数,每个哈希函数有参数seed保证计算方式的不同
func createHash() func(seed uint, value string) uint {
return func(seed uint, value string) uint {
var result uint = 0
for i := 0; i < len(value); i++ {
result = result*seed + uint(value[i])
}
//length = 2^n 时,X % length = X & (length - 1)
return result & (DefaultSize - 1)
}
}
//添加元素
func (b *BloomFilter) add(value string) {
for i, f := range b.hashFuncs {
//将哈希函数计算结果对应的数组位置1
b.set.Set(f(seeds[i], value))
}
}
//判断元素是否存在
func (b *BloomFilter) contains(value string) bool {
//调用每个哈希函数,并且判断数组对应位是否为1
//如果不为1,直接返回false,表明一定不存在
for i, f := range b.hashFuncs {
//result = result && b.set.Test(f(seeds[i], value))
if !b.set.Test(f(seeds[i], value)) {
return false
}
}
return true
}
func main() {
filter := NewBloomFilter()
filter.add("asd")
fmt.Println(filter.contains("asd"))
fmt.Println(filter.contains("2222"))
fmt.Println(filter.contains("155343"))
}truefalse
false
The above is the detailed content of How to implement Redis BloomFilter Bloom filter. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Solution to 0x80242008 error when installing Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
Solution to 0x80242008 error when installing Windows 11 10.0.22000.100
May 08, 2024 pm 03:50 PM
1. Start the [Start] menu, enter [cmd], right-click [Command Prompt], and select Run as [Administrator]. 2. Enter the following commands in sequence (copy and paste carefully): SCconfigwuauservstart=auto, press Enter SCconfigbitsstart=auto, press Enter SCconfigcryptsvcstart=auto, press Enter SCconfigtrustedinstallerstart=auto, press Enter SCconfigwuauservtype=share, press Enter netstopwuauserv , press enter netstopcryptS
 Golang API caching strategy and optimization
May 07, 2024 pm 02:12 PM
Golang API caching strategy and optimization
May 07, 2024 pm 02:12 PM
The caching strategy in GolangAPI can improve performance and reduce server load. Commonly used strategies are: LRU, LFU, FIFO and TTL. Optimization techniques include selecting appropriate cache storage, hierarchical caching, invalidation management, and monitoring and tuning. In the practical case, the LRU cache is used to optimize the API for obtaining user information from the database. The data can be quickly retrieved from the cache. Otherwise, the cache can be updated after obtaining it from the database.
 Caching mechanism and application practice in PHP development
May 09, 2024 pm 01:30 PM
Caching mechanism and application practice in PHP development
May 09, 2024 pm 01:30 PM
In PHP development, the caching mechanism improves performance by temporarily storing frequently accessed data in memory or disk, thereby reducing the number of database accesses. Cache types mainly include memory, file and database cache. Caching can be implemented in PHP using built-in functions or third-party libraries, such as cache_get() and Memcache. Common practical applications include caching database query results to optimize query performance and caching page output to speed up rendering. The caching mechanism effectively improves website response speed, enhances user experience and reduces server load.
 How to upgrade Win11 English 21996 to Simplified Chinese 22000_How to upgrade Win11 English 21996 to Simplified Chinese 22000
May 08, 2024 pm 05:10 PM
How to upgrade Win11 English 21996 to Simplified Chinese 22000_How to upgrade Win11 English 21996 to Simplified Chinese 22000
May 08, 2024 pm 05:10 PM
First you need to set the system language to Simplified Chinese display and restart. Of course, if you have changed the display language to Simplified Chinese before, you can just skip this step. Next, start operating the registry, regedit.exe, directly navigate to HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsLanguage in the left navigation bar or the upper address bar, and then modify the InstallLanguage key value and Default key value to 0804 (if you want to change it to English en-us, you need First set the system display language to en-us, restart the system and then change everything to 0409) You must restart the system at this point.
 How to use Redis cache in PHP array pagination?
May 01, 2024 am 10:48 AM
How to use Redis cache in PHP array pagination?
May 01, 2024 am 10:48 AM
Using Redis cache can greatly optimize the performance of PHP array paging. This can be achieved through the following steps: Install the Redis client. Connect to the Redis server. Create cache data and store each page of data into a Redis hash with the key "page:{page_number}". Get data from cache and avoid expensive operations on large arrays.
 Can navicat connect to redis?
Apr 23, 2024 pm 05:12 PM
Can navicat connect to redis?
Apr 23, 2024 pm 05:12 PM
Yes, Navicat can connect to Redis, which allows users to manage keys, view values, execute commands, monitor activity, and diagnose problems. To connect to Redis, select the "Redis" connection type in Navicat and enter the server details.
 How to find the update file downloaded by Win11_Share the location of the update file downloaded by Win11
May 08, 2024 am 10:34 AM
How to find the update file downloaded by Win11_Share the location of the update file downloaded by Win11
May 08, 2024 am 10:34 AM
1. First, double-click the [This PC] icon on the desktop to open it. 2. Then double-click the left mouse button to enter [C drive]. System files will generally be automatically stored in C drive. 3. Then find the [windows] folder in the C drive and double-click to enter. 4. After entering the [windows] folder, find the [SoftwareDistribution] folder. 5. After entering, find the [download] folder, which contains all win11 download and update files. 6. If we want to delete these files, just delete them directly in this folder.
 PHP Redis caching applications and best practices
May 04, 2024 am 08:33 AM
PHP Redis caching applications and best practices
May 04, 2024 am 08:33 AM
Redis is a high-performance key-value cache. The PHPRedis extension provides an API to interact with the Redis server. Use the following steps to connect to Redis, store and retrieve data: Connect: Use the Redis classes to connect to the server. Storage: Use the set method to set key-value pairs. Retrieval: Use the get method to obtain the value of the key.
