
 Technology peripherals
AI
Ten minutes to understand the technical logic and evolution of ChatGPT (past life, present life)
Technology peripherals
AI
Ten minutes to understand the technical logic and evolution of ChatGPT (past life, present life)
Ten minutes to understand the technical logic and evolution of ChatGPT (past life, present life)

0. Foreword
On November 30, OpenAI launched an AI chatbot called ChatGPT, which can be tested by the public for free. It became popular on the entire network in just a few days.
Judging from the multiple publicity on headlines and public accounts, it can not only write code, check bugs, but also write novels and game planning, including writing applications to schools, etc. It seems to be omnipotent.
In the spirit of science (good) and learning (wonderful), I took some time to test and verify ChatGPT, and **sorted out why ChatGPT is so "strong"**.
Since the author has not studied AI professionally and has limited energy, there will be no more in-depth technical chapters like AI-003 in a short time. Understanding 001 and 002 is beyond ordinary eating. It is within the scope of the melon masses.
There will be many technical terms in this article, and I will try to reduce the difficulty of understanding them.
At the same time, since I am not an AI professional, please point out any errors or omissions.
Acknowledgments: Many thanks to classmates X and Z for their review, especially to classmate X for his professionalism
1. What is GPT
ChatGPT There are two words in it, one is Chat, which means that you can have a conversation. Another word is GPT.
The full name of GPT is Generative Pre-Trained Transformer (generative pre-training Transformer model).
You can see a total of 3 words in it, Generative, Pre-Trained, and Transformer.
Some readers may notice that I did not translate Transformer into Chinese above.
Because Transformer is a technical term, if it is hard translated, it is a transformer. But it is easy to lose the original meaning, so it is better not to translate it.
I will explain more about Transformer in Chapter 3 below.
2. GPT’s technology evolution timeline
The development history of GPT from its inception to the present is as follows:
In June 2017, Google published the paper "Attention is all you need" 》, first proposed the Transformer model, which became the basis for the development of GPT. Paper address: https://arxiv.org/abs/1706.03762
In June 2018, OpenAI released the paper "Improving Language Understanding by Generative Pre-Training" (Improving language understanding capabilities through generative pre-training) , proposed the GPT model (Generative Pre-Training) for the first time. Paper address: https://paperswithcode.com/method/gpt.
In February 2019, OpenAI released the paper "Language Models are Unsupervised Multitask Learners" (the language model should be an unsupervised multitask learner) and proposed the GPT-2 model. Paper address: https://paperswithcode.com/method/gpt-2
In May 2020, OpenAI released the paper "Language Models are Few-Shot Learners" (Language Models should be a small number of samples (few- shot) learners and proposed the GPT-3 model. Paper address: https://paperswithcode.com/method/gpt-3
At the end of February 2022, OpenAI released the paper "Training language models to follow instructions with human feedback" (using human feedback instruction flow to train language models), announced the Instruction GPT model. Paper address: https://arxiv.org/abs/2203.02155
On November 30, 2022, OpenAI launched ChatGPT The model is available for trial and is very popular on the entire network. See: AI-001 - What can ChatGPT, a popular chatbot on the entire network, do?
3. GPT's T-Transformer (2017)
in Chapter In section 1, we said that there is no suitable translation for Transformer.
But Transformer is the most important and basic keyword in GPT (Generative Pre-Training Transformer).
(Note: GPT's Transformer is simplified compared to the original Transformer in Google's paper, only the Decoder part is retained, see section 4.3 of this article)
3.1. Is the focus more on good or on people?
Just like a good person, the most important thing is to be good or to be a human being?
Readers, is that right?
A slightly safer answer is: neither a good person nor a human being; both Okay, they are also human beings.
Well, it’s a bit convoluted, so let’s talk in human terms and expand: In terms of semantics, the focus is on being good; in terms of basics and premises, the focus is on people.
3.2. Sorry, You are a good person
Extend it further, what about "I'm sorry, you are a good person"?
The focus of semantics becomes I'm sorry. But the premise of semantics is still human beings.
3.3. Back to the topic, what is Transfomer
You can take a look at this article "Understanding Transfomer in Ten Minutes" (https://zhuanlan.zhihu.com/p/82312421).
Look If you understand, you can ignore my next content about Transfomer and jump directly to Chapter 4. If you don’t quite understand it, you can check out my understanding, which may be of some reference to you.
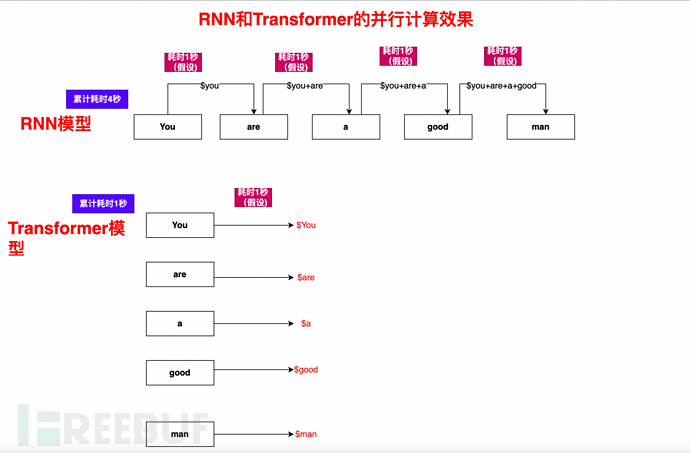
3.3.1. Major flaws of the previous generation RNN model
Before the Transformer model came out, the RNN model (recurrent neural network) was a typical NLP model architecture, based on There are other variant models of RNN (ignoring their names, after the Transformer came out, it is no longer important), but they all have the same problems and cannot be solved well.
The basic principle of RNN is to browse each word vector from left to right (for example, this is a dog), retaining the data of each word, and each subsequent word depends on the previous word.
The key issue of RNN: it needs to be calculated sequentially and sequentially. You can imagine that a book or an article contains a large number of words, and due to sequence dependency, it cannot be parallelized, so the efficiency is very low.
It may not be easy for everyone to understand this way. Let me give you an example (simplified understanding, which is slightly different from the actual situation):
In the RNN loop, how does the sentence You are a good man need to be calculated? Woolen cloth?
1), Calculate You and You are a good man, and get the result set $You
2), Based on $You, use Are and You are a good man , calculate $Are
3), based on $You, $Are, continue to calculate $a
4), and so on, calculate $is, $good, $ man, finally complete the complete calculation of all elements of You are a good man
As you can see, the calculation process is one by one, sequential calculation, a single assembly line, and the subsequent processes depend on the previous processes, so it is very slow
3.3.2. All in Attention of Transformer
As we mentioned earlier, in June 2017, Google released the paper "Attention is all you need", which was the first time The Transformer model was proposed and became the basis for the development of GPT. Paper address: https://arxiv.org/abs/1706.03762
You can know from its title "Attention is all you need" that Transfomer actually advocates "All in Attention".
So what is Attention?
In the paper "Attention is all you need", you can see its definition as follows:
Self-Attention (self-Attention), sometimes called internal attention, is a An attention mechanism that associates different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been successfully used in a variety of tasks such as reading comprehension, abstract summarization, discourse inclusion and learning task-independent sentence representation.

Simple understanding is The correlation between words is described by the vector of attention.
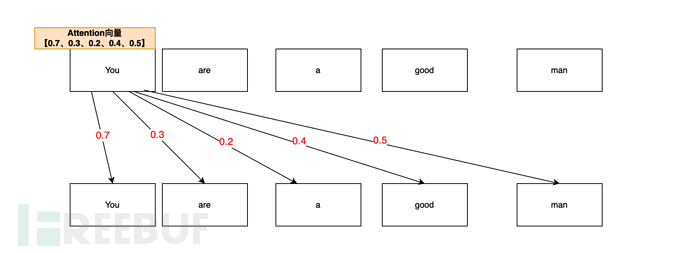
For example, You are a good man(You are a good man). When AI analyzes You's attention vector, it may analyze it like this:
From Your are a good man In the sentence, measured through the attention mechanism, the attention correlation probability between You and You (self) is the highest (0.7, 70%). After all, you (you) is you (you) first; so the attention of You, You The vector is 0.7
The attention vector of You and man (person) is related to (0.5, 50%), you (you) is a person (man), so the attention vector of You and man is 0.5
The attention correlation between You and good (good) is again (0.4, 40%). On the basis of human beings, you are still a good (good) person. So the attention vector value of You,good is 0.4
The vector value of You,are is 0.3; the vector value of You,a is 0.2.
So the final You’s attention vector list is [0.7, 0.3, 0.2, 0.4, 0.5] (only examples in this article).




In this way, many ready-made articles, web pages, Zhihu Q&A, Baidu Zhizhi, etc. are natural annotated data sets (one word, super save money).
3.5.2. Transform sequential calculations into parallel calculations, greatly reducing training time
In addition to manual annotation, RNN is mentioned in section 3.3.1 The major flaw is the problem of sequential calculation and single pipeline.
The Self-Attention mechanism, combined with the mask mechanism and algorithm optimization, allows an article, sentence, or paragraph to be calculated in parallel.
Let’s take You are a good man as an example. You can see that as many computers as there are, how fast the Transformer can be:


4. GPT (Generative Pre-Training)-June 2018
Next, comes the previous life of ChatGPT-GPT(1).
In June 2018, OpenAI released the paper "Improving Language Understanding by Generative Pre-Training" (Improving language understanding through generative pre-training), which proposed the GPT model (Generative Pre-Training) for the first time. Paper address: https://paperswithcode.com/method/gpt.
4.1. The core proposition of the GPT model 1-pre-training
The GPT model relies on the premise that Transformer eliminates sequential correlation and dependency, and puts forward a constructive proposition.
First go through a large amount of unsupervised pre-training,
Note: Unsupervised means that no human intervention is required, and no labeled data set is required (no teaching materials and teachers are required) of pre-training.
Then use a small amount of supervised fine-tuning to correct its understanding ability.

4.1.1. For example
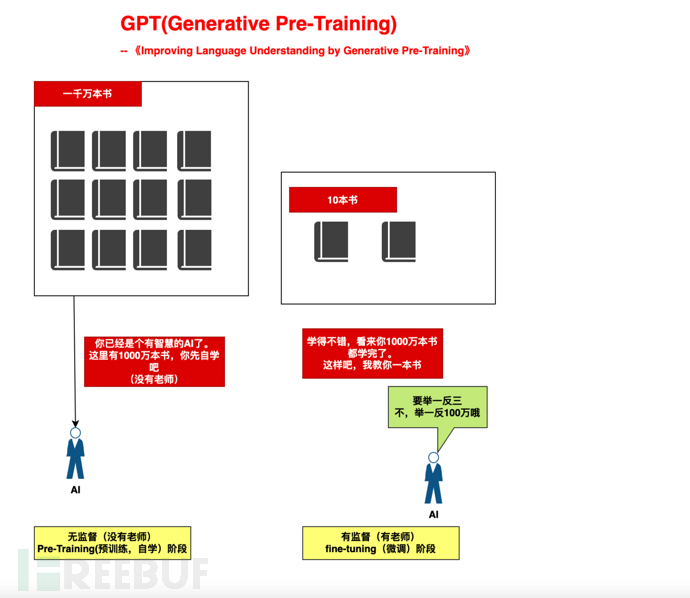
For example, it’s like we raise a child in two stages. :
1), Large-scale self-study stage (self-study of 10 million books, no teacher): Provide sufficient computing power to the AI and let it learn by itself based on the Attention mechanism.
2), small-scale guidance stage (teaching 10 books): based on 10 books, draw inferences from one example

4.1.2. Description at the beginning of the paper
The so-called clear introduction, from the opening introduction, you can also see the description of the GPT model for supervised learning and manual labeling of data.

4.2. Core proposition 2 of the GPT model - Generative
In machine learning, there are discriminative model and generative model There are two differences between Generative model.
GPT (Generative Pre-Training), as the name suggests, uses a generative model.
Generative models are more suitable for big data learning than discriminative models, and the latter are more suitable for accurate samples (manually labeled effective data sets). To better implement pre-training, the generative model would be more appropriate.
Note: The focus of this section is on the above sentence (more suitable for big data learning). If you find it complicated to understand, don’t read the rest of this section.
In the wiki generative model material (https://en.wikisensitivity.org/wiki/Generative_model), the following example is given to illustrate the difference between the two:

It may not be easy to understand just by looking at the above, so here is a supplementary explanation.
The above means, assuming there are 4 samples:
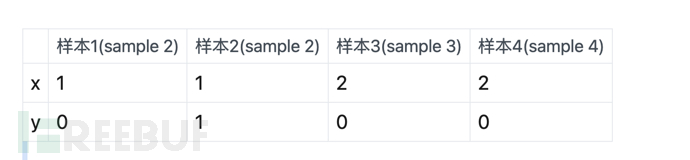
Then the characteristic of the Generative Model is that the probability is not grouped (calculate the probability within the sample and divide it by the sum of the samples). Taking the above table as an example, we find that there is a total of 1 x=1 and y=0, so we think The probability of x=1, y=0 is 1/4 (the total number of samples is 4).
Similarly, there are a total of 2 x=2, y=0, then the probability of x=2, y=0 is 2/4.

The characteristic of the discriminative model is **Probability grouping calculation (calculate the probability within the group and divide by the sum within the group)**. Taking the above table as an example, there is a total of 1 sample for x=1 and y=0, and a total of 2 samples for the group of x=1, so the probability is 1/2.
Similarly, there are a total of 2 x=2, y=0. And at the same time, there are 2 samples in the group with x=2, then the probability of x=2, y=0 is 2/2=1 (that is, 100%).

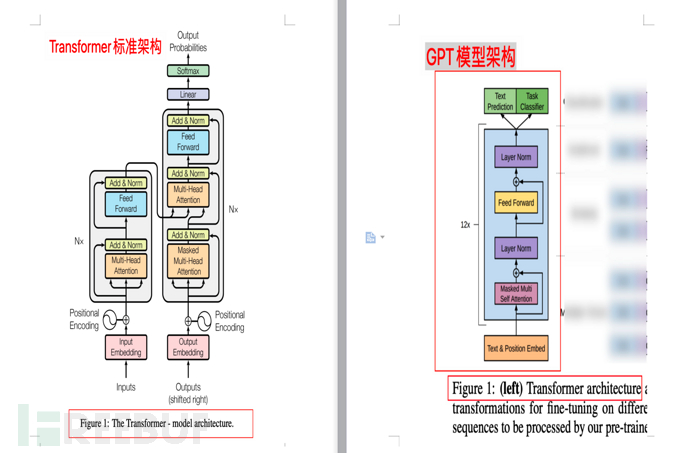
4.3. GPT’s model improvement compared to the original Transfomer
The following is the model description of GPT. GPT trained a 12-layer decoder only decoder ( decoder-only, no encoder), thus making the model simpler.
Note 1: The original Transformer of Google's paper "Attention is all you need" contains two parts: Encoder and Decoder. The former (Encoder) corresponds to translation, and the latter (Decoder) corresponds to generation.
Note 2: Google has built a BERT (Bidirectional Encoder Representations from Transformers, Bidirectional Encoder Representations from Transformers) model with Encoder as the core. The Bidirectional inside means that BERT uses both the upper and lower context to predict words, so BERT is better at handling natural language understanding tasks (NLU).
Note 3: The main point of this section is that GPT is based on Transformer, but compared with Transformer, it simplifies the model, removes Encoder, and only retains Decoder. At the same time, compared to BERT's context prediction (two-way), GPT advocates using only the context of the word to predict the word (one-way), making the model simpler, faster to calculate, more suitable for extreme generation, and therefore GPT is better at processing The natural language generation task (NLG) is what we discovered in AI-001 - what ChatGPT, the popular chatbot on the Internet, can do. ChatGPT is very good at writing "compositions" and making up lies. After understanding this paragraph, you don’t need to read the rest of this section.
Note 4: From the perspective of simulating humans, the mechanism of GPT is more like real humans. Because human beings also infer the following (that is, the following) based on the above (what is said before). The so-called words spoken are like water poured out. Human beings cannot adjust the previous words based on what is said later. Even if they say Wrong, bad words hurt people's hearts, and they can only be remedied and explained based on the words spoken (above).

4.3.1. Comparison of architecture diagrams
The following figure shows the comparison between the Transfomer model architecture and the GPT model architecture (from the paper respectively) "Attention is all you need" and "Improving Language Understanding by Generative Pre-Training")
4.4, GPT model training scale
mentioned earlier Generative mode is more conducive to Pre-Training of large data sets. So how large a data set does GPT use?
As mentioned in the paper, it uses a data set called BooksCorpus, which contains more than 7,000 unpublished books.

5, GPT-2 (February 2019)
In February 2019, OpenAI released the paper "Language Models are Unsupervised Multitask Learners" (Language Models are Unsupervised Multitask Learners) The model should be an unsupervised multi-task learner), and the GPT-2 model is proposed. Paper address: https://paperswithcode.com/method/gpt-2
5.1. Core changes of the GPT-2 model compared to GPT-1
As mentioned earlier, the core proposition of GPT There are Generative and Pre-Training. At the same time, GPT training has two steps:
1), large-scale self-study stage (Pre-Training, self-study of 10 million books, no teacher): provide sufficient computing power to the AI, and let it be based on Attention Mechanism, self-study.
2), small-scale guidance stage (fine-tuning, teaching 10 books): Based on 10 books, draw inferences about "three"
When GPT-2, OpenAI will The supervised fine-tuning stage was directly removed, turning it into an unsupervised model.
At the same time, a keyword **multitask (multitask)** has been added, which can be seen from the name of the paper "Language Models are Unsupervised Multitask Learners" (the language model should be an unsupervised multitask learner) It can also be seen.

5.2. Why such adjustment? Trying to solve the zero-shot problem
Why is GPT-2 adjusted like this? Judging from the description of the paper, it is to try to solve the zero-shot (zero-shot learning problem)**.
What is the problem with zero-shot (zero-shot learning)? It can be simply understood as reasoning ability. This means that when faced with unknown things, AI can automatically recognize it, that is, it has the ability to reason.
For example, before going to the zoo, we tell the children that a horse-like animal that is black and white like a panda and has black and white stripes is a zebra. Based on this tip, the children can correctly find the zebra.
5.3. How to understand multitask?
In traditional ML, if you want to train a model, you need a special annotated data set to train a special AI.
For example, to train a robot that can recognize dog images, you need 1 million images labeled with dogs. After training, the AI will be able to recognize dogs. This AI is a dedicated AI, also called single task.
As for multitask, it is advocated not to train dedicated AI, but to feed massive amounts of data so that any task can be completed.
5.4. Data and training scale of GPT-2
The data set is increased to 8 million web pages and 40GB in size.

The model itself also reaches a maximum of 1.5 billion parameters, and the Transformer stack reaches 48 layers. A simple analogy is like simulating 1.5 billion human neurons (just an example, not completely equivalent).

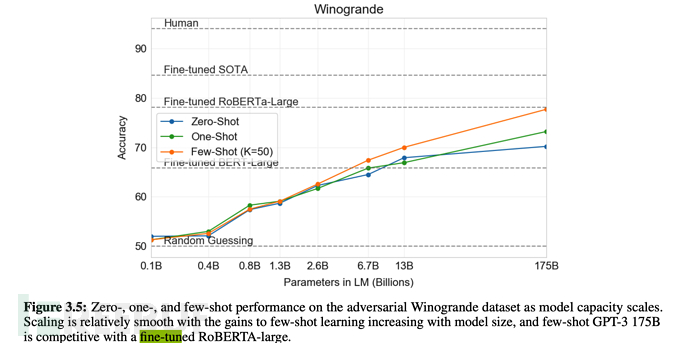
6. GPT-3 (May 2020)
In May 2020, OpenAI released the paper "Language Models are Few-Shot Learners" ( The language model should be a few-shot learner), and the GPT-3 model is proposed. Paper address: https://paperswithcode.com/method/gpt-3
6.1. GPT-3’s breakthrough effect progress
The effect is described in the paper as follows:
1. GPT-3 shows strong performance in translation, question answering and cloze filling, while being able to decipher words, use new words in sentences or perform 3-digit calculations.
2. GPT-3 can generate samples of news articles that humans can no longer distinguish.
As shown below:


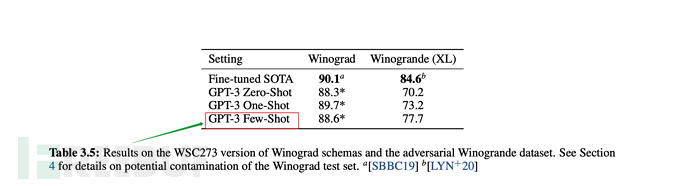
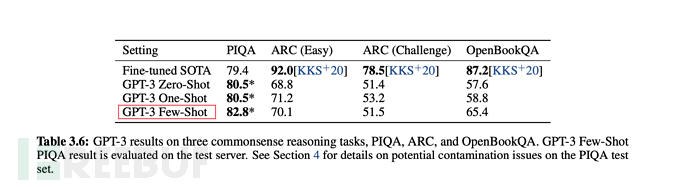
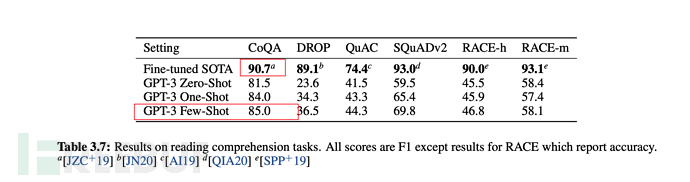
 ##6.3. Training scale of GPT-3
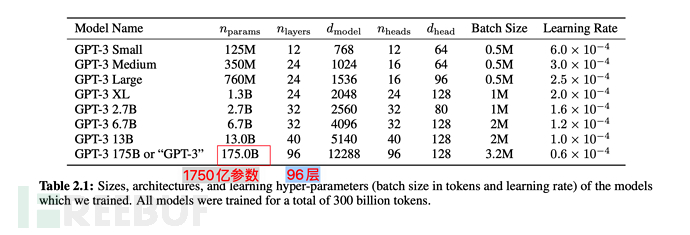
##6.3. Training scale of GPT-3
GPT-3 uses 45TB of compressed text before filtering, and there is still 570GB of massive data after filtering.
 In terms of model parameters, it has increased from 1.5 billion in GPT-2 to 175 billion, an increase of more than 110 times; the Transformer Layer has also increased from 48 to 96.
In terms of model parameters, it has increased from 1.5 billion in GPT-2 to 175 billion, an increase of more than 110 times; the Transformer Layer has also increased from 48 to 96.
7. Instruction GPT (February 2022)
At the end of February 2022, OpenAI released the paper "Training language models to follow instructions with human feedback" (using human feedback) Feedback the instruction flow to train the language model), and publish the Instruction GPT model. Paper address: https://arxiv.org/abs/2203.02155
7.1. Core changes of Instruction GPT compared to GPT-3
Instruction GPT is a round of enhanced optimization based on GPT-3 , so it is also called GPT-3.5.
As mentioned earlier, GPT-3 advocates few-shot few-shot learning while insisting on unsupervised learning.
But in fact, the effect of few-shot is obviously worse than the method of fine-tuning supervision.
So what should we do? Go back to fine-tuning to supervise fine-tuning? Obviously not.
OpenAI gives a new answer: Based on GPT-3, train a reward model (reward model) based on manual feedback (RHLF), and then use the reward model (reward model, RM) to train and learn Model.
Oh my God, I’m going to die young. . It’s time to use machines (AI) to train machines (AI). .

7.2. Core training steps of Instruction GPT
Instruction GPT has 3 steps in total:
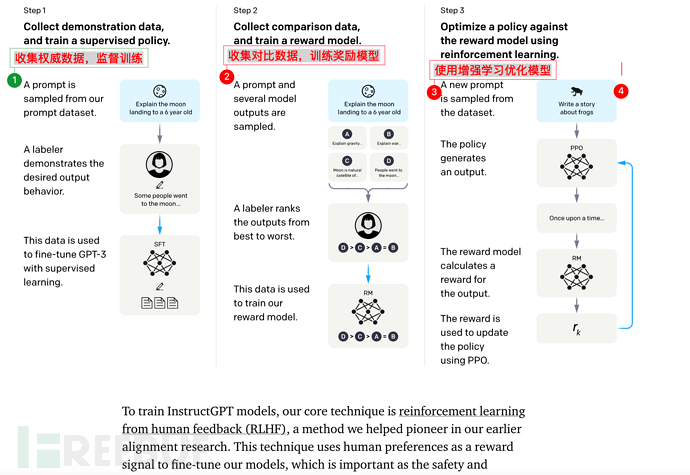
1), perform **fine-tuning (supervised fine-tuning)** on GPT-3.
2), then train a Reward Model (RM)
3), and finally optimize SFT through reinforcement learning


It is worth noting that steps 2 and 3 can be iterated and looped multiple times.
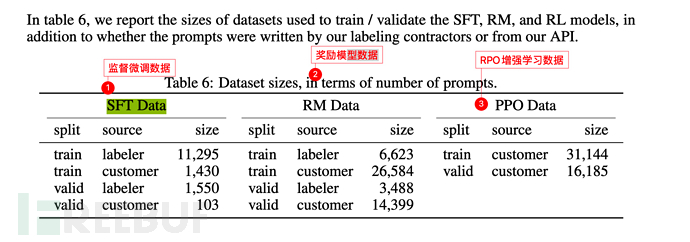
7.3. Training scale of Instruction GPT
The basic data scale is the same as GPT-3 (see section 6.3), except that 3 steps are added (supervised fine-tuning SFT, reward model training Reward Model, enhanced learning to optimize RPO).
The labeler in the picture below refers to the **labeller** employed by or related to OpenAI.
And customer refers to the user who calls the GPT-3 API (i.e. other machine learning researchers, programmers, etc.).
It is said that after the launch of ChatGPT, there are more than one million users, and each of us is its customer. Therefore, it is foreseeable that when GPT-4 is released in the future, its customer scale will be at least one million.
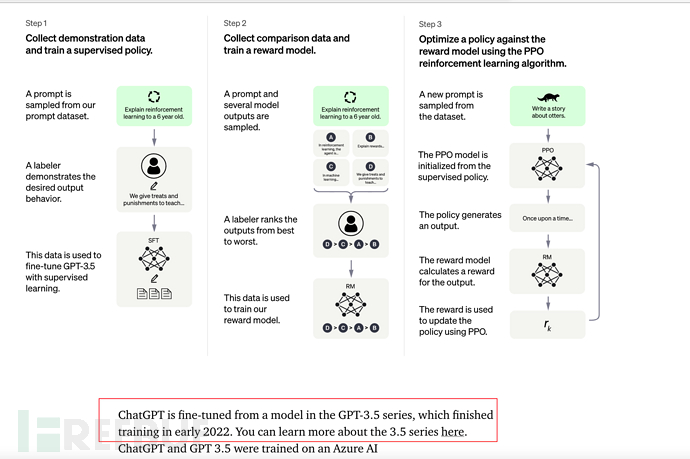
8. ChatGPT (November 2022)
On November 30, 2022, OpenAI launched the ChatGPT model and provided a trial, which became popular on the entire network.
See: AI-001-What the popular chatbot ChatGPT can do
8.1, ChatGPT and Instruction GPT
ChatGPT and InstructionGPT are essentially of the same generation , just based on InstructionGPT, the Chat function is added, and it is also open to public test training in order to generate more effective annotation data.
8.2. [Important, it is recommended to browse the recommended video below] From the perspective of human intuitive understanding, a supplementary explanation of the core principles of ChatGPT
can refer to National Taiwan University Professor Li Hongyi’s video "How is ChatGPT made?" GPT Socialization Process" is very well explained.
https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
GPT is a one-way generation, that is, the following is generated based on the above.
For example, there is a sentence:
Give input to the GPT model Hello, the next word is to pick you up, okay? You're handsome? you are so tall? How beautiful are you? Wait, GPT will calculate a probability and give the highest probability as the answer.
By analogy, if a command (or prompt) is given, ChatGPT will also calculate the following (answer) based on the above (prompt), and at the same time select the highest probability of the above to answer.
As shown below:
9. Summary
Summary:
1) In 2017, Google published the paper "Attention is all you need" and proposed the Transformer model, which paved the way for GPT.
2), In June 2018, OpenAI released the GPT generative pre-training model, which was trained through the BooksCorpus large data set (7000 books), and advocated large-scale, unsupervised pre-training (pre- training) supervised fine-tuning (fine-tuning) for model construction.
3) In February 2019, OpenAI released the GPT-2 model, further expanding the training scale (using a 40GB data set with a maximum of 1.5 billion parameters). At the same time, in terms of ideas, the fine-tuning process is removed, and zero-shot (zero-shot learning) and multitask (multi-task) are emphasized. But in the end, the zero-shot effect is significantly inferior to fine-tuning.
4), In May 2020, OpenAI released the GPT-3 model, further expanding the **training scale (using a 570GB data set and 175 billion parameters)**. At the same time, it adopts a few-shot (small number of samples) learning model and achieves excellent results. Of course, fine-tuning was simultaneously compared in the experiment, and the effect was slightly worse than fine-tuning.
5), In February 2022, OpenAI released the Instruction GPT model. This time, it mainly added a supervised fine-tuning (Supervised Fine-tuning) link based on GPT-3, and based on this, further additions The Reward Model reward model is installed, and the RM training model is used to perform RPO enhanced learning optimization on the learning model.
6), On November 30, 2022, OpenAI released the ChatGPT model, which can be understood as an InstructionGPT after multiple rounds of iterative training, and based on this, a Chat dialogue function was added.
10. The future (GPT-4 or ?)
Judging from various signs, GPT-4 may be unveiled in 2023? How powerful will it be?
At the same time, the effect of ChatGPT has attracted a lot of attention in the industry. It is believed that more training models and their applications based on GPT will flourish in the future.
The future will come soon, let’s wait and see.
Some references
ai.googleblog.com/2017/08/transformer-novel-neural-network.html
https://arxiv.org/abs/ 1706.03762
https://paperswithcode.com/method/gpt
https://paperswithcode.com/method/gpt-2
https://paperswithcode.com /method/gpt-3
https://arxiv.org/abs/2203.02155
https://zhuanlan.zhihu.com/p/464520503
https: //zhuanlan.zhihu.com/p/82312421
https://cloud.tencent.com/developer/article/1656975
https://cloud.tencent.com/developer/ article/1848106
https://zhuanlan.zhihu.com/p/353423931
https://zhuanlan.zhihu.com/p/353350370
https:/ /juejin.cn/post/6969394206414471175
https://zhuanlan.zhihu.com/p/266202548
https://en.wikisensitivity.org/wiki/Generative_model
https://zhuanlan.zhihu.com/p/67119176
https://zhuanlan.zhihu.com/p/365554706
https://cloud.tencent .com/developer/article/1877406
https://zhuanlan.zhihu.com/p/34656727
https://zhuanlan.zhihu.com/p/590311003
The above is the detailed content of Ten minutes to understand the technical logic and evolution of ChatGPT (past life, present life). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
ChatGPT now allows free users to generate images by using DALL-E 3 with a daily limit
Aug 09, 2024 pm 09:37 PM
DALL-E 3 was officially introduced in September of 2023 as a vastly improved model than its predecessor. It is considered one of the best AI image generators to date, capable of creating images with intricate detail. However, at launch, it was exclus
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
How to install chatgpt on mobile phone
Mar 05, 2024 pm 02:31 PM
Installation steps: 1. Download the ChatGTP software from the ChatGTP official website or mobile store; 2. After opening it, in the settings interface, select the language as Chinese; 3. In the game interface, select human-machine game and set the Chinese spectrum; 4 . After starting, enter commands in the chat window to interact with the software.
 DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
DualBEV: significantly surpassing BEVFormer and BEVDet4D, open the book!
Mar 21, 2024 pm 05:21 PM
This paper explores the problem of accurately detecting objects from different viewing angles (such as perspective and bird's-eye view) in autonomous driving, especially how to effectively transform features from perspective (PV) to bird's-eye view (BEV) space. Transformation is implemented via the Visual Transformation (VT) module. Existing methods are broadly divided into two strategies: 2D to 3D and 3D to 2D conversion. 2D-to-3D methods improve dense 2D features by predicting depth probabilities, but the inherent uncertainty of depth predictions, especially in distant regions, may introduce inaccuracies. While 3D to 2D methods usually use 3D queries to sample 2D features and learn the attention weights of the correspondence between 3D and 2D features through a Transformer, which increases the computational and deployment time.
 Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
Can chatgpt be used in China?
Mar 05, 2024 pm 03:05 PM
chatgpt can be used in China, but cannot be registered, nor in Hong Kong and Macao. If users want to register, they can use a foreign mobile phone number to register. Note that during the registration process, the network environment must be switched to a foreign IP.
 Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
Review! Deep model fusion (LLM/basic model/federated learning/fine-tuning, etc.)
Apr 18, 2024 pm 09:43 PM
In September 23, the paper "DeepModelFusion:ASurvey" was published by the National University of Defense Technology, JD.com and Beijing Institute of Technology. Deep model fusion/merging is an emerging technology that combines the parameters or predictions of multiple deep learning models into a single model. It combines the capabilities of different models to compensate for the biases and errors of individual models for better performance. Deep model fusion on large-scale deep learning models (such as LLM and basic models) faces some challenges, including high computational cost, high-dimensional parameter space, interference between different heterogeneous models, etc. This article divides existing deep model fusion methods into four categories: (1) "Pattern connection", which connects solutions in the weight space through a loss-reducing path to obtain a better initial model fusion
 More than just 3D Gaussian! Latest overview of state-of-the-art 3D reconstruction techniques
Jun 02, 2024 pm 06:57 PM
More than just 3D Gaussian! Latest overview of state-of-the-art 3D reconstruction techniques
Jun 02, 2024 pm 06:57 PM
Written above & The author’s personal understanding is that image-based 3D reconstruction is a challenging task that involves inferring the 3D shape of an object or scene from a set of input images. Learning-based methods have attracted attention for their ability to directly estimate 3D shapes. This review paper focuses on state-of-the-art 3D reconstruction techniques, including generating novel, unseen views. An overview of recent developments in Gaussian splash methods is provided, including input types, model structures, output representations, and training strategies. Unresolved challenges and future directions are also discussed. Given the rapid progress in this field and the numerous opportunities to enhance 3D reconstruction methods, a thorough examination of the algorithm seems crucial. Therefore, this study provides a comprehensive overview of recent advances in Gaussian scattering. (Swipe your thumb up
