
 Technology peripherals
AI
GPT-4 reasoning improved by 1750%! Princeton Tsinghua Yao class alumnus proposed a new 'Thinking Tree ToT' framework, allowing LLM to think repeatedly
Technology peripherals
AI
GPT-4 reasoning improved by 1750%! Princeton Tsinghua Yao class alumnus proposed a new 'Thinking Tree ToT' framework, allowing LLM to think repeatedly
GPT-4 reasoning improved by 1750%! Princeton Tsinghua Yao class alumnus proposed a new 'Thinking Tree ToT' framework, allowing LLM to think repeatedly

In 2022, Jason Wei, a former Chinese scientist at Google Brain, first proposed in a pioneering work on the thinking chain that CoT can enhance the reasoning ability of LLM.
But even with the thinking chain, LLM sometimes makes mistakes on very simple questions.
Recently, researchers from Princeton University and Google DeepMind proposed a new language model reasoning framework - "Tree of Thinking" (ToT).
ToT generalizes the currently popular "thinking chain" method to guide the language model and solve the intermediate steps of the problem by exploring coherent units of text (thinking).

##Paper address: https://arxiv.org/abs/2305.10601
Project address: https://github.com/kyegomez/tree-of-thoughts
Simply put, " "Thinking Tree" allows LLM to:
· Give yourself multiple different reasoning paths
· After evaluating each, decide the next step Plan of action
· Trace forward or backward when necessary in order to achieve global decision-making
The experimental results of the paper show that ToT Significantly improved LLM's problem-solving abilities in three new tasks (24-point game, creative writing, mini crossword puzzle).
For example, in the 24-point game, GPT-4 only solved 4% of the tasks, but the success rate of the ToT method reached 74%.
Let LLM "think over and over"The large language models GPT and PaLM used to generate text have now proven to be able to perform a wide range of tasks.
The basis for the progress of all these models is still the "autoregressive mechanism" originally used to generate text, making token-level decisions one after another in a left-to-right manner.

So, can such a simple mechanism be enough to establish a "language model for solving general problems"? If not, what issues challenge the current paradigm, and what should the real alternative mechanisms be?
It is precisely the literature on "human cognition" that provides some clues to this issue.
Research on the "dual process" model shows that humans have two modes of decision-making: fast, automatic, unconscious mode - "System 1" and slow, deliberate, conscious mode - " System 2".
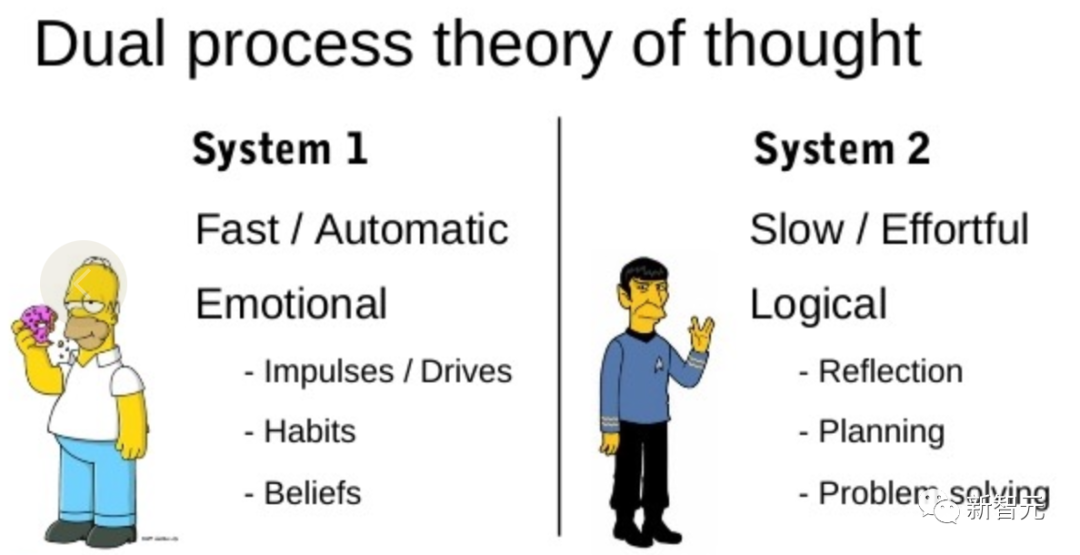
The language model's simple association of token-level choices can be reminiscent of "System 1", so this ability may Enhanced from the "System 2" planning process.
"System 1" allows LLM to maintain and explore multiple alternatives to the current choice rather than just choosing one, while "System 2" evaluates its current status and actively Look ahead and look back to make more holistic decisions.
In order to design such a planning process, researchers traced back to the origins of artificial intelligence and cognitive science, starting with the planning process explored by scientists Newell, Shaw and Simon in the 1950s. draw inspiration from.
Newell and colleagues describe problem solving as "searching by combining the problem space," represented as a tree.
In the process of solving problems, you need to repeatedly use existing information to explore to obtain more information until you finally find a solution.

##This perspective highlights 2 main shortcomings of existing methods of using LLM to solve general problems:
1. Locally, LLM does not explore the different continuations of the thinking process - the branches of the tree.
2. Overall, LLM does not include any type of planning, looking forward, or looking back to help evaluate these different options.
In order to solve these problems, researchers proposed a thinking tree framework (ToT) that uses language models to solve general problems, allowing LLM to explore multiple thinking reasoning paths.
ToT four-step methodCurrently, existing methods, such as IO, CoT, and CoT-SC, solve problems by sampling continuous language sequences.
And ToT actively maintains a "thinking tree". Each rectangular box represents a thought, and each thought is a coherent verbal sequence that serves as an intermediate step in solving a problem.
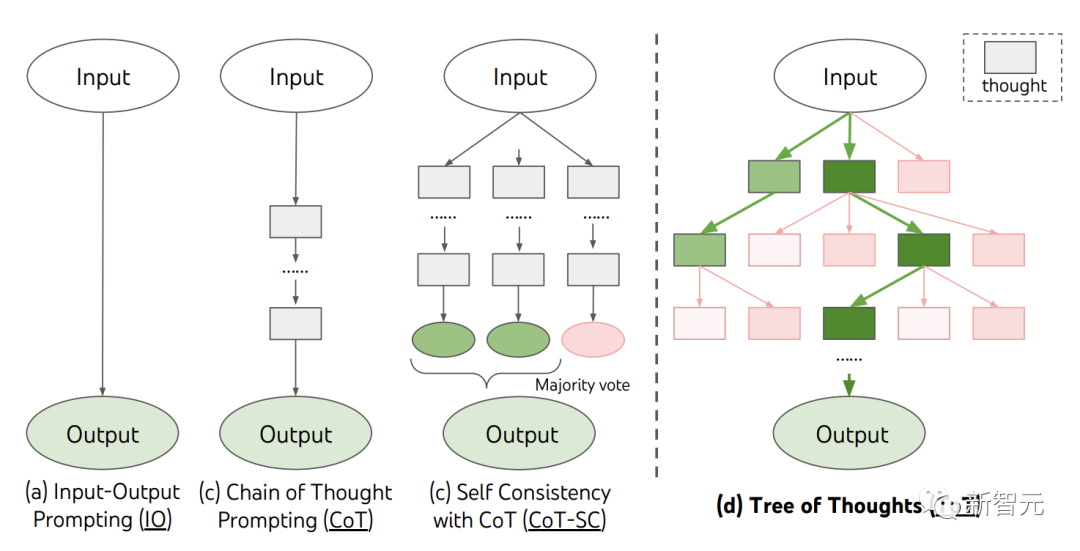
ToT defines any problem as a search on a tree, where each node is a state that represents the Partial solution of input and thought sequences so far.
ToT needs to answer 4 questions when performing a specific task:
How to decompose the intermediate process into thinking steps; how to start from each state Generate potential ideas; how to evaluate states heuristically; what search algorithms to use.
1. Thinking breakdown
CoT is not clear Decomposition involves coherent sampling of thinking, while ToT uses the properties of the problem to design and decompose intermediate thinking steps.
Depending on the problem, an idea can be a few words (crossword puzzle), an equation (24 points), or an entire writing plan (creative writing).
Generally speaking, an idea should be "small" enough so that LLM can produce meaningful, diverse samples. For example, generating a complete book is often too "big" to be coherent.
But an idea should also be "big" enough for LLM to evaluate its prospects for solving the problem. For example, generating a token is often too "small" to evaluate.
2. Thought generator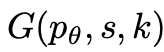
Given tree state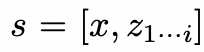 , using 2 strategies to generate k candidates for the next thinking step.
, using 2 strategies to generate k candidates for the next thinking step.
(a) Sampling from a CoT prompt 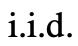 Thinking:
Thinking:
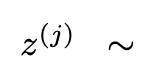
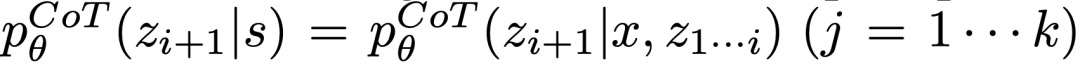
is rich in thinking space (such as each idea is a paragraph), and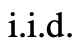 The effect is better when it leads to diversity.
The effect is better when it leads to diversity.
(b) Use the "proposal prompt" to propose ideas in order: 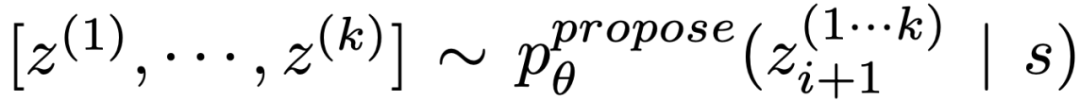
. This works better when the thinking space is limited (e.g. each thought is just one word or line), so presenting different ideas in the same context avoids duplication.
3. State Evaluator
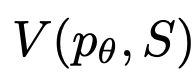
Given a frontier of different states, the state evaluator evaluates their progress in solving the problem, serving as a heuristic for the search algorithm to determine which states need to continue to be explored, and in what order.
While heuristics are the standard way to solve search problems, they are often programmed (DeepBlue) or learned (AlphaGo). Here, researchers propose a third option to consciously reason about states through LLM.
Where applicable, such thoughtful heuristics can be more flexible than procedural rules and more efficient than learning models. With the Thought Generator, the researchers also considered 2 strategies to evaluate states independently or together: assigning values to each state independently; and voting across states.
4. Search algorithm
Finally, in ToT Within the framework, one can plug and play different search algorithms based on the tree structure.
The researchers explored 2 relatively simple search algorithms here:
Algorithm 1 - Breadth First Search (BFS), each Maintain the most promising state of a set of b in one step.
Algorithm 2 - Depth First Search (DFS), first explore the most promising states until the final output is reached, or the state evaluator deems it impossible to solve from the current threshold question. In both cases, DFS backtracks to s's parent state to continue exploration.

From the above, LLM’s method of implementing heuristic search through self-evaluation and conscious decision-making is novel.
Experiment
To this end, the team proposed three tasks for testing - even the state-of-the-art language model GPT-4, under standard IO prompts or It is very challenging when prompted by the Chain of Thought (CoT).

##24 points (Game of 24)
24 points is a Math reasoning game where the goal is to get 24 using 4 numbers and basic arithmetic operations (-*/).
For example, given the input "4 9 10 13", the output of the answer may be "(10-4)*(13-9)=24".
ToT Setup
The team broke down the thought process of the model into 3 steps, each step is a intermediate equation.
As shown in Figure 2(a), at each node, extract the number on the "left" and prompt LLM to generate a possible next step. (The "proposal prompts" given at each step are the same)
Among them, the team performs breadth-first search (BFS) in ToT and retains the best b= at each step. 5 candidates.
As shown in Figure 2(b), LLM is prompted to evaluate each thinking candidate as "definitely/possibly/impossibly" up to 24. Eliminate impossible partial solutions based on common sense of "too big/too small" and retain the remaining "possible" items.
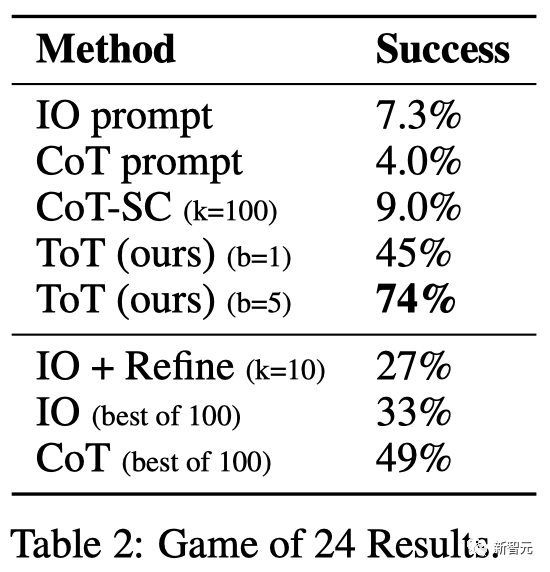
##The results
are shown in Table 2 It was shown that the IO, CoT and CoT-SC prompting methods performed poorly on the task, with success rates of only 7.3%, 4.0% and 9.0%. In comparison, ToT has achieved a success rate of 45% when the breadth is b=1, and 74% when b=5.
The team also considered the prediction setting of IO/CoT by using the best k samples (1≤k≤100) to calculate the success rate and show it in Figure 3(a) 5 success rates are plotted.
As expected, CoT scales better than IO, with the best 100 CoT samples achieving a 49% success rate, but still exploring more nodes than in ToT ( b>1) To be worse.
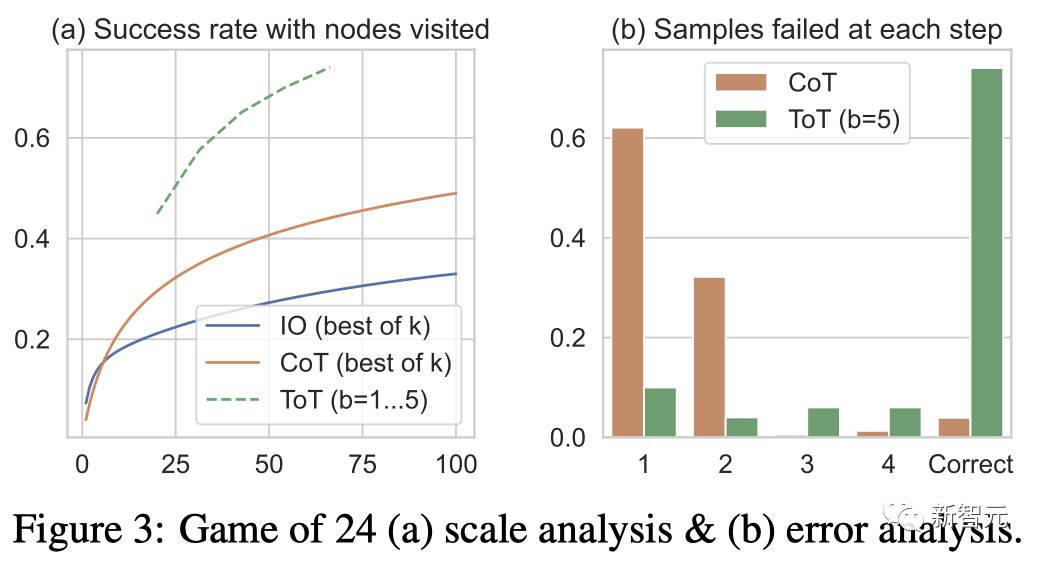
Error analysis
Figure 3( b) Analyzed at which step the CoT and ToT samples failed the task, i.e. the thinking (in CoT) or all b thinking (in ToT) were invalid or could not reach 24.
It is worth noting that about 60% of the CoT samples have failed in the first step, or in other words, the first three words (such as "4 9").
Creative Writing
Next, the team designed a creative writing task.
The input is four random sentences, and the output should be a coherent paragraph, each paragraph ending with four input sentences respectively. Such tasks are open-ended and exploratory, challenging creative thinking and advanced planning.
It is worth noting that the team also uses an iterative-optimization (k≤5) method on random IO samples of each task, in which LLM is based on input constraints and the last generated paragraph. Determine whether the paragraph is "completely coherent", and if not, generate an optimized one.
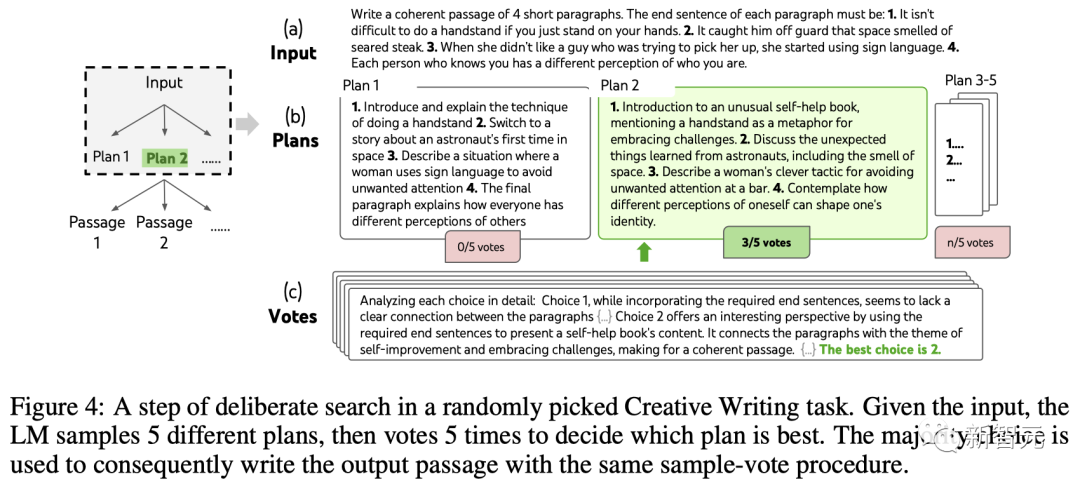
ToT Settings
Team Build A ToT with depth 2 (only 1 intermediate thought step).
LLM first generates k=5 plans and votes to choose the best one (Figure 4), then generates k=5 paragraphs based on the best plan, and then votes to choose the best one one.
A simple zero-shot voting prompt ("Analyze the following choices and decide which is most likely to implement the directive") is used to draw 5 votes in two steps.
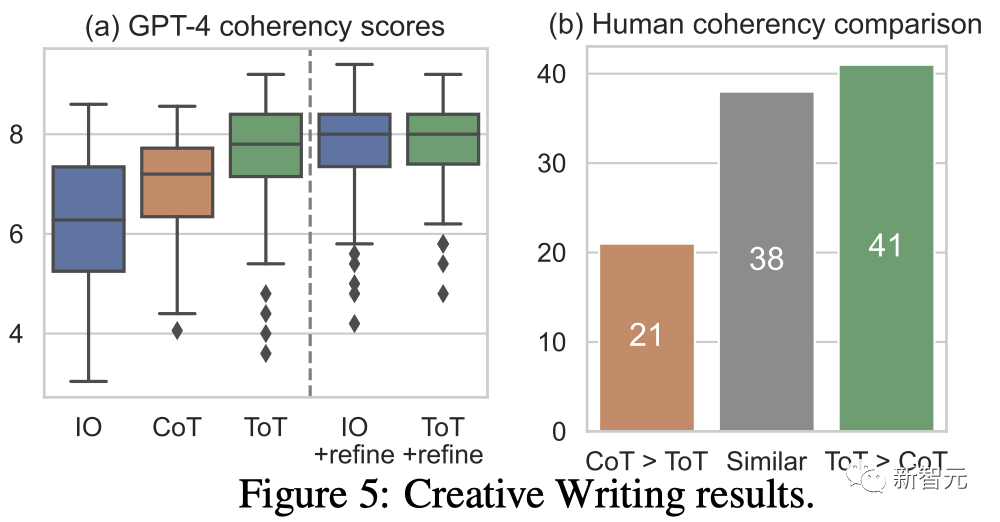
Results
Figure 5(a) shows 100 tasks GPT-4 average score in , where ToT (7.56) is considered to produce more coherent paragraphs on average than IO (6.19) and CoT (6.93).
Although such automated evaluations may be noisy, Figure 5(b) demonstrates this by showing that humans prefer ToT for 41 out of 100 paragraph pairs and only 21 for CoT. (38 other pairs were considered "equally coherent") to confirm this finding.
Finally, iterative optimization is more effective on this natural language task - improving the IO coherence score from 6.19 to 7.67 and the ToT coherence score from 7.56 to 7.91.
The team believes that it can be seen as the third method of generating thinking under the ToT framework. New thinking can be generated by optimizing old thinking, rather than i.i.d. or sequential generation. .
mini crossword puzzle
In the 24-point game and creative writing, ToT is relatively shallow-it takes up to 3 thinking steps to solve it. The output can be completed.
Finally, the team decided to set a more difficult question through a 5×5 mini crossword puzzle.
Again, the goal is not just to solve the task, but to study the limits of LLM as a general problem solver. Guide your exploration by peering into your own mind and using purposeful reasoning as inspiration.
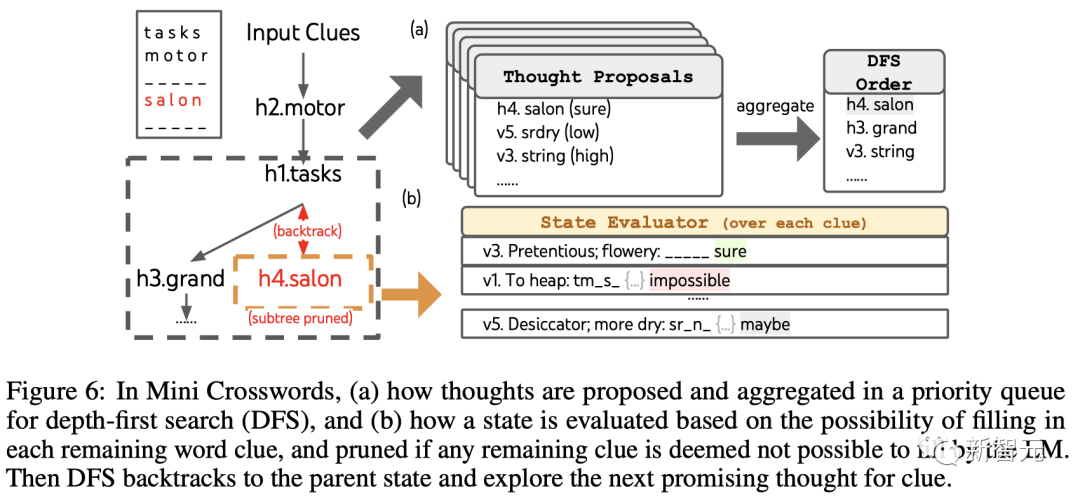
ToT Setup
Team Utilization Depth Prioritized search keeps exploring subsequent word clues that are most likely to succeed until the state is no longer promising, then backtracks to the parent state to explore alternative ideas.
To make the search feasible, subsequent thoughts are restricted from changing any filled-in words or letters, so that the ToT has a maximum of 10 intermediate steps.
For thought generation, the team generates all existing thoughts in each state (for example, "h2.motor; h1.tasks" for the state in Figure 6(a)) Convert to the letter limit of the remaining clues (for example, "v1.To heap: tm___;..."), thereby obtaining candidates for filling in the position and content of the next word.
Importantly, the team also prompts the LLM to give confidence levels for different ideas and aggregates these in the proposal to obtain a ranked list of ideas to explore next (Figure 6(a) )).
For status evaluation, the team similarly converts each status into a letter limit for the remaining leads, and then evaluates each lead for whether it is likely to be filled within the given limit.
If any remaining clues are considered "impossible" (e.g., "v1. To heap: tm_s_"), then the exploration of the subtree of that state is pruned , and DFS backtracks to its parent node to explore the next possible candidate.
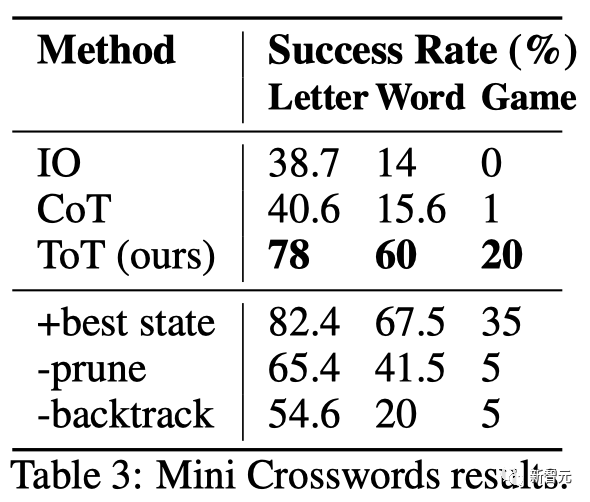
##The results
are shown in Table 3 showed that the prompting methods of IO and CoT performed poorly on word-level success rates, below 16%, while ToT significantly improved all metrics, achieving a word-level success rate of 60% and solving 4 out of 20 games. indivual.
This improvement is not surprising given that IO and CoT lack mechanisms to try different clues, change decisions, or backtrack.
Limitations and Conclusions
ToT is a framework that allows LLM to make decisions and solve problems more autonomously and intelligently.
It improves the interpretability of model decisions and the chance of alignment with humans because the representations generated by ToT are in the form of readable, high-level language reasoning rather than implicit , low-level token value.
ToT may not be necessary for those tasks that GPT-4 is already very good at.
In addition, search methods like ToT require more resources (such as GPT-4 API cost) to improve task performance, but ToT’s modular flexibility allows users to customize This performance-cost balance.
However, as LLM is used in more real-world decision-making applications (such as programming, data analysis, robotics, etc.), ToT can provide a basis for studying the more complex upcoming problems. tasks and provide new opportunities.
Introduction to the author
Shunyu Yao(姚顺雨)

The first author of the paper, Shunyu Yao, is a fourth-year doctoral student at Princeton University. He previously graduated from the Yao Class of Tsinghua University.
His research direction is to establish interactions between language agents and the world, such as playing word games (CALM), online shopping (WebShop), and browsing Wikipedia for reasoning (ReAct) , or, based on the same idea, use any tool to accomplish any task.
In life, he enjoys reading, basketball, billiards, traveling and rapping.
Dian Yu

##Dian Yu is A research scientist at Google DeepMind. Previously, he earned his PhD from UC Davis and his BA from New York University, double majoring in computer science and finance (and a little acting).
His research interests are in the property representation of language, as well as multilingual and multimodal understanding, focusing mainly on conversation research (both open domain and task-oriented).
Yuan Cao
##Yuan Cao is also a research scientist at Google DeepMind. Previously, he received his bachelor's and master's degrees from Shanghai Jiao Tong University and his PhD from Johns Hopkins University. He also served as the chief architect of Baidu.
Jeffrey Zhao

The above is the detailed content of GPT-4 reasoning improved by 1750%! Princeton Tsinghua Yao class alumnus proposed a new 'Thinking Tree ToT' framework, allowing LLM to think repeatedly. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
How to solve the problem of virtual columns in Laravel model? Use stancl/virtualcolumn!
Apr 17, 2025 pm 09:48 PM
During Laravel development, it is often necessary to add virtual columns to the model to handle complex data logic. However, adding virtual columns directly into the model can lead to complexity of database migration and maintenance. After I encountered this problem in my project, I successfully solved this problem by using the stancl/virtualcolumn library. This library not only simplifies the management of virtual columns, but also improves the maintainability and efficiency of the code.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
