

Xi Xiaoyao Science and Technology Talk Original Author | Xiaoxi, Python
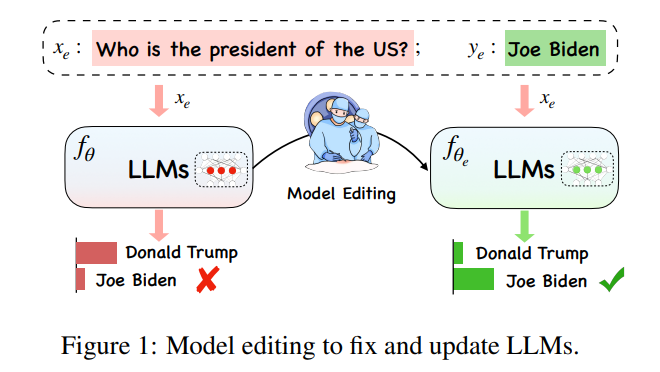
There is an intuitive question behind the huge size of the large model: "How should the large model be updated?"
in Under the extremely huge computing overhead of large models, updating large model knowledge is not a simple "learning task". Ideally, with the complex changes in various situations in the world, large models should also keep up with the times anytime and anywhere. However, the computational burden of training a new large model does not allow the large model to be updated immediately. Therefore, a new concept "Model Editing" came into being to achieve effective processing of model data in specific fields. changes without adversely affecting the results of other inputs.

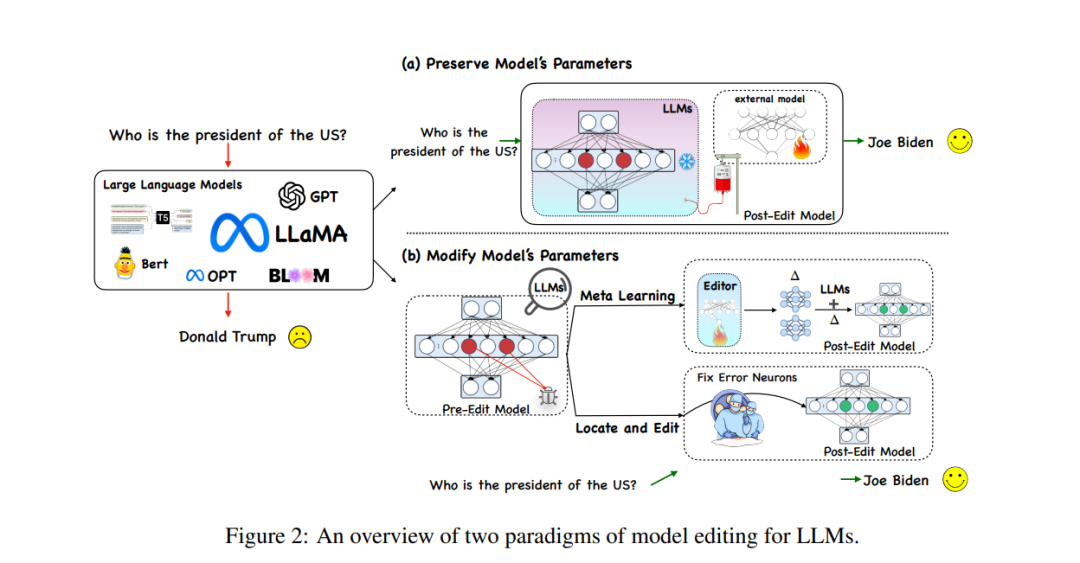
The other major category of methods, the method of modifying the parameters in the original model, mainly uses a Δ matrix to update some parameters in the model. Specifically, the method of modifying parameters can be divided into "Locate-Then-Edit" and There are two types of meta-learning methods. As can be seen from the name, the Locate-Then-Edit method first locates the main influencing parameters in the model, and then modifies the located model parameters to implement model editing. The main methods are such as the Knowledge Neuron method ( KN) determines the main influencing parameters by identifying "knowledge neurons" in the model, and updates the model by updating these neurons. Another method called ROME has a similar idea to KN, and locates the editing area through causal intermediary analysis. In addition There is also a MEMIT method that can be used to update a series of edit descriptions. The biggest problem with this type of method is that it generally relies on an assumption of locality of factual knowledge, but this assumption has not been widely verified, and editing of many parameters may lead to unexpected results.
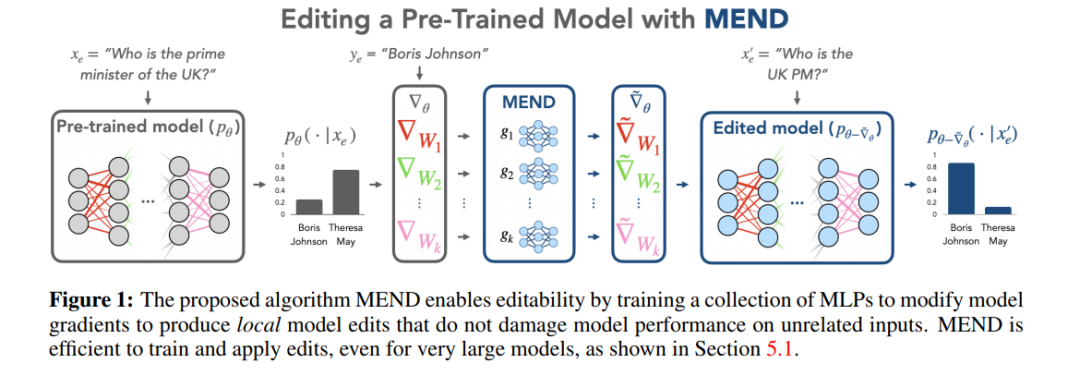
The meta-learning method is different from the Locate-Then-Edit method. The meta-learning method uses the hyper network method, using a hyper network to generate weights for another network, specifically in the Knowledge Editor method. , the author uses a bidirectional LSTM to predict the update that each data point brings to the model weight, thereby achieving constrained optimization of the editing target knowledge. This type of knowledge editing method is difficult to apply to LLMs due to the huge amount of parameters in LLMs. Therefore, Mitchell et al. proposed MEND (Model Editor Networks with Gradient Decomposition) so that a single editing description can effectively update LLMs. This update The method mainly uses low-rank decomposition of gradients to fine-tune the gradients of large models, thereby enabling minimal resource updates to LLMs. Unlike the Locate-Then-Edit method, meta-learning methods usually take longer and consume greater memory costs.
These different methods are used in the two mainstream data sets ZsRE (question and answer data set, using back translation). The questions generated using back translation are rewritten as Effective field) and COUNTERFACT (counterfactual data set, replace the subject entity with a synonymous entity as the effective field). The experiment is shown in the figure below. The experiment mainly focuses on two relatively large LLMs T5-XL (3B) and GPT-J (6B) is a basic model, and an efficient model editor should strike a balance between model performance, inference speed, and storage space.
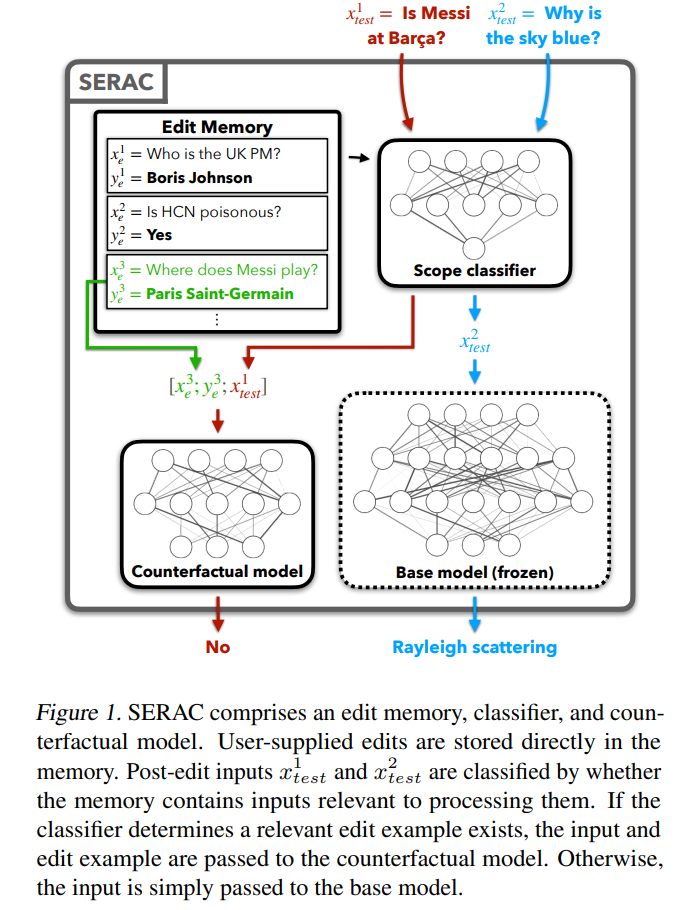
Comparing the results of fine-tuning (FT) in the first column, it can be found that SERAC and ROME performed well on the ZsRE and COUNTERFACT data sets, especially SERAC, which achieved more than 90% on multiple evaluation indicators. As a result, although MEMIT is not as versatile as SERAC and ROME, it performs well in reliability and locality. The T-Patcher method is extremely unstable. It has good reliability and locality in the COUNTERFACT data set, but lacks generality. In GPT-J, it has excellent reliability and generality, but poor performance in locality. . It is worth noting that the performance of KE, CaliNET and KN is poor. Compared with the good performance achieved by these models in "small models", the experiments may prove that these methods are not well adapted to the environment of large models.
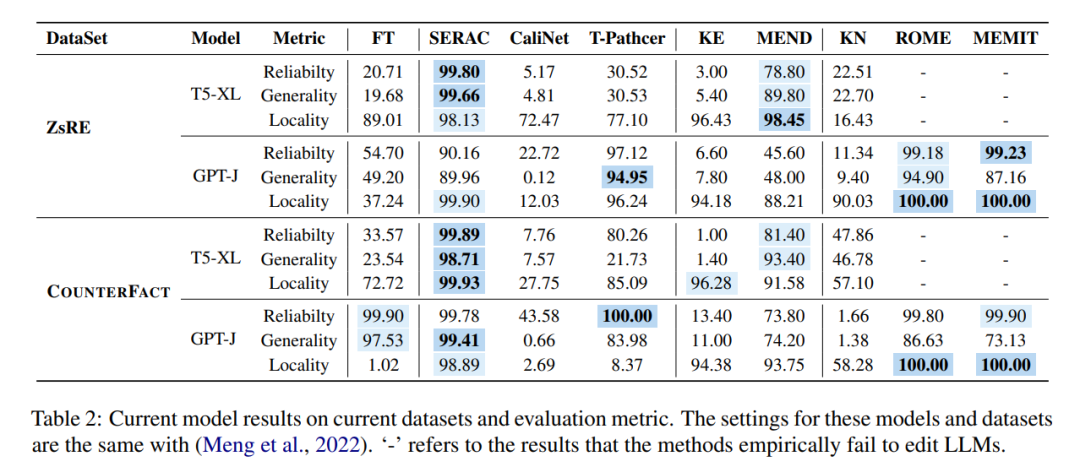
From a time perspective, once the network is trained, KE and MEND perform very well, while methods such as T-Patcher are too time-consuming:
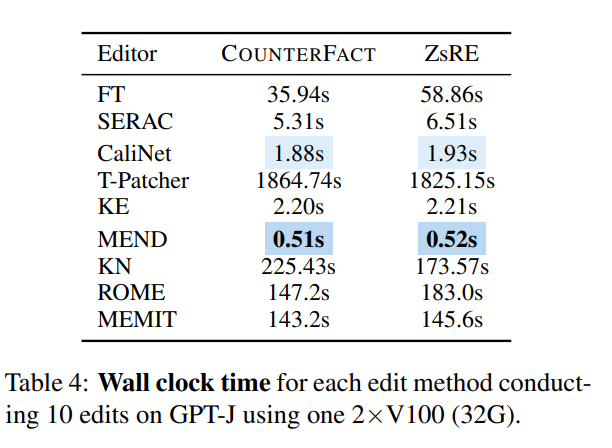
Looking at memory consumption, most methods consume memory of the same magnitude, but methods that introduce additional parameters will bear additional memory overhead:
At the same time, usually the model editing operation also needs to consider batch input editing information and sequential input editing information, that is, updating multiple fact information at one time and updating multiple fact information sequentially, batch input The overall model effect of editing information is shown in the figure below. It can be seen that MEMIT can support editing more than 10,000 pieces of information at the same time, and can also ensure that the performance of both metrics remains stable, while MEND and SERAC perform poorly:
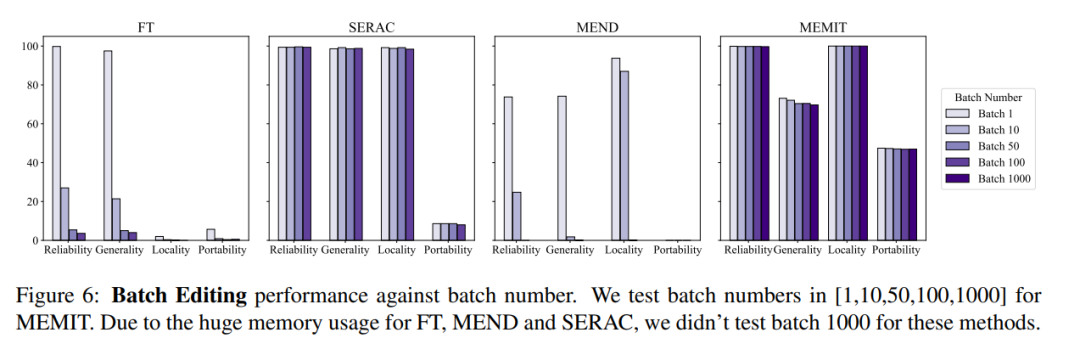
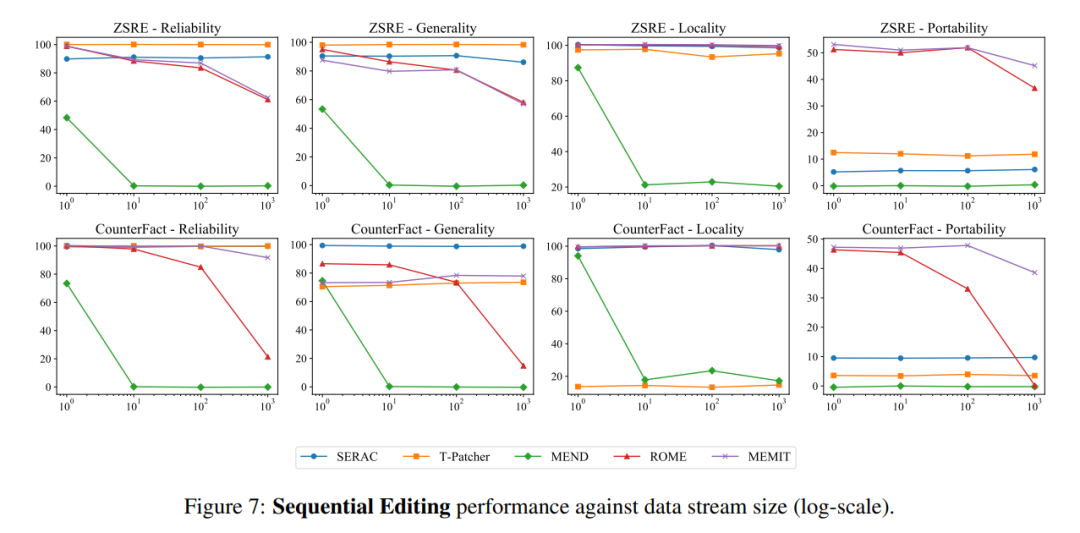
In terms of sequential input, SERAC and T-Patcher performed well and stably, while ROME, MEMIT, and MEND all experienced rapid decline in model performance after a certain amount of input:
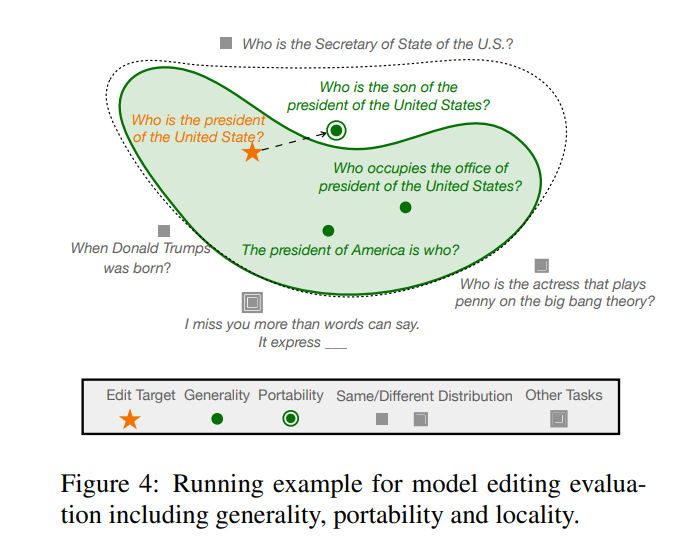
Finally, the author found in the research that the current construction and evaluation indicators of these data sets largely only focus on changes in sentence wording, but do not go deep into model editing. Changes to many relevant logical facts, such as if the answer to "What college did Watts Humphrey attend?" were changed from Trinity College to the University of Michigan. Obviously, if when we ask the model "Which city did Watts Humphrey live in college?", the ideal The model should answer Ann Arbor rather than Hartford, so the authors of the paper introduced a "transferability" metric based on the first three evaluation metrics to measure the effectiveness of the edited model in knowledge transfer.
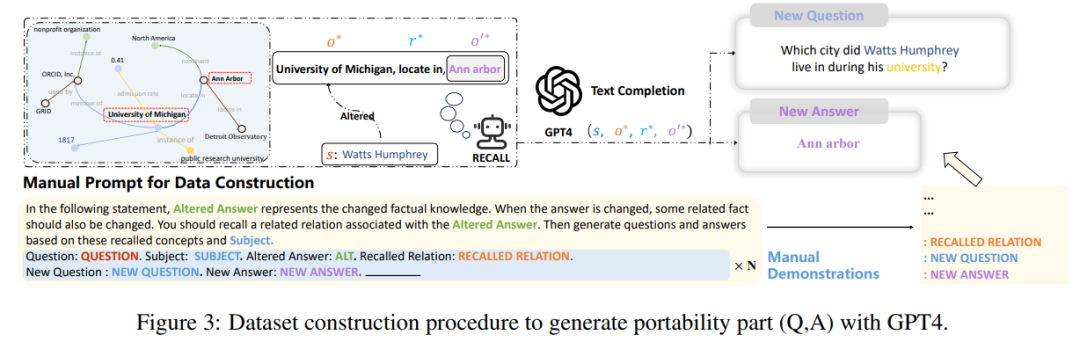
To this end, the author used GPT-4 to construct a new data set by changing the answer to the original question from to , and constructing another question with the correct answer to , forming a triplet, input the edited model, and if the model can output correctly, it proves that the edited model has "portability". According to this method, the paper tested the portability scores of several existing methods as shown below As shown:
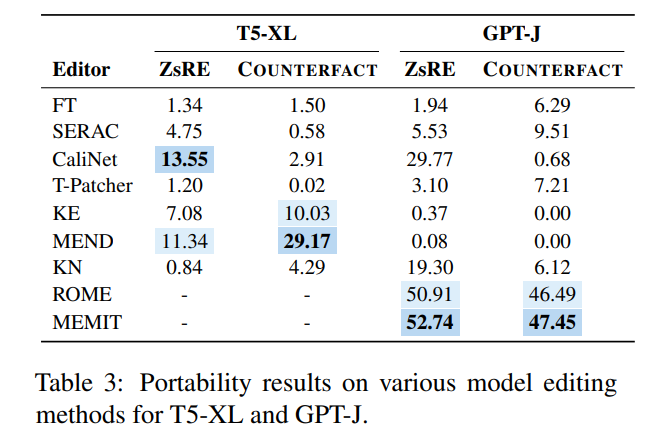
It can be seen that almost most model editing methods are not ideal in terms of portability. The portability accuracy of SERAC, which once performed well, is not very good. To 10%, the relatively best ROME and MEMIT are only about 50%, which shows that the current model editing method is almost difficult to achieve any expansion and promotion of edited knowledge, and model editing still has a long way to go.
No matter in what sense, the problem of model editing presets has great potential in the so-called "big model era" in the future, and the problem of model editing needs to be better Exploring a series of very difficult questions such as "Which parameters are the model knowledge stored in?" and "How can model editing operations not affect the output of other modules?" On the other hand, to solve the problem of model "outdated", in addition to letting the model be "edited", another idea is to let the model "lifelong learning" and "forget" sensitive knowledge, whether it is model editing or model lifelong learning, Such research will make meaningful contributions to the security and privacy issues of LLMs.
The above is the detailed content of What to do if the large model knowledge is Out? The Zhejiang University team explores methods for updating parameters of large models—model editing. For more information, please follow other related articles on the PHP Chinese website!
 python configure environment variables
python configure environment variables
 The difference between ms office and wps office
The difference between ms office and wps office
 How to change phpmyadmin to Chinese
How to change phpmyadmin to Chinese
 How to implement docker container technology in java
How to implement docker container technology in java
 How to enter BIOS on thinkpad
How to enter BIOS on thinkpad
 Introduction to input functions in c language
Introduction to input functions in c language
 HP notebook sound card driver
HP notebook sound card driver
 Usage of instr function
Usage of instr function








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



