

Example analysis of Redis buffer mechanism

Redis buffer mechanism
The buffer mechanism in Redis is to balance the difference in speed between the client sending commands and the server processing commands. If the client writes too fast or the server reads too slowly, this will It will lead to buffer overflow. Once the buffer overflows, it will cause a series of performance problems. Let’s talk about it in detail below.
Client buffering mechanism
Redis allocates an input buffer and an output buffer for each client. The input buffer will temporarily store the client's request command, and the Redis main thread The command will be obtained from the buffer. After Redis processes the command, the result will be written to the output buffer and returned to the client through the output buffer, as shown below
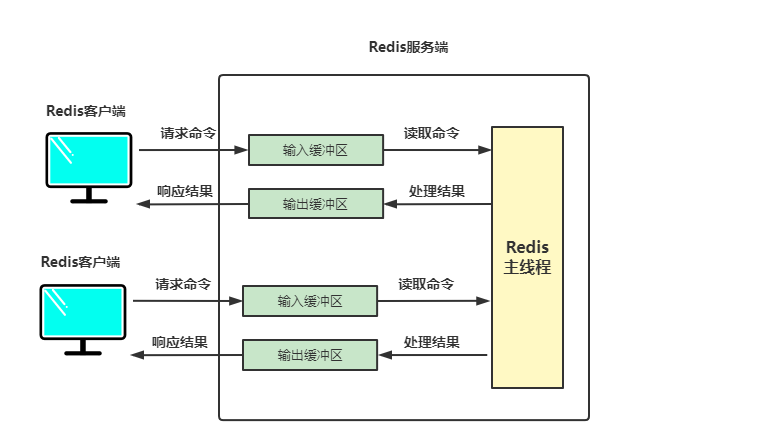
Coping with input buffer overflow
Input buffer overflow is generally caused by two situations
The data is written too fast, or the data written to bigkey fills up the data buffer district.
The server processes data too slowly. Generally, the main thread is blocked and cannot respond to client requests normally.
View the input buffer information
We can use client list to view the specific information of the input buffer
127.0.0.1:6379> client list id=13 addr=127.0.0.1:50484 fd=7 name= age=1136 idle=1 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client user=default id=14 addr=127.0.0.1:50486 fd=8 name= age=1114 idle=6 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=client user=default
Each connection The previous client will have one more input buffer information. The above command is the result of my local connection to the two clients. When we view the buffer, we mainly focus on the two memory-related parameters
qbuf : The length of the buffer that has been used (in bytes, 0 means no buffer is allocated).
qbuf-free: The remaining free space in the buffer (in bytes), the above client's qbuf=26, the free buffer qbuf-free=32742, then the total allocated memory size It is 26 32742=32768 bytes, which is 32KB.
If qbuf-free in the input buffer information is very small and qbuf is very large, you need to pay attention. At this time, the input buffer may have almost overflowed. If there is still A large number of requests are written to the input buffer. Redis's solution is to close the connection with this client, so the business data will not be accessible normally.
Another problem is that the input buffer exists for every client. When the sum of the input buffer memory of all clients exceeds the maxmemory configuration, memory elimination will occur and some of the eliminated data will be accessed again. It needs to be obtained from the background database, and the acquisition time is definitely much slower than direct reading from Redis, so this is also a reason for the delay in Redis.
How to solve input buffer overflow
The essence of input buffer overflow is that the capacity of the buffer is insufficient, so the first idea is to expand the size of the input buffer. Unfortunately, Redis does not provide it to us. Modify the configuration of the input buffer size. Redis requires that the input buffer of each client cannot exceed 1G. Note that it is for each client! ! ! , if the client's input buffer exceeds 1G, the client connection will be closed, so this will not work.
Then it can only send the size of the data from the client and the speed of command processing by the server. The client needs to avoid bigkey writing. Bigkey has too many disadvantages and generally needs to be split. Secondly, the command processing on the server The speed generally depends on whether the main thread is blocked. You need to try to avoid blocking operations such as AOF file rewriting, key value deletion, fork threads, etc.
Coping with output buffer overflow
For the server, the input information of the client is usually unpredictable, but the output information is mostly predictable. For example, the Set command returns a simple OK, another example is some error messages. Redis allocates 16KB of fixed buffer space for these constant return messages. That is to say, the output buffer is divided into two parts. One part is the fixed return message of the output buffer, and the other part is the variable return message. .
Output buffer overflow is divided into three situations
Output key values with large capacity such as bigkey.
The client executes the Monitor command to monitor Redis execution.
The buffer setting is unreasonable.
Bigkey is a common problem. When the server outputs a command such as bigkey or keys, the test on the output buffer is very great, because the query will occupy the input for a moment. Buffer a large amount of memory space.
Execution of the Monitor command
The Monitor command is generally a debug command, used to monitor the specific execution of Redis and can return every command processed by the server.
127.0.0.1:6379> monitor OK 1652184977.609761 [0 127.0.0.1:50484] "get" "name" 1652185391.529292 [0 127.0.0.1:50484] "set" "test" "lisi" ......
Keeping running the monitor will always occupy the output buffer. That is to say, the longer it occupies, the easier it is to cause the output buffer to overflow. Therefore, the Monitor command is only suitable for debugging environments and cannot be executed in production. Order.
The output buffer setting is unreasonable
The size of the input buffer cannot be set, but the output buffer can be set. We can pass the configuration itemclient-output-buffer-limit To set, the content of the setting is the memory size of the two parts
. When the buffer configuration size is exceeded, the server will close the connection with the client.
持续写入的时间限制和持续写入的容量限制,当超过持续写入时间限制和容量限制,服务端也会强制关闭和客户端的连接。
客户端种类
在聊缓冲区配置时,我们需要先了解下客户端的种类,本文中强调的客户端并不是单纯指通过命令./redis-cli -c -h 127.0.0.1 -p 6379去连接Redis服务器这类客户端称为常规客户端,我们还有通过消息订阅Redis频道的客户端,还有一种最为特殊的主从同步,从节点也是一个特殊的客户端称为从节点客户端。
配置项client-output-buffer-limit也是针对这三种,给出了不一样的配置,如下所示
## 普通客户端配置 client-output-buffer-limit normal 0 0 0 ## 从节点客户端配置 client-output-buffer-limit replica 256mb 64mb 60 ## 消息订阅频道的客户端 client-output-buffer-limit pubsub 32mb 8mb 60 ######################配置解释###################### ## 第一个参数:代表分配给客户端的缓存大小,为0代表没有限制 ## 第二个参数:表示持续写入的最大内存,为0代表没有限制 ## 第三个参数:表示持续写入的最长时间,为0代表没有限制
普通客户端设置
普通客户端就是传输的一些普通的指令,一个指令发送完需要等待其返回后才会发送下一个指令,也就是说只要不是返回的bigkey数据,占用输出缓冲区的内存就极少,能够立即发送给客户端响应,所以一般正常客户端默认配置都是0,也就是不限制。
消息订阅频道客户端
当订阅频道产生消息后,会将消息通过输出缓冲区发送给客户端,这种属于非阻塞的方式,一瞬间可能有多个指令到达,所以需要指定缓冲区大小。
如何解决输出缓冲区溢出
到这里其实我们已经能够得到输出缓冲区溢出的解决方案了
bigkey应当避免使用。
Monitor命令只在调试的时候使用,不能应用到生产。
合理设置输出缓冲区上限、持续写入时间上限以及持续写入内存容量上限。
主从集群中的缓冲区
除了输入缓冲区和输出缓冲区外在主从集群场景下还存在两种缓冲区,我们称为复制缓冲区和复制积压缓冲区,这两个缓冲区的溢出和输入输出缓冲区稍有不同。
复制缓冲区
复制缓冲区这个名词看着很陌生,但是我们之前在聊主从同步时讲过,主从全量同步期间从节点会加载主节点的RDB文件,这时主节点同样还能写入数据,但是从节点在加载RDB文件没办法实时同步,所以Redis就为每一个从节点开辟了一片空间,用来存放主从全量同步期间产生的操作命令,这就是replication buffer,也就是复制缓冲区。
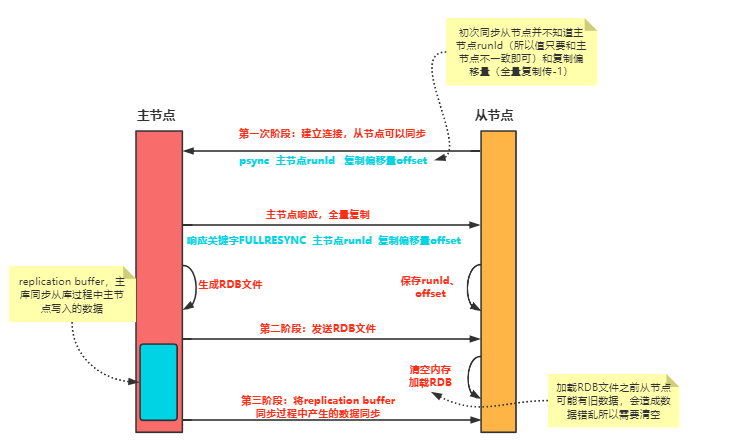
复制缓冲区溢出
复制缓冲区什么时候会溢出呢?
当从节点在加载RDB文件这个过程中如果存在大量的写操作就会造成复制缓冲区内存溢出。
从节点加载RDB文件的时间过长。
发生溢出后,主节点会关闭与从节点的连接,导致全量同步失败。
解决复制缓冲区溢出
控制主节点实例的大小,减小生成的RDB文件,这样就能减少从节点加载RDB文件的时间,减小复制缓冲区的压力。
从节点其本质就是主节点的特殊客户端,所以使用的是输出缓冲区(也就是指replication buffer),可以设置client-output-buffer-limit replica 256mb 64mb 60扩大缓冲区大小。
注意:主节点上的复制缓冲区会为每一个从节点分配一个,那么从节点的数量过多即使每个从节点没有达到maxmemory,但累加的结果也会给主节点带来内存压力。
复制积压缓冲区
复制积压缓冲区溢出
主从集群在写操作时会将操作写入复制缓冲区和复制积压缓冲区中,一旦网络发送故障后恢复连接,在2.8版本之前主从节点会进行全量同步开销非常大,所以2.8版本后还是采用了增量同步,仅仅将网络断开这段时间的操作同步给从节点,所以在网络恢复连接后从节点会将自己的复制偏移量slave_repl_offset发送给主节点,主节点将自身的写入偏移量master_repl_offset和slave_repl_offset在复制积压缓冲区中做对比得到网络断连期间的操作。
复制积压缓冲区又叫repl_backlog_buffer,是一个环形缓冲区,同步示意图如下。
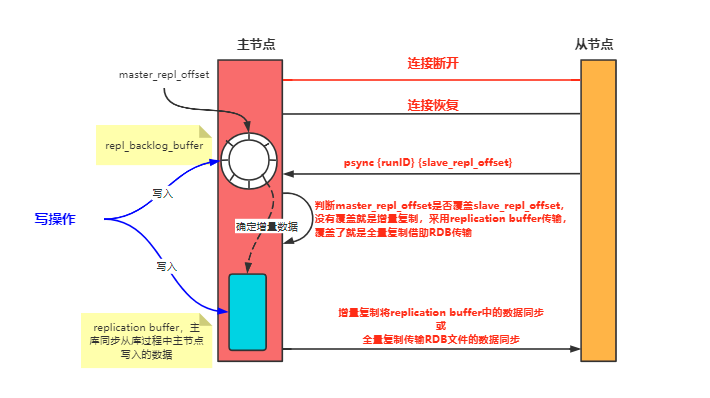
复制积压缓冲区溢出其实也就是因为复制积压缓冲区是一个有限环形结构,一般主节点写入偏移量要大于从节点的读取偏移量,但如果写入偏移量覆盖了从节点的读取偏移量这就引发了复制积压缓冲区溢出。
Solve the replication backlog buffer overflow
Generally, adjust the size of the repl_backlog_size parameter, expand the size of the replication backlog buffer, and reduce the write offset of the master node to cover the read offset of the slave node. risk.
The above is the detailed content of Example analysis of Redis buffer mechanism. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
