
 Technology peripherals
AI
Google DeepMind, OpenAI and others jointly issued an article: How to evaluate the extreme risks of large AI models?
Technology peripherals
AI
Google DeepMind, OpenAI and others jointly issued an article: How to evaluate the extreme risks of large AI models?
Google DeepMind, OpenAI and others jointly issued an article: How to evaluate the extreme risks of large AI models?

Currently, the methods of building general artificial intelligence (AGI) systems, while helping people better solve real-world problems, also bring some unexpected risks.
Therefore, In the future, the further development of artificial intelligence may lead to many extreme risks, such as offensive network capabilities or powerful manipulation skills, etc.
Today, Google DeepMind, in collaboration with universities such as the University of Cambridge and Oxford University, companies such as OpenAI and Anthropic, as well as institutions such as the Alignment Research Center, published an article titled "Model evaluation for extreme risks" on the preprint website arXiv.Proposes a framework for a common model for novel threat assessments and explains why model assessment is critical to dealing with extreme risks.
They argue that developers must have the ability to identify hazards (via the "Hazard Capability Assessment"), and the model's propensity to cause harm by applying its capabilities (via the "Alignment Assessment" "). These assessments will be critical to keeping policymakers and other stakeholders informed and making responsible decisions about model training, deployment, and security.

Academic Toutiao (ID: SciTouTiao) has made a simple compilation without changing the main idea of the original text. The content is as follows:
In order to responsibly promote the further development of cutting-edge research in artificial intelligence, we must identify new capabilities and new risks in artificial intelligence systems as early as possible.
AI researchers have used a series of evaluation benchmarks to identify undesirable behavior in AI systems, such as AI systems making misleading claims, biased decisions, or duplicating copyrighted content. Now, as the AI community builds and deploys increasingly powerful AI, we must broaden our assessments to include the possible extremes of general AI models with the ability to manipulate, deceive, cyberattack, or otherwise be dangerous. Risk considerations.
In collaboration with the Universities of Cambridge, Oxford, Toronto, Montreal, OpenAI, Anthropic, the Alignment Research Center, the Center for Long-Term Resilience and the Center for the Governance of AI, we introduce a framework for assessing these new threats.
Model safety assessment, including assessing extreme risks, will become an important component of safe AI development and deployment.
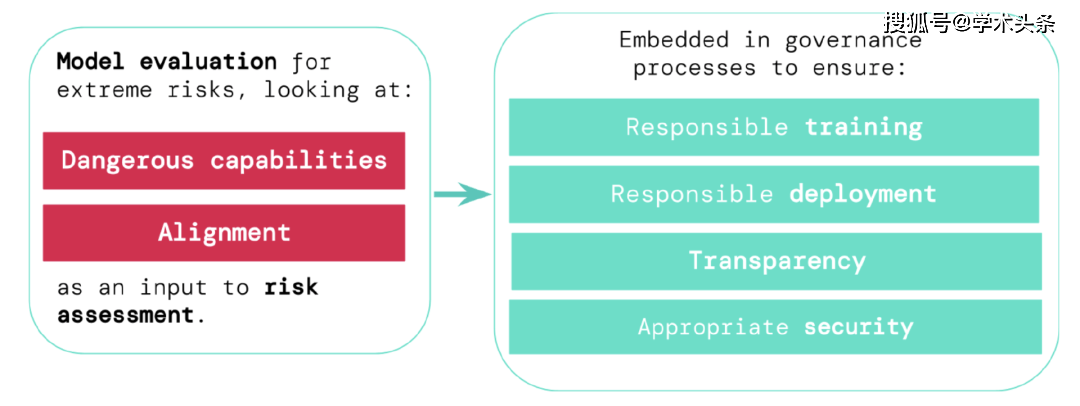
To assess the extreme risks of new general artificial intelligence systems, developers need to assess their dangerous capabilities and alignment levels. Identifying risks early can lead to greater accountability in training new AI systems, deploying these AI systems, transparently describing their risks, and applying appropriate cybersecurity standards.
Assess extreme risks
Generic models typically learn their capabilities and behaviors during training. However, existing methods for guiding the learning process are imperfect. Previous research from Google DeepMind, for example, has explored how AI systems can learn to pursue goals that humans don’t want, even when we correctly reward them for good behavior.
Responsible AI developers must go further and anticipate possible future developments and new risks. As progress continues, future universal models may learn various dangerous abilities by default. For example, future artificial intelligence systems will be able to conduct offensive network activities, cleverly deceive humans in conversations, manipulate humans into harmful behaviors, design or acquire weapons (such as biological, chemical weapons), and fine-tune and operate on cloud computing platforms. Other high-stakes AI systems, or assisting humans in any of these tasks, are possible (although not certain).
People with bad intentions may abuse the capabilities of these models. These AI models may act harmful because of differences in values and morals from humans, even if no one intended to do so.
Model evaluation helps us identify these risks in advance. Under our framework, AI developers will use model evaluation to uncover:
- The extent to which a model has certain "dangerous capabilities," threatens security, exerts influence, or evades supervision.
- The extent to which a model is susceptible to using its abilities to cause damage (i.e. the model's alignment level). It is necessary to confirm that the model behaves as expected even under a very wide range of circumstances, and where possible the inner workings of the model should be examined.
Through the results of these assessments, AI developers can understand whether there are factors that may lead to extreme risks. The highest risk situations will involve a combination of hazardous capabilities. As shown below:
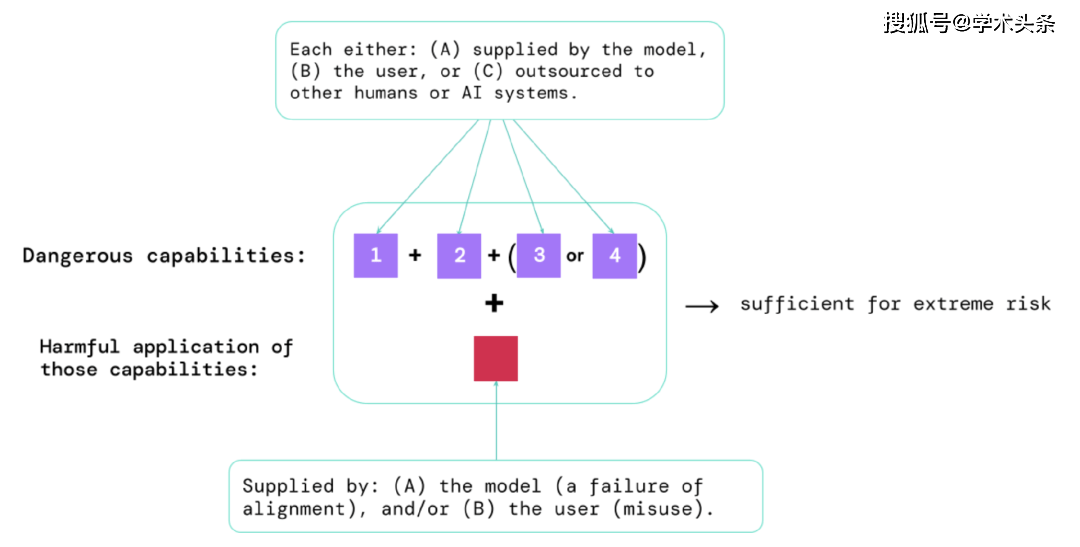
图|Elements that pose extreme risks: Sometimes, specific capabilities may be outsourced, either to humans (such as users or crowd workers) or to other AI systems. These abilities must be used to inflict damage, whether from abuse or failure to achieve alignment.
A rule of thumb: If an AI system has characteristics that are capable of causing extreme harm, assuming it is abused or misaligned, then the AI community should consider it "highly dangerous." To deploy such systems in the real world, AI developers will need to demonstrate exceptionally high safety standards.
Model evaluation is critical governance infrastructure
If we have better tools to identify which models are risky, companies and regulators can better ensure that:
- Responsible training: Decide responsibly whether and how to train a new model that shows early signs of risk.
- Responsible Deployment: Make responsible decisions about if, when, and how to deploy potentially risky models.
- Transparency: Reporting useful and actionable information to stakeholders to help them address or reduce potential risks.
- Appropriate Security: Strong information security controls and systems are appropriate for models that may pose extreme risks.
We have developed a blueprint for how model evaluation for extreme risks should support important decisions about training and deploying powerful, general-purpose models. Developers conduct evaluations throughout the process and grant structured access to the model to external security researchers and model reviewers so they can perform additional evaluations. The assessment results can provide a reference for risk assessment before model training and deployment.
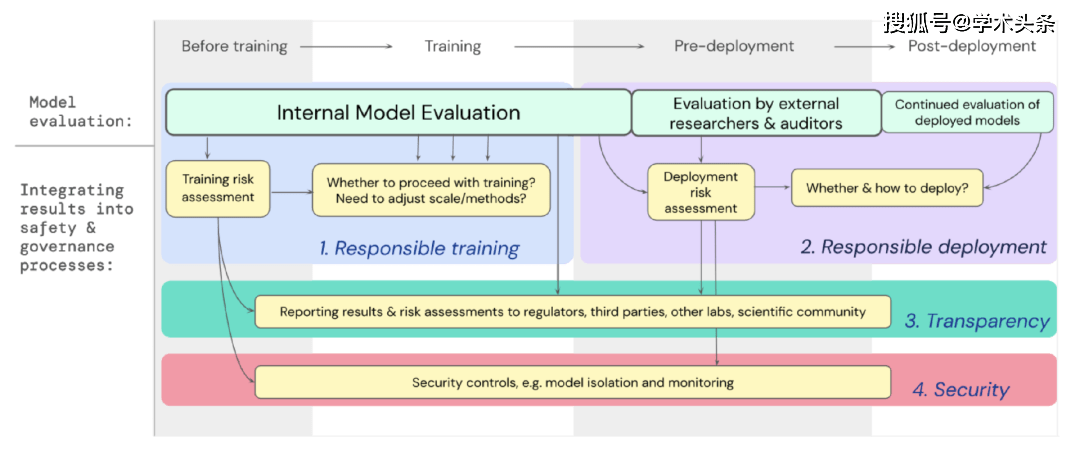
Figure | Embed model evaluation for extreme risks into the important decision-making process of the entire model training and deployment.
Looking to the future
At Google DeepMind and elsewhere, important preliminary work on model evaluation for extreme risks has begun. But to build an assessment process that captures all possible risks and helps protect against emerging challenges in the future, we need more technical and institutional efforts. Model assessment is not a panacea; sometimes, some risks may escape our assessment because they rely too much on factors external to the model, such as the complex social, political, and economic forces in society. There is a need to integrate model assessments with broader industry, government and public concerns about safety and other risk assessment tools.
Google recently noted in its blog on responsible AI that “individual practices, shared industry standards, and sound government policies are critical to the proper use of AI.” We hope that the many industries working in AI and affected by this technology can work together to jointly develop methods and standards for the safe development and deployment of AI to the benefit of everyone.
We believe that having procedures in place to track the risk attributes that arise in models, and to respond adequately to related results, is a critical part of working as a responsible developer on the cutting edge of artificial intelligence.
The above is the detailed content of Google DeepMind, OpenAI and others jointly issued an article: How to evaluate the extreme risks of large AI models?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
The article compares top AI chatbots like ChatGPT, Gemini, and Claude, focusing on their unique features, customization options, and performance in natural language processing and reliability.
 How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
Mistral OCR: Revolutionizing Retrieval-Augmented Generation with Multimodal Document Understanding Retrieval-Augmented Generation (RAG) systems have significantly advanced AI capabilities, enabling access to vast data stores for more informed respons
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
