

What causes Redis breakdown avalanche and how to solve it

1. Foreword
As we all know, one of the bottlenecks of computers is IO. In order to solve the problem of mismatch between memory and disk speed, cache is generated to put some hot data in the memory for use at any time. Take it at will, reduce the request connection to the database, and prevent the database from hanging. It should be noted that whether it is breakdown or the penetration and avalanche mentioned later, it is all under the premise of high concurrency, such as when a certain hot key in the cache fails.

2. Cause of the problem
There are two main reasons:
1. Key expired;
2. Key is eliminated by page replacement.
For the first reason, in Redis, Key has an expiration time. If the key expires at a certain moment (if the mall is doing activities, starting at zero o'clock), then after zero o'clock, a certain key will expire. All product query requests will be pressed onto the database, causing the database to collapse.
For the second reason, because the memory is limited, new data must be cached all the time and old data must be eliminated. Therefore, in a certain page replacement strategy (illustration of common page replacement algorithms), data must be eliminated , if no one cares about certain products before the event, they will definitely be eliminated.
3. Processing ideas for dealing with breakdown
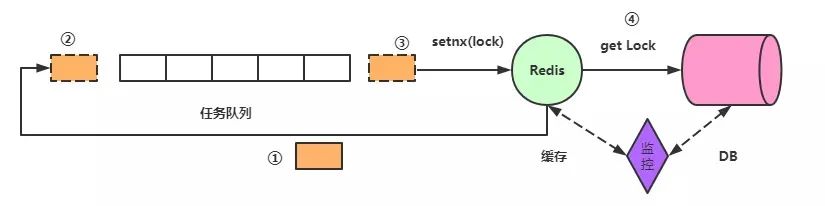
The normal processing request is as shown in the figure:

Since key expiration is inevitable, high When traffic comes to Redis, according to the single-threaded characteristics of Redis, it can be considered that tasks are executed sequentially in the queue. When the request reaches Redis and finds that the Key has expired, an operation is performed: setting a lock.
The process is roughly as follows:
The request reaches Redis, and it is found that the Redis Key has expired. Check whether there is a lock. If there is no lock, return to the back of the queue.
Set the lock. Note that this should be setnx(), not set(), because other threads may have set the lock.
Get the lock, take When the lock is reached, go to the database to fetch the data, and release the lock after the request returns.

# But it raises a new question. What if the request to get the data hangs after getting the lock? That is, the lock is not released. Other processes are waiting for the lock. The solution is:
Set an expiration time for the lock. If it reaches the expiration time and has not been released, it will be automatically released. The problem comes again. It is easy to say that the lock is hung, but if it is a lock What about timeout? That is, the data is not retrieved within the set time, but the lock expires. The common idea is that the lock expiration time value increases, but it is unreliable because the first request may timeout. If the subsequent request It also times out. After multiple timeouts in a row, the lock expiration time value is bound to be extremely large. This has too many disadvantages.
Another idea is to start another thread and monitor it. If the thread fetching data does not hang up, appropriately delay the expiration time of the lock.
4. Penetration
The main reason for penetration is that many requests are accessing data that does not exist in the database. For example, a mall selling books has been requested. To query tea products, since Redis cache is mainly used to cache hot data, data that does not exist in the database cannot be cached. This abnormal traffic will directly reach the database and return "none" query results.
To deal with this kind of request, the solution is to add a layer of filters to the access request, such as Bloom filter, enhanced Bloom filter, and cuckoo filter.

In addition to Bloom filters, you can add some parameter checks. For example, database data IDs are generally increasing. If you request a parameter such as id = -10, it will inevitably be bypassed. Redis, to avoid this situation, can perform operations such as user authenticity verification.
5. Avalanche
Avalanche is similar to breakdown. The difference is that breakdown means that a hotspot key fails at a certain moment, while avalanche means that a large number of hotspot keys fail in an instant. There are many hotspot keys on the network. Blogs are emphasizing that the strategy to solve the avalanche is to randomize the expiration time. This is very inaccurate. For example, when a bank is doing activities, the interest coefficient was 2% before, but after zero point, the coefficient is changed to 3%. This situation can change the user's interest rate. Will the corresponding key be changed to expire randomly? If past data is used, it is called dirty data.
Obviously not possible, save money too f0c;You save 3 million in interest until the end of the year, and the next door only has 2 million, there is no need to fight, just kidding~
The correct idea is, first of all, you must look at Check whether the key expiration is related to time. If it is not related to time, it can be solved by random expiration time.
If it is related to time point, for example, the bank just mentioned changes a certain coefficient on a certain day, then a strong dependency breakdown solution must be used. The strategy is to update all keys with the past thread first.

While updating the hotspot key in the background, the business layer delays the incoming requests, such as briefly sleeping for a few milliseconds or seconds, to spread the pressure on subsequent hotspot key updates. .
The above is the detailed content of What causes Redis breakdown avalanche and how to solve it. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
Redis uses hash tables to store data and supports data structures such as strings, lists, hash tables, collections and ordered collections. Redis persists data through snapshots (RDB) and append write-only (AOF) mechanisms. Redis uses master-slave replication to improve data availability. Redis uses a single-threaded event loop to handle connections and commands to ensure data atomicity and consistency. Redis sets the expiration time for the key and uses the lazy delete mechanism to delete the expiration key.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
How to make message middleware for redis
Apr 10, 2025 pm 07:51 PM
Redis, as a message middleware, supports production-consumption models, can persist messages and ensure reliable delivery. Using Redis as the message middleware enables low latency, reliable and scalable messaging.
