

To put it simply, table return means that MySQL must first query the primary key index, and then use the primary key index to locate the data.
Below, we analyze and answer some questions:
What is a clustered index? What is a non-clustered index?
Why do we need to find the primary key index first when returning a table?
What is the difference between primary key index and non-primary key index?
How to avoid returning the table?
MySQL indexes are classified from different perspectives, such as: by data structure, by logical perspective, and by physical storage.
There are two types of indexes according to physical storage: Clustered index and Non-clustered index.
Simply put, clustered index is the primary key index.
Beyond the primary key index is the non-clustered index. Non-clustered index is also called auxiliary index or secondary index.
Same points: Both use B Tree.
Differences: The data stored in leaf nodes is different
The leaf nodes of the primary key index store a complete row of data;
The leaf nodes of the non-primary key index store the primary key value. The leaf node does not contain all the data of the record. In addition to the key used for sorting, the non-primary key leaf node also contains a bookmark (bookmark), which stores the key of the clustered index.
So what are the differences in the use of these two indexes?
Query using primary key index:
# 主键索引的的叶子节点存储的是**一行完整的数据**, # 所以只需搜索主键索引的 B+Tree 就可以轻松找到全部数据 select * from user where id = 1;
Query using non-primary key index:
# 非主键索引的叶子节点存储的是**主键值**, # 所以MySQL会先查询到 name 列的索引的 B+Tree,搜索得到对应的主键值 # 然后再去搜索该主键值查询主键索引的 B+Tree 才可以找到对应的数据 select * from user where name = 'Jack';
It can be seen that non-primary key index is used B Tree is used one more time than the primary key index.
The key to understanding clustered indexes and non-clustered indexes lies in the understanding of B Tree.
Use a picture to represent it, and I won’t explain the rest too much:
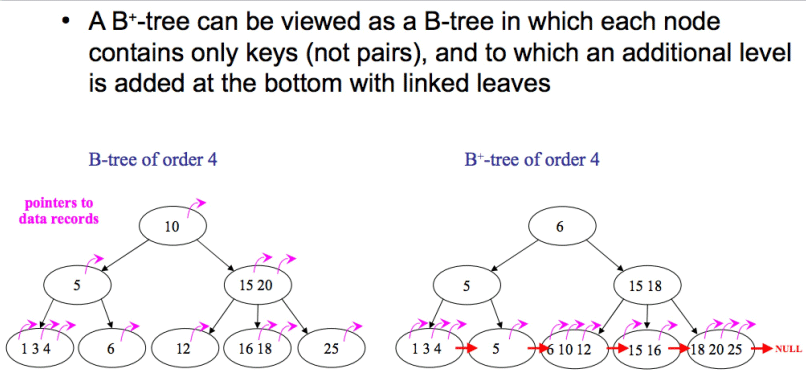
This is just simple Let’s introduce the difference between B-Tree and B-Tree:
# In B-tree, only the leaf nodes have pointers to records, while in B-tree, all nodes have, Index items that appear in internal nodes will no longer appear in leaf nodes.
All leaf nodes in the B-tree are connected together through pointers, while the B-tree does not.
Use a covering index. The so-called covering index means that the index contains all the fields in the query. In this case, there is no need to perform a query back to the table.
The above is the detailed content of What does MySQL table return refer to?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



