

Specific cases are described in detail below
Scenarios that are not suitable for index creation:
It is not recommended to create a table with a relatively small amount of data Index
It is not recommended to create an index on fields with a large amount of duplicate data (similar to: gender fields)
It is not recommended for tables that require frequent updates Create an index
The unused fields behind where, group by, order by are not indexed
Do not define redundant indexes
Index failure scenario:
Use filter conditions not equal to (!=, )
Filter conditions use is not null
Use functions or calculations on index fields
When using a joint index, you need Satisfy the "best left prefix rule", otherwise it will be invalid
When type conversion is used, the index will also be invalid
When using range query Sometimes, some fields of the joint index become invalid (where age >18)
In the like field, if it starts with %, the index becomes invalid (where name like ‘�c’)
When using or to query, non-index fields appear before and after or, and the index is invalid
The character sets of the table and the library are inconsistent, and the return Causing index failure
Knowledge point:
It is not recommended to have more than 6 indexes for each table (it takes up space and reduces the table update speed)
The final decision is whether to use the index or the optimizer
The optimizer will determine the query cost based on the amount of data, database version, and data selection read Comparison to decide whether to use the index
When creating the index, set the fields that require range matching at the end of the index to avoid failure
When creating the table, set the field to not null and set the default value. When you need to find records without values, you can use where xxx = default value. Using is not null will cause the index to fail
When searching on the page, please use the left side or full-text fuzzy matching (like '�c')
For fields with better filterability, build them in front of the joint index. In this way, more data can be filtered first
Scenario 1: Table with less data
When there is relatively little data When the time comes, the advantage of the index is not obvious, because the storage engine of the database is also very fast. Compared with needing to query the index before performing the table return operation, the performance of direct query may be higher, so the table with relatively less data It is not recommended to create an index
Scenario 2: Fields with a large amount of duplicate data
Similar to the gender field, there are only two different values of "male" and "female", so half of the data in the index is Half of the data for "male" is "female", so establishing an index cannot perform fast queries, etc., so it is not recommended to create an index on a column with a large amount of duplicate data
Scenario 3: Frequently updated tables (update /delete/insert)
Because when data is updated in the table, the index also needs to be maintained accordingly. If a table needs to be added, deleted and modified frequently in the near future, it will take a lot of time to maintain the index. , it is not recommended to create an index. You can delete the index when frequent update operations are required, and rebuild the index after the update is completed
Scenario 4: Unused fields (where/group by/order by)
It is not necessary to create an index for the fields after where/group by/order by, because the index will not be used
Scenario 5: Do not define redundant indexes
create index username_password_address on xiao(username,password,address); -- 如果建立了第一个索引,那么就没有必要建立第二个索引 create index username on xiao (username); --第二个索引就是冗余索引,因为第一个已经是先根据username排序的索引 --也就是第二个索引的功能完全可以由第一个索引实现
Here because username As the first field of the first joint index, the index is sorted by username. If the username is the same, it is sorted by password and address. Therefore, the function of using the username column alone as an index is realized, that is, the second Indexes are redundant
Scenario 1: Perform operations (functions, etc.) on the indexed fields, resulting in index failure
Here is the first step for age The index was created, and the age index was used in the first query process, but the second key value was null (index failure). The reason for the index failure was that age was calculated after where during the second query. The computer does not know what calculation is being performed, so it will calculate age 1 and compare it with 1. The index will become invalid.
Similar to using the function concat() on a field, it will cause index failure
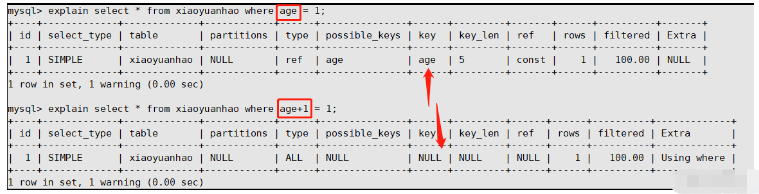
Scenario 2: Using not equal to (where age != 18)
When using equivalent operations, you can search in the index, but if it is not equal, then All data needs to be traversed, so the invalidation
explain select * from xiaoyuanhao where age = 18; explain select * from xiaoyuanhao where age != 18; --这里是在age字段上建立了普通索引,第二个查询时候索引失效
Scenario 3: Index failure using is not null
is the same as not equal. If is not null is used, then all data needs to be processed In the traversal operation, the index is invalid, but if you use is null, you can still use the index
--这里是在age字段上建立了普通索引,第二个查询时候索引失效 explain select * from xiaoyuanhao where age is null; --可以正常使用索引 explain select * from xiaoyuanhao where age is not null; --索引失效
Scenario 4: When using the joint index, you do not follow the best left prefix rule
CREATE INDEX age_classid_name ON student(age,classId,NAME); EXPLAIN SELECT * FROM student WHERE classId = 30 AND NAME = 'xiaoyuanhao'; -- 因为没有使用age字段,所以没有准许最佳左前缀原则,索引失效
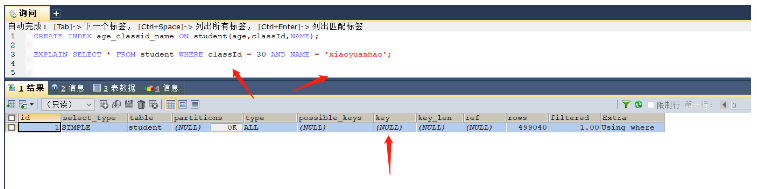
从这里可以看出是没有使用索引的(key = null),因为创建的索引是先按照age进行排序,在age相同的情况下按照classId和name排序,如果在查询的时候需要直接按照classId进行排序查找,那么就无法使用该索引,即索引失效。
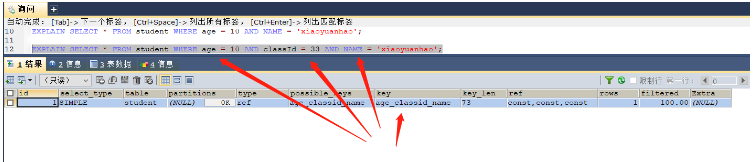
如果需要使用使用索引,那么就一定需要到联合索引的第一个字段age,案例如下
EXPLAIN SELECT * FROM student WHERE age = 10 AND NAME = 'xiaoyuanhao'; EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 33 AND NAME = 'xiaoyuanhao'; --两者都是使用age字段索引,所以索引有效

场景五:类型转换导致索引失效
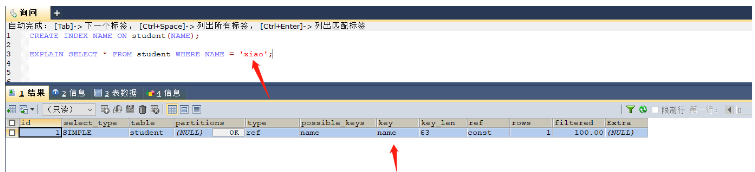
CREATE INDEX NAME ON student(NAME); -- 这里的name字段是varchar类型 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 本次查询是可以使用索引的,因为类型都是一致的,都是字符串 EXPLAIN SELECT * FROM student WHERE NAME = 123; -- 本次查询则无法使用索引,因为是将数字类型123转换为字符类型
没有发生类型转换,使用索引key = name
发生了类型转换,无法使用索引kye = null,索引失效
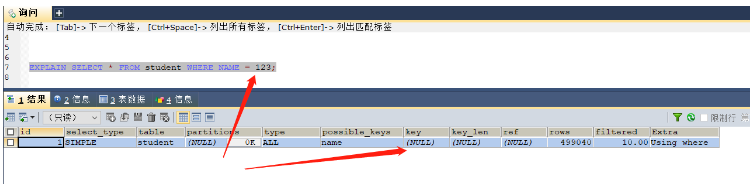
使用索引的时候一定需要保证数据类型是一致的,否则系统就需要进行转换,那么就无法使用索引
场景六:使用范围查询导致联合索引其他字段失效
create index age_classId_name on student (age,classId,name); EXPLAIN SELECT * FROM student WHERE age = 10 AND classId > 20 AND NAME = 'xiaoyuanhao'; -- 这里只能使用age,classId,索引的前两个字段 EXPLAIN SELECT * FROM student WHERE age = 10 AND classId = 20 AND NAME = 'xiaoyuanhao'; -- 这里可以使用完整的索引,因为都是等值连接
在classId字段上使用范围查询,导致name字段失效,有效索引长度为63

使用的都是等值匹配,整个索引皆可用,有效索引长度为73

也就是在对于联合索引来说,如果在使用的时候是等值匹配,那么就可以重复的利用索引,如果不是等值匹配,那么该字段也是可以使用索引的,但是该字段右边的字段就将失效
建议在建立索引的时候将需要范围匹配的字段建立在索引的最后面
场景七:在使用like的时候,如果以%开头导致索引失效
EXPLAIN SELECT * FROM student WHERE NAME LIKE 'abc%'; -- 可以正常使用索引 EXPLAIN SELECT * FROM student WHERE NAME LIKE '%abc'; -- 这里在like中,%在前面无法使用索引
key = name,使用了该索引,索引有效
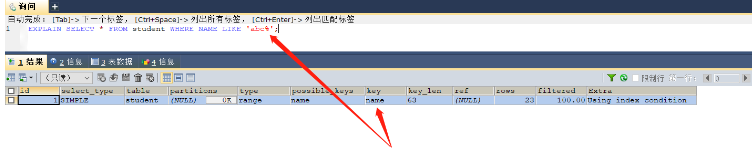
key = null,索引失效

因为建立的索引实际上是按照整个字符串的从第一个开始进行比较排序的,所以在使用like的时候,也只能够重现进行比较,如果使用的是’%abc’,那么查询的就是以abc结尾的数据,无法使用索引
场景八:or前后出现非索引字段,索引失效
-- 该表中只有name字段上的索引 CREATE INDEX NAME ON student(NAME); EXPLAIN SELECT * FROM student WHERE NAME = 'xiao'; -- 这里是可以使用name索引的 EXPLAIN SELECT * FROM student WHERE NAME = 'xiao' OR classId = 1001; -- 这个则无法使用索引,进行的是全表扫描
key = null,无法使用索引,or条件中出现非索引字段
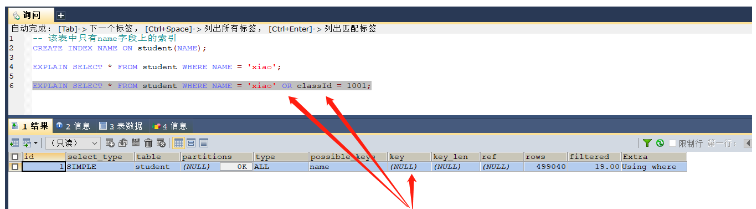
因为如果name不等于’xiao’的时候那么就会继续判断classId是否等于1001,那么实际上还是会进行全表扫描,所以索引失效(也就是进行name判断的时候可以使用索引,但是在判断classId的时候又要全表扫描,那么优化器就直接进行全表扫描),但是如果or前后的字段都有索引了,那么就就会使用索引
The above is the detailed content of What are the situations in which MySQL is not suitable for building indexes and index failures?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



