

Server failure instance analysis

1. Something went wrong
Since we are in the IT industry, we need to deal with failures and problems every day, so we can be called firefighters, running around to solve problems. However, the scope of the fault this time is a bit large, and the host machine cannot be opened.
Fortunately, the monitoring system left some evidence.
Evidence found that the machine’s CPU, memory, and file handles continued to rise with the growth of business... until monitoring could not collect the information.
What’s terrible is that there are a lot of Java processes deployed on these hosts. For no other reason than to save costs, the applications were mixed. When a host exhibits overall anomalies, it can be difficult to find the culprit.
Since the remote login has expired, impatient operation and maintenance personnel can only choose to restart the machine and start restarting the application after the restart. After a long wait, all processes returned to normal operation, but after only a short period of time, the host machine suddenly crashed.
The business has been in a state of decline, which is really annoying. It also makes people anxious. After several attempts, the operation and maintenance collapsed, and the emergency plan was launched: rollback!
There were a lot of recent online records, and some developers went online and deployed privately, so the operation and maintenance was confused: rollback. Which ones? Fortunately, someone had a bright idea and remembered that there is also the find command. Then find all the recently updated jar packages and roll them back.
find /apps/deploy -mtime +3 | grep jar$
If you don’t know the find command, it’s really a disaster. Fortunately someone knows.
I rolled back more than a dozen jar packages. Fortunately, I didn’t encounter any database schema changes, and the system finally ran normally.
2. Find the reason
There is no other way, check the logs and conduct code review.
In order to ensure the quality of the code, the scope of the code review should be limited to code changes in the last 1 or 2 weeks, because some functional codes require a certain amount of time to mature before they can shine online.
Looking at the submission record "OK" that filled the screen, the technical manager's face turned green.
"xjjdog said, "80% of programmers can't write commit records", I think 100% of you can't write it."
Everyone was quiet, enduring the pain and checking the historical changes. After everyone's unremitting efforts, we finally found some problematic codes in the mountains of shit. A group created by the CxO himself, and everyone throws code that may cause problems into it.
"The system service was interrupted for nearly an hour, and the impact was very bad." The CxO said, "The problem must be completely solved. Investors are very concerned about this issue."!
okokok, with Nail With the help of nails, everyone's gestures became uniform.
3. Thread pool parameters
There are a lot of codes, and everyone has been discussing the problematic code for a long time. This sentence can be rewritten as follows: We examined some complex code using parallel streams and nested within lambda expressions, paying special attention to the use of thread pools.
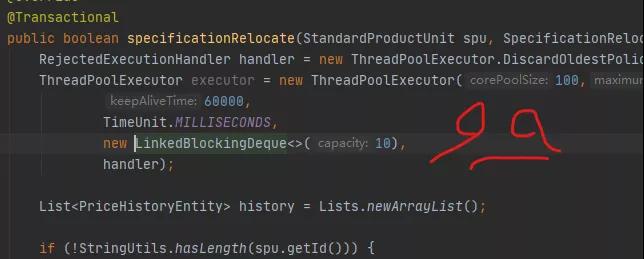
In the end everyone decided to go through the thread pool code again. One of the passages says this.
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy(); ThreadPoolExecutor executor = new ThreadPoolExecutor(100,200, 60000, TimeUnit.MILLISECONDS, new LinkedBlockingDeque(10), handler);
Not to mention, the parameters are decent, and even a rejection strategy is considered.
Java's thread pool makes programming very simple. These parameters cannot be reviewed without going through them one by one, as shown in the image above.
corePoolSize: The number of core threads. The core thread will survive after it is created.
maxPoolSize: The maximum number of threads
keepAliveTime: thread idle time
workQueue: blocking queue
threadFactory: thread creation factory
handler: rejection strategy
Let’s introduce their relationship below.
If the number of threads is less than the number of core threads and a new task arrives, the system will create a new thread to handle the task. If the current number of threads exceeds the number of core threads and the blocking queue is not full, the task will be placed in the blocking queue. When the number of threads is greater than the number of core threads and the blocking queue is full, new threads will be created to serve until the number of threads reaches the maximumPoolSize size. At this time, if there are new tasks, the rejection policy will be triggered.
Let’s talk about the rejection strategy. JDK has 4 built-in policies, the default of which is AbortPolicy, which directly throws an exception. Several others are introduced below.
DiscardPolicy is more radical than abort. It directly discards the task without even exception information.
Task processing is performed by the calling thread. This is How CallerRunsPolicy is implemented. When the thread pool resources of a web application are full, new tasks will be assigned to Tomcat threads for execution. In some cases, this method can reduce the execution pressure of some tasks, but in more cases, it will directly block the running of the main thread
DiscardOldestPolicy discards the front of the queue Task, and then try to execute the task again
This thread pool code is newly added, and the parameter settings are also reasonable, and there is no big problem. Using the DiscardOldestPolicy rejection policy is the only possible risk. When there are a lot of tasks, this rejection policy will cause tasks to be queued and requests to time out.
Of course we cannot let go of this risk. To be honest, it is the most likely risk code that can be found so far.
"Change DiscardOldestPolicy to the default AbortPolicy, repackage it and try it online." The technical guru said in the group.
4. What is the problem?
As a result, after the grayscale service was launched, the host died shortly after. It's the reason why it didn't run, but why?
The size of the thread pool, the minimum is 100, the maximum is 200, nothing is too much. The capacity of the blocking queue is only 10, so nothing will cause a problem. If you say it's caused by this thread pool, I won't believe you even to death.
But the business department reported that if this code is added, it will die, but if it is not added, it will be fine. The technical experts are scratching their heads and wondering about her sister.
In the end, someone finally couldn't help it anymore and downloaded the business code to debug it.
When he opened Idea, he was instantly confused and then understood instantly. He finally understood why this code caused problems.
The thread pool is actually created in the method!
When every request comes, it will create a thread pool until the system restarts Resources cannot be allocated.
It’s so domineering.
Everyone is paying attention to how the parameters of the thread pool are set, but no one has ever doubted the location of this code.
The above is the detailed content of Server failure instance analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 How to solve the problem that eMule search cannot connect to the server
Jan 25, 2024 pm 02:45 PM
How to solve the problem that eMule search cannot connect to the server
Jan 25, 2024 pm 02:45 PM
Solution: 1. Check the eMule settings to make sure you have entered the correct server address and port number; 2. Check the network connection, make sure the computer is connected to the Internet, and reset the router; 3. Check whether the server is online. If your settings are If there is no problem with the network connection, you need to check whether the server is online; 4. Update the eMule version, visit the eMule official website, and download the latest version of the eMule software; 5. Seek help.
 Solution to the inability to connect to the RPC server and the inability to enter the desktop
Feb 18, 2024 am 10:34 AM
Solution to the inability to connect to the RPC server and the inability to enter the desktop
Feb 18, 2024 am 10:34 AM
What should I do if the RPC server is unavailable and cannot be accessed on the desktop? In recent years, computers and the Internet have penetrated into every corner of our lives. As a technology for centralized computing and resource sharing, Remote Procedure Call (RPC) plays a vital role in network communication. However, sometimes we may encounter a situation where the RPC server is unavailable, resulting in the inability to enter the desktop. This article will describe some of the possible causes of this problem and provide solutions. First, we need to understand why the RPC server is unavailable. RPC server is a
 Detailed explanation of CentOS installation fuse and CentOS installation server
Feb 13, 2024 pm 08:40 PM
Detailed explanation of CentOS installation fuse and CentOS installation server
Feb 13, 2024 pm 08:40 PM
As a LINUX user, we often need to install various software and servers on CentOS. This article will introduce in detail how to install fuse and set up a server on CentOS to help you complete the related operations smoothly. CentOS installation fuseFuse is a user space file system framework that allows unprivileged users to access and operate the file system through a customized file system. Installing fuse on CentOS is very simple, just follow the following steps: 1. Open the terminal and Log in as root user. 2. Use the following command to install the fuse package: ```yuminstallfuse3. Confirm the prompts during the installation process and enter `y` to continue. 4. Installation completed
 How to configure Dnsmasq as a DHCP relay server
Mar 21, 2024 am 08:50 AM
How to configure Dnsmasq as a DHCP relay server
Mar 21, 2024 am 08:50 AM
The role of a DHCP relay is to forward received DHCP packets to another DHCP server on the network, even if the two servers are on different subnets. By using a DHCP relay, you can deploy a centralized DHCP server in the network center and use it to dynamically assign IP addresses to all network subnets/VLANs. Dnsmasq is a commonly used DNS and DHCP protocol server that can be configured as a DHCP relay server to help manage dynamic host configurations in the network. In this article, we will show you how to configure dnsmasq as a DHCP relay server. Content Topics: Network Topology Configuring Static IP Addresses on a DHCP Relay D on a Centralized DHCP Server
 Best Practice Guide for Building IP Proxy Servers with PHP
Mar 11, 2024 am 08:36 AM
Best Practice Guide for Building IP Proxy Servers with PHP
Mar 11, 2024 am 08:36 AM
In network data transmission, IP proxy servers play an important role, helping users hide their real IP addresses, protect privacy, and improve access speeds. In this article, we will introduce the best practice guide on how to build an IP proxy server with PHP and provide specific code examples. What is an IP proxy server? An IP proxy server is an intermediate server located between the user and the target server. It acts as a transfer station between the user and the target server, forwarding the user's requests and responses. By using an IP proxy server
 How to enable TFTP server
Oct 18, 2023 am 10:18 AM
How to enable TFTP server
Oct 18, 2023 am 10:18 AM
The steps to start the TFTP server include selecting the TFTP server software, downloading and installing the software, configuring the TFTP server, and starting and testing the server. Detailed introduction: 1. When choosing TFTP server software, you first need to choose the TFTP server software that suits your needs. Currently, there are many TFTP server software to choose from, such as Tftpd32, PumpKIN, tftp-hpa, etc., which all provide simple and easy-to-use functions. interface and configuration options; 2. Download and install TFTP server software, etc.
 How to check server status
Oct 09, 2023 am 10:10 AM
How to check server status
Oct 09, 2023 am 10:10 AM
Methods to view server status include command line tools, graphical interface tools, monitoring tools, log files, and remote management tools. Detailed introduction: 1. Use command line tools. On Linux or Unix servers, you can use command line tools to view the status of the server; 2. Use graphical interface tools. For server operating systems with graphical interfaces, you can use the graphics provided by the system. Use interface tools to view server status; 3. Use monitoring tools. You can use special monitoring tools to monitor server status in real time, etc.
 What should I do if I can't enter the game when the epic server is offline? Solution to why Epic cannot enter the game offline
Mar 13, 2024 pm 04:40 PM
What should I do if I can't enter the game when the epic server is offline? Solution to why Epic cannot enter the game offline
Mar 13, 2024 pm 04:40 PM
What should I do if I can’t enter the game when the epic server is offline? This problem must have been encountered by many friends. When this prompt appears, the genuine game cannot be started. This problem is usually caused by interference from the network and security software. So how should it be solved? The editor of this issue will explain I would like to share the solution with you, I hope today’s software tutorial can help you solve the problem. What to do if the epic server cannot enter the game when it is offline: 1. It may be interfered by security software. Close the game platform and security software and then restart. 2. The second is that the network fluctuates too much. Try restarting the router to see if it works. If the conditions are OK, you can try to use the 5g mobile network to operate. 3. Then there may be more
