
Introduction to Redis
Redis is completely open source and free, complies with the BSD protocol, and is a high-performance key-value database
Redis and other key-value caches The product has the following three features:
Redis supports data persistence. It can save the data in the memory to the disk and load it again for use when restarting.
Redis not only supports simple key-value type data, but also provides storage of data structures such as list, set, zset, hash, etc.
Redis supports data backup, that is, master-slave mode data backup
Redis advantages
Extremely high performance High - Redis read speed is 110,000 times/s and write speed is 81,000 times/s.
Rich data types - Redis supports Strings, Lists, Hashes, Sets and Ordered Sets data type operations for binary cases.
Atomicity - All operations of Redis are atomic, which means that they will either be executed successfully or not executed at all if they fail. Individual operations are atomic. Transactions of multiple operations can be implemented using the MULTI and EXEC instructions to ensure atomicity.
Other features - Redis also supports publish/subscribe notifications, key expiration and other features.
Redis data type
Redis supports 5 data types: string (string), hash (hash), list (list) , set (set), zset (sorted set: ordered set)
#string
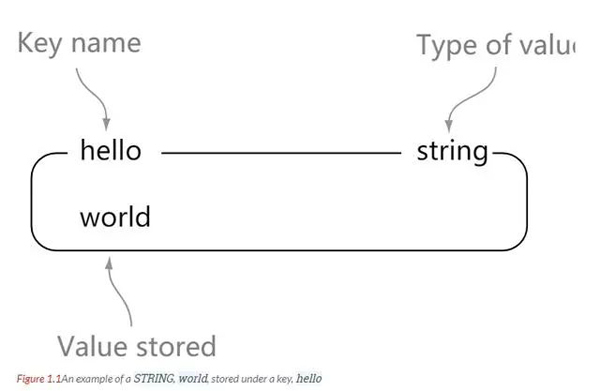
string is the most basic data type of redis. A key corresponds to a value.
string is binary safe. That is to say, the string of redis can contain any data. For example, jpg images or serialized objects.
One of the basic data types of Redis is the string type, and the value size of the string type can be up to 512 MB.
Understanding: string is like a map in java, a key corresponds to a value
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world"
hash
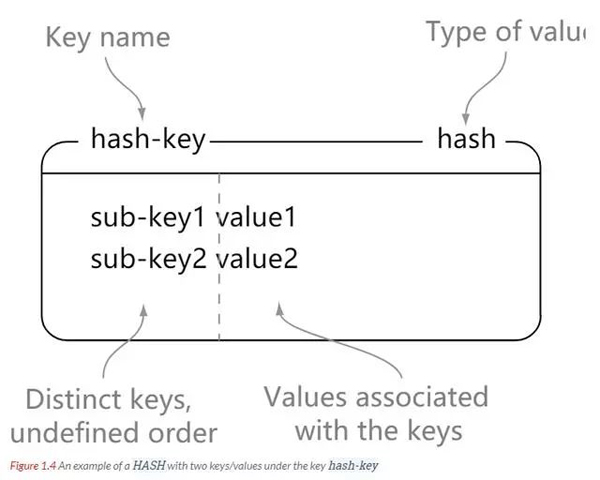
Hash collection is a Redis data type composed of key-value pairs. Redis hash is a mapping table of string type keys and values. Hash is particularly suitable for storing objects.
Understanding: You can think of hash as a key-value set. You can also think of it as a hash corresponding to multiple strings.
Differences from string : string is a key-value pair, while hash is multiple key-value pairs.
// hash-key 可以看成是一个键值对集合的名字,在这里分别为其添加了 sub-key1 : value1、 sub-key2 : value2、sub-key3 : value3 这三个键值对 127.0.0.1:6379> hset hash-key sub-key1 value1 (integer) 1 127.0.0.1:6379> hset hash-key sub-key2 value2 (integer) 1 127.0.0.1:6379> hset hash-key sub-key3 value3 (integer) 1 // 获取 hash-key 这个 hash 里面的所有键值对 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key2" 4) "value2" 5) "sub-key3" 6) "value3" // 删除 hash-key 这个 hash 里面的 sub-key2 键值对 127.0.0.1:6379> hdel hash-key sub-key2 (integer) 1 127.0.0.1:6379> hget hash-key sub-key2 (nil) 127.0.0.1:6379> hget hash-key sub-key1 "value1" 127.0.0.1:6379> hgetall hash-key 1) "sub-key1" 2) "value1" 3) "sub-key3" 4) "value3"
list
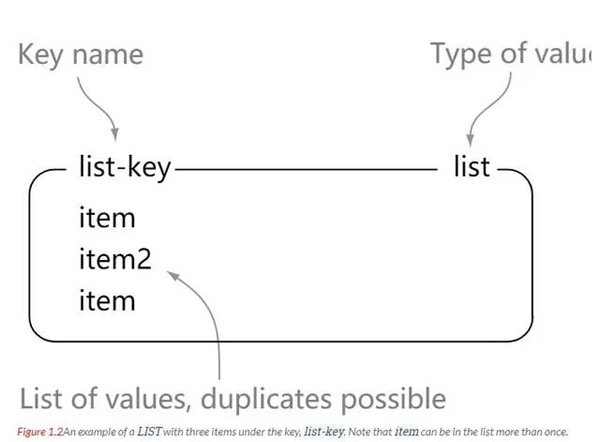
Redis lists are simple lists of strings, sorted in insertion order. We can add elements to the left or right of the list.
127.0.0.1:6379> rpush list-key v1 (integer) 1 127.0.0.1:6379> rpush list-key v2 (integer) 2 127.0.0.1:6379> rpush list-key v1 (integer) 3 127.0.0.1:6379> lrange list-key 0 -1 1) "v1" 2) "v2" 3) "v1" 127.0.0.1:6379> lindex list-key 1 "v2" 127.0.0.1:6379> lpop list (nil) 127.0.0.1:6379> lpop list-key "v1" 127.0.0.1:6379> lrange list-key 0 -1 1) "v2" 2) "v1"
We can see that list is a simple collection of strings, which is not much different from the list in Java. The difference is that the list here stores strings. The elements in list are repeatable.
set
The set of redis is an unordered collection of string type. Since the set is implemented using the data structure of a hash table, the time complexity of its insertion, deletion and search operations is O(1)
 ##
##
127.0.0.1:6379> sadd k1 v1 (integer) 1 127.0.0.1:6379> sadd k1 v2 (integer) 1 127.0.0.1:6379> sadd k1 v3 (integer) 1 127.0.0.1:6379> sadd k1 v1 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v2" 3) "v1" 127.0.0.1:6379> 127.0.0.1:6379> sismember k1 k4 (integer) 0 127.0.0.1:6379> sismember k1 v1 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 1 127.0.0.1:6379> srem k1 v2 (integer) 0 127.0.0.1:6379> smembers k1 1) "v3" 2) "v1"
Zset
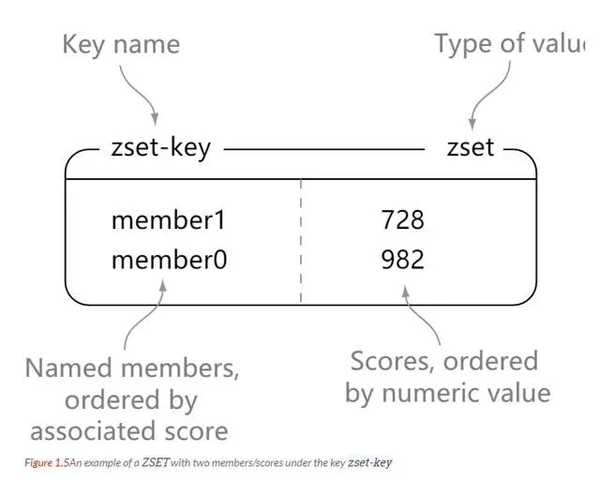
redis zset, like set, is a collection of string type elements, and the elements in the collection cannot be repeated. The difference is that each element in zset is associated with a double type score. Redis uses scores to sort the members in the set from small to large. The elements of zset are unique, but the scores can be repeated.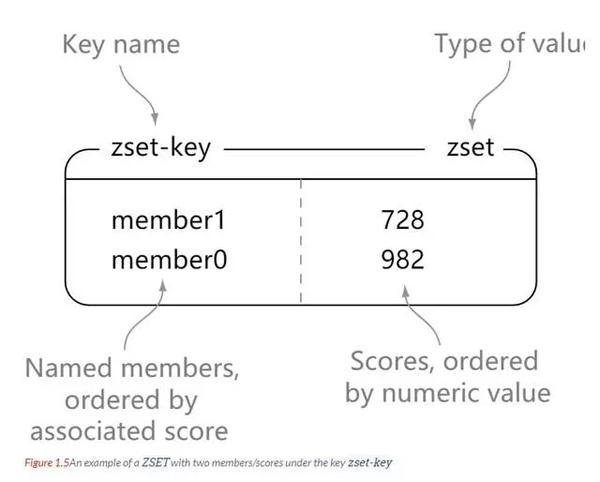
127.0.0.1:6379> zadd zset-key 728 member1 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 1 127.0.0.1:6379> zadd zset-key 982 member0 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member1" 2) "728" 3) "member0" 4) "982" 127.0.0.1:6379> zrangebyscore zset-key 0 800 withscores 1) "member1" 2) "728" 127.0.0.1:6379> zrem zset-key member1 (integer) 1 127.0.0.1:6379> zrem zset-key member1 (integer) 0 127.0.0.1:6379> zrange zset-key 0 -1 withscores 1) "member0" 2) "982"
Publish and subscribe
Generally, Redis is not used for message publishing and subscription.Introduction
Redis publish and subscribe (pub/sub) is a message communication model: the sender (pub) sends messages, and the subscribers (sub) receive messages. Redis clients can subscribe to any number of channels. The following figure shows the channel channel1 and the relationship between the three clients that subscribe to this channel - client2, client5 and client1: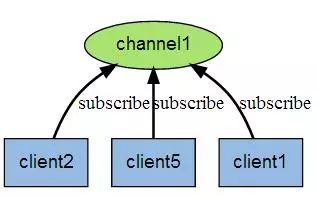
学Redis这篇就够了
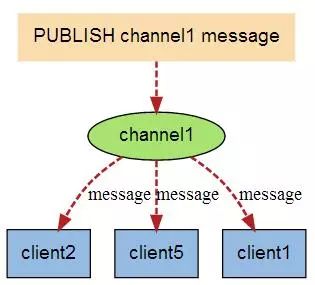
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
学Redis这篇就够了
实例
以下实例演示了发布订阅是如何工作的。在我们实例中我们创建了订阅频道名为 redisChat:
127.0.0.1:6379> SUBsCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat"
现在,我们先重新开启个 redis 客户端,然后在同一个频道 redisChat 发布两次消息,订阅者就能接收到消息。
127.0.0.1:6379> PUBLISH redisChat "send message" (integer) 1 127.0.0.1:6379> PUBLISH redisChat "hello world" (integer) 1 # 订阅者的客户端显示如下 1) "message" 2) "redisChat" 3) "send message" 1) "message" 2) "redisChat" 3) "hello world"
事务
redis 事务一次可以执行多条命令,服务器在执行命令期间,不会去执行其他客户端的命令请求。
事务中的多条命令被一次性发送给服务器,而不是一条一条地发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
批量操作在发送 EXEC 命令前被放入队列缓存。
在接收到 EXEC 命令后,进入事务执行。如果在事务中有命令执行失败,其他命令仍然会继续执行。也就是说 Redis 事务不保证原子性。
在事务执行过程中,其他客户端提交的命令请求不会插入到事务执行命令序列中。
一个事务从开始到执行会经历以下三个阶段:
开始事务。
命令入队。
执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:
redis 127.0.0.1:6379> MULTI OK redis 127.0.0.1:6379> SET book-name "Mastering C++ in 21 days" QUEUED redis 127.0.0.1:6379> GET book-name QUEUED redis 127.0.0.1:6379> SADD tag "C++" "Programming" "Mastering Series" QUEUED redis 127.0.0.1:6379> SMEMBERS tag QUEUED redis 127.0.0.1:6379> EXEC 1) OK 2) "Mastering C++ in 21 days" 3) (integer) 3 4) 1) "Mastering Series" 2) "C++" 3) "Programming"
单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
这是官网上的说明 From redis docs on transactions:
It's important to note that even when a command fails, all the other commands in the queue are processed – Redis will not stop the processing of commands.
比如:
redis 127.0.0.1:7000> multi OK redis 127.0.0.1:7000> set a aaa QUEUED redis 127.0.0.1:7000> set b bbb QUEUED redis 127.0.0.1:7000> set c ccc QUEUED redis 127.0.0.1:7000> exec 1) OK 2) OK 3) OK
如果在 set b bbb 处失败,set a 已成功不会回滚,set c 还会继续执行。
Redis 事务命令
下表列出了 redis 事务的相关命令:
序号命令及描述:
1. DISCARD 取消事务,放弃执行事务块内的所有命令。
2. EXEC 执行所有事务块内的命令。
3. MULTI 标记一个事务块的开始。
4. UNWATCH 取消 WATCH 命令对所有 key 的监视。
5. WATCH key [key …]监视一个 (或多个) key ,如果在事务执行之前这个 (或这些) key 被其他命令所改动,那么事务将被打断。
持久化
Redis 是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB 持久化
将某个时间点的所有数据都存放到硬盘上。
可以将快照复制到其他服务器从而创建具有相同数据的服务器副本。
如果系统发生故障,将会丢失最后一次创建快照之后的数据。
如果数据量大,保存快照的时间会很长。
AOF 持久化
将写命令添加到 AOF 文件(append only file)末尾。
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。
这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。
选项同步频率always每个写命令都同步eyerysec每秒同步一次no让操作系统来决定何时同步
always 选项会严重减低服务器的性能
everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器几乎没有任何影响。
no 选项并不能给服务器性能带来多大的提升,而且会增加系统崩溃时数据丢失的数量。
随着服务器写请求的增多,AOF 文件会越来越大。Redis提供了一项称作AOF重写的功能,能够消除AOF文件中的重复写入命令。
复制
Make one server a slave server of another server by using the slaveof host port command.
A slave server can only have one master server, and master-master replication is not supported.
Connection process
The master server creates a snapshot file, that is, an RDB file, sends it to the slave server, and uses the buffer record to execute during the sending write command.
After the snapshot file is sent, start sending write commands stored in the buffer from the server.
The slave server discards all old data, loads the snapshot file sent by the master server, and then the slave server starts accepting write commands from the master server.
Every time the master server executes a write command, it sends the same write command to the slave server.
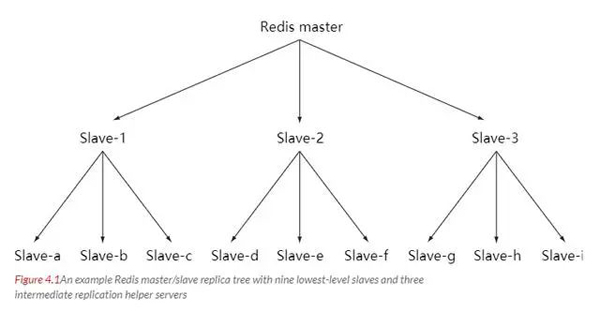
Master-slave chain
When the load continues to increase, if the master server cannot quickly update all slave servers, or reconnect and synchronize the slave servers Can cause system overload.
In order to solve this problem, an intermediary layer can be established to reduce the replication workload of the main server. The middle-tier server simultaneously acts as the slave server of the top-tier server and the master server of the bottom-tier server.
Sentinel
Sentinel can monitor the servers in the cluster and automatically Elect a new master server from the slave servers.
Fragmentation
Fragmentation is a method of dividing data into multiple parts. Data can be stored in multiple machines. This method is useful in solving certain problems. A linear level of performance improvement can be achieved when solving problems.
Suppose there are 4 Redis instances R0, R1, R2, R3, and there are many keys representing users user:1, user:2, …. There are different ways to select a specified key to store in In which instance.
The simplest is range sharding. For example, user IDs from 0 ~ 1000 are stored in instance R0, user IDs from 1001 ~ 2000 are stored in instance R1, and so on. However, this requires maintaining a mapping range table, which is expensive to maintain.
Another option is hash sharding. The instances that need to be stored are determined by running a CRC32 hash function on the key, converting it to a number, and then modulo the number of instances.
According to the location where sharding is performed, it can be divided into three sharding methods:
Client sharding: The client uses consistency Algorithms such as hashing determine which node it should be distributed to.
Proxy sharding: Send the client's request to the proxy, and the proxy forwards it to the correct node.
Server sharding: Redis Cluster.
The above is the detailed content of What are the comprehensive knowledge points of Redis?. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



