We often encounter slow queries in the project. When we encounter slow queries, we generally need to enable the slow query log, and analyze the slow query log to find the slow SQL. Then use explain to analyze
System variables
The system variables related to MySQL and slow query are as follows
Parameters
Meaning
slow_query_log
Whether to enable slow query log, ON means enabled, OFF means not enabled, the default is OFF
log_output
The log output location defaults to FILE, which means saving it as a file. If set to TABLE, the log will be recorded to the mysql.show_log table and supports multiple formats
slow_query_log_file
Specify the path and name of the slow query log file
##long_query_time
The execution time must exceed this value Record to the slow query log, the unit is seconds, the default is 10
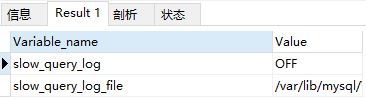
Execute the following statement to see whether the slow query log is enabled. ON means enabled, OFF means not enabled.
show variables like "%slow_query_log%"
Copy after login
You can see that mine is not enabled. You can use the following two methods. Method to enable slow query
Modify the configuration file
Modify the configuration file my.ini and add the following parameters in the [mysqld] paragraph
You need to restart MySQL. It takes effect, the command is service mysqld restart
Set global variables
I execute the following 2 sentences on the command line to open the slow query log, set the timeout to 0.001s, and record the log Go to the file and the mysql.slow_log table
set global slow_query_log = on;
set global log_output = 'FILE,TABLE';
set global long_query_time = 0.001;
Copy after login
If you want to make it permanent, get the configuration in the configuration file, otherwise these configurations will become invalid after the database is restarted
Analyze the slow query log
Because the mysql slow query log is equivalent to a running account and does not have the function of summary statistics, we need to use some tools to analyze it
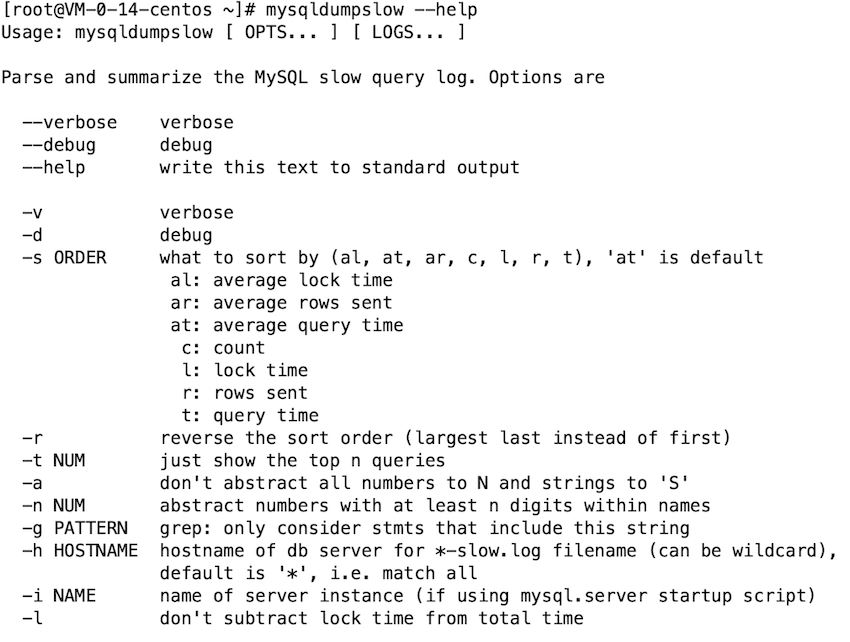
mysqldumpslow
mysql has a built-in mysqldumpslow tool Come help us analyze slow query logs.
Common Usage
# 取出使用最多的10条慢查询
mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log
# 取出查询时间最慢的3条慢查询
mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log
# 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log
Copy after login
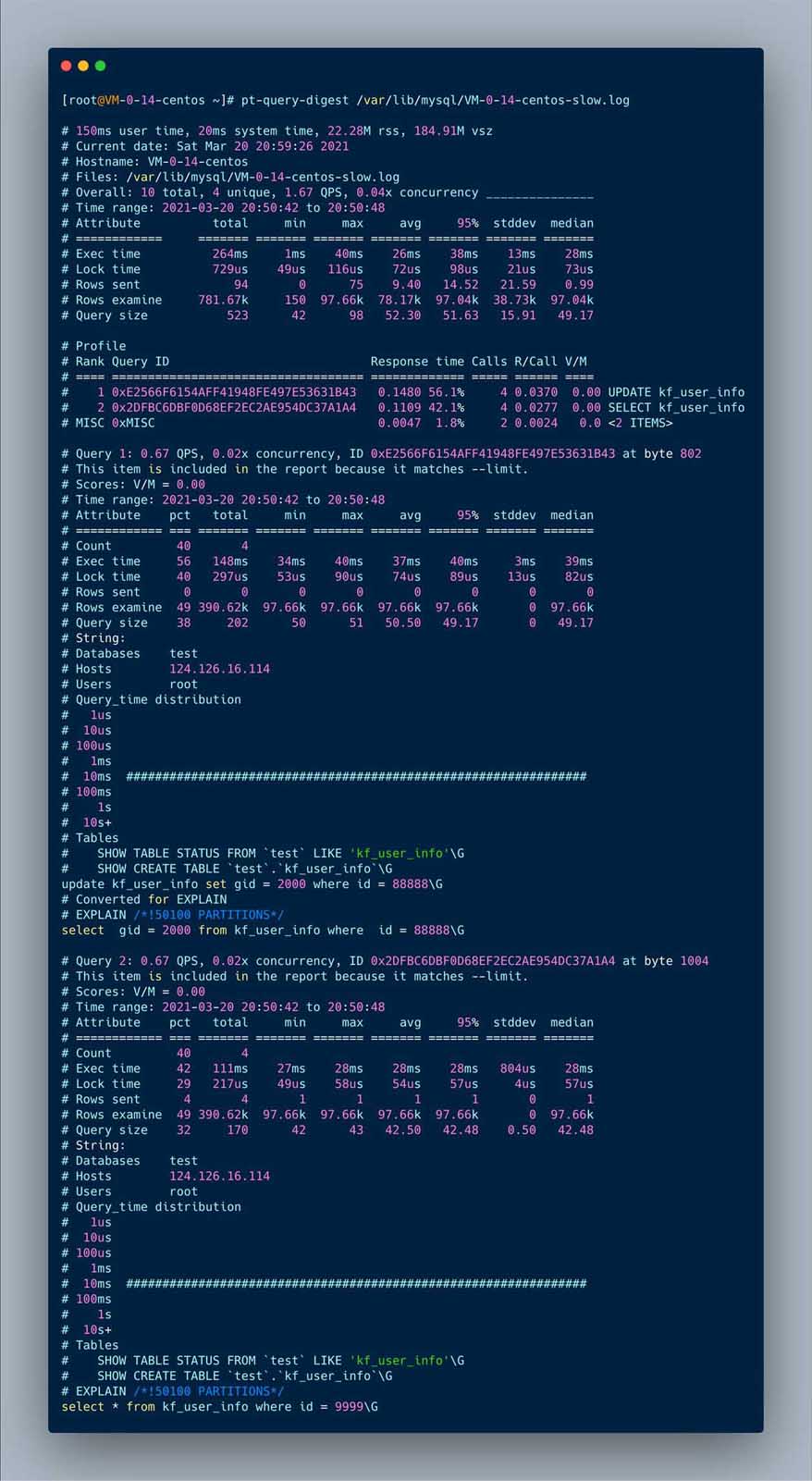
pt-query-digest
pt-query-digest is the tool I use most, its functions It is very powerful and can analyze binlog, general log, slowlog, and can also be analyzed through show processlist or MySQL protocol data captured through tcpdump. Just download and authorize it to run the pt-query-digest Perl script
--create-review-table When using the --review parameter to output the analysis results to the table, it will be automatically created if there is no table.
--create-history-table When using the --history parameter to output the analysis results to a table, it will be automatically created if there is no table.
--filter Matches and filters the input slow query according to the specified string and then analyzes it
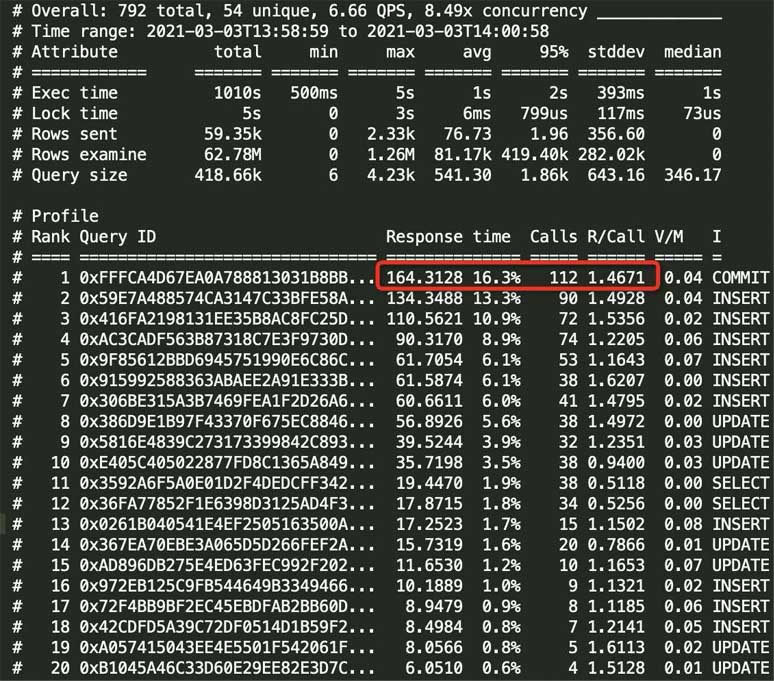
--limit limits the output results Percentage or quantity, the default value is 20, that is, the 20 slowest statements will be output. If it is 50%, it will be sorted from large to small by the total response time, and the output will be cut off when the total reaches 50%.
--host mysql server address
--user mysql username
-- password mysql user password
--history Save the analysis results to the table. The analysis results are more detailed. The next time you use --history, if the same statement exists and the query is If the time interval is different from that in the history table, it will be recorded in the data table. You can compare the historical changes of a certain type of query by querying the same CHECKSUM.
--review Save the analysis results to the table. This analysis only parameterizes the query conditions. One type of query is for one record, which is relatively simple. If the same statement analysis occurs, it will not be recorded in the data table the next time --review is used.
--output analysis result output type, the value can be report (standard analysis report), slowlog (Mysql slow log), json, json-anon, generally use report for easier reading .
--since the time from which to start analysis, the value is a string, which can be a specified time point in the format of "yyyy-mm-dd [hh:mm:ss]" , or it can be a simple time value: s (seconds), h (hours), m (minutes), d (days), for example, 12h means that statistics started 12 hours ago.
--until deadline, combined with -since can analyze slow queries within a period of time.
Commonly used DSN
A Specify the character set D Specify the connected database P Connect to the database port S Connect Socket file h Host name to connect to the database p Password to connect to the database t Which table should the data be stored in when using --review or --history u User name to connect to the database
DSN is configured in the form of key=value; multiple DSNs are used, separated
Writing stored procedures to create data in batches
There is no performance test in actual work. We often need to transform large batches of data, and manual insertion is impossible. At this time, we have to use stored procedures
CREATE TABLE `kf_user_info` (
`id` int(11) NOT NULL COMMENT '用户id',
`gid` int(11) NOT NULL COMMENT '客服组id',
`name` varchar(25) NOT NULL COMMENT '客服名字'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='客户信息表';
Copy after login
How to define a stored procedure?
CREATE PROCEDURE 存储过程名称 ([参数列表])
BEGIN
需要执行的语句
END
Copy after login
For example, insert 100000 pieces of data with IDs 1-100000
Use Navicat to execute
-- 删除之前定义的
DROP PROCEDURE IF EXISTS create_kf;
-- 开始定义
CREATE PROCEDURE create_kf(IN loop_times INT)
BEGIN
DECLARE var INT;
SET var = 1;
WHILE var < loop_times DO
INSERT INTO kf_user_info (`id`,`gid`,`name`)
VALUES (var, 1000, var);
SET var = var + 1;
END WHILE;
END;
-- 调用
call create_kf(100000);
Copy after login
Three parameter types of the stored procedure
Parameter type
Whether to return
Function
##IN
No
Pass parameters into the stored procedure. The value of the parameter is modified during the stored procedure and cannot be returned.
OUT
is
to change the stored procedure The calculated result is placed in this parameter, and the caller can get the return value
INOUT
is the combination of
IN and OUT, which is used for The incoming parameters of the stored procedure can also be put into the calculation structure, and the caller can get the return value
DELIMITER //
CREATE PROCEDURE create_kf_kfGroup(IN loop_times INT)
BEGIN
DECLARE var INT;
SET var = 1;
WHILE var <= loop_times DO
INSERT INTO kf_user_info (`id`,`gid`,`name`)
VALUES (var, 1000, var);
SET var = var + 1;
END WHILE;
END //
DELIMITER ;
Copy after login
查询已经定义的存储过程
show procedure status;
Copy after login
开始执行慢sql
select * from kf_user_info where id = 9999;
select * from kf_user_info where id = 99999;
update kf_user_info set gid = 2000 where id = 8888;
update kf_user_info set gid = 2000 where id = 88888;
Copy after login
可以执行如下sql查看慢sql的相关信息。
SELECT * FROM mysql.slow_log order by start_time desc;
The above is the detailed content of How to quickly locate slow SQL in MySQL. For more information, please follow other related articles on the PHP Chinese website!
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



