
For back-end developers, a single SQl can be used to implement the list query interface. If the query conditions are complex and the table database design is unreasonable, the query will be difficult. This article will share with you how to use Redis to implement search. interface.
Let’s start with an example. This is the search condition of a shopping website. If you were asked to implement such a search interface, how would you implement it?
Of course you said with the help of search engines, like Elasticsearch and the like, you can definitely do it. But what I want to say here is, what if you want to implement it yourself?

As you can see from the picture above, search is divided into 6 categories in total, and each category Divided into various subcategories.
In this case, the filtering process takes the intersection of the major categories of conditions and considers single selection, multi-selection and customization in each subcategory to output a result set that meets the conditions.
Okay, now that the requirements are clear, let’s start implementing them.
Implementation 1
The first to appear is student A. He is an "expert" in writing SQL. Little A said confidently: "Isn't it just a query interface? There are many conditions, but with my rich SQL experience, this is not a problem for me."
So I wrote The following code came out (taking MySQL as an example here):
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
The code was run in the test environment, and the results seemed to match, so I prepared to pre-release it. With this pre-launch, problems began to emerge.
The pre-release is to make the online environment as realistic as possible, so the amount of data is naturally much larger than that of the test. So for such a complex SQL, its execution efficiency can be imagined. The test classmate decisively typed back the code of Little A.
Implementation 2
Summarizing the lessons learned from the failure of Little A, Little B began to optimize SQL. First, it passed the explain keyword for SQL performance analysis. Indexes are added wherever indexes are added.
Split a complex SQL into multiple SQLs at the same time, and the calculation results are calculated in the program memory.
The pseudo code is as follows:
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);This solution is obviously much better than the first one in terms of performance, but during function acceptance, the product manager still feels that the query speed is not fast enough.
Little B himself also knows that each query will query the database multiple times, and for some historical reasons, single-table query cannot be performed under some conditions, so the waiting time for queries is unavoidable.
Implementation 3
Little C saw room for optimization from the above solution. He found that Little B had no problem with his thinking. He split the complex conditions, calculated the result sets of each sub-dimension, and finally summarized and merged all the sub-result sets to get the final desired result.
So he suddenly thought about whether he could cache the result sets of each sub-dimension in advance. This would allow him to directly fetch the desired subset when querying, without having to check the database for calculation every time.
Here Little C uses Redis to store cache data. The main reason for using it is that it provides a variety of data structures, and it is very easy to perform intersection and union operations on sets in Redis.
The specific plan is as shown in the figure:
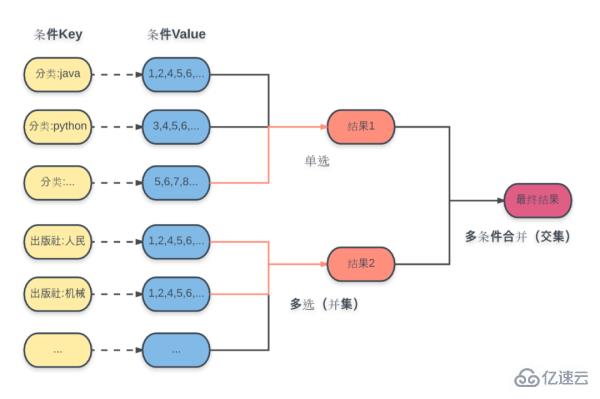
For each condition here, the calculated result set ID is stored in the corresponding Key in advance and selected. The data structure is a set (Set).
Query operations include:
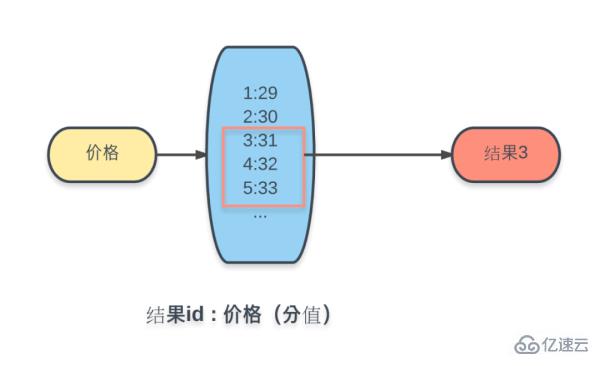
Extension
①Paging
You may have discovered a serious functional flaw here. How can list queries be without paging? . Yes, let's take a look right away at how Redis implements paging.Paging mainly involves sorting. For the sake of simplicity, let’s take the creation time as an example. As shown in the figure:
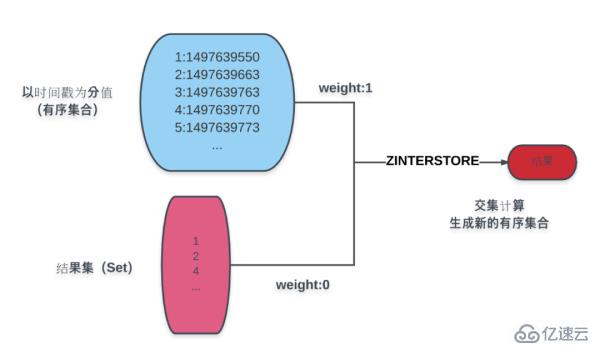
The blue part in the figure is an ordered collection of products based on creation time. The result set below the blue is the conditional calculation. As a result, through the ZINTERSTORE command, the result set weight is assigned to 0, the product time result is 1, and the result set obtained by taking the intersection is assigned to a new ordered set of creation time scores.
The operation on the new result set can obtain the various data required for paging:
The total number of pages is: ZCOUNT command.
Current page content: ZRANGE command.
If arranged in reverse order: ZREVRANGE command.
②Data update
Regarding the issue of index data update, there are two ways to proceed. One is to trigger the update operation immediately through the modification of product data, and the other is to perform batch updates through scheduled scripts.
What should be noted here is that regarding the update of index content, if the Key is violently deleted, the Key must be reset.
Because the two operations in Redis will not be performed atomically, there may be gaps in the middle. It is recommended to only remove the invalid elements in the collection and add new elements.
③Performance Optimization
Redis is a memory-level operation, so a single query will be very fast. However, if multiple Redis operations are performed in our implementation, the multiple Redis connection times may be unnecessary time consumption.
By using the MULTI command, start a transaction, put multiple Redis operations into one transaction, and finally perform atomic execution through EXEC.
Note: The so-called transaction here only executes multiple operations in one connection. If a failure occurs during execution, it will not be rolled back.
Summary
This is just a simple demo using Redis to optimize query search. Compared with existing open source search engines, it is more lightweight and requires less learning. Correspondingly lower.
Secondly, some of its ideas are similar to open source search engines. If word analysis is added, functions similar to full-text retrieval can also be achieved.
The above is the detailed content of How to use Redis to implement search interface. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server
 How redis solves data consistency
How redis solves data consistency
 How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency?
 What data does redis cache generally store?
What data does redis cache generally store?
 What are the 8 data types of redis
What are the 8 data types of redis









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



