

Heart of Machine Column
Heart of Machine Editorial Department
The success rate of AI fraud is very high. A few days ago, "4.3 million defrauded in 10 minutes" was a hot search topic. Building on the hottest large language model, researchers have recently explored a recognition method.
With the continuous progress of large generative models, the corpus they generate is gradually approaching that of humans. Although large models are liberating the hands of countless clerks, their powerful ability to fake fake ones has also been used by some criminals, causing a series of social problems:



Researchers from Peking University and Huawei have proposed a reliable text detector for identifying various AI-generated corpora. According to the different characteristics of long and short texts, a multi-scale AI-generated text detector training method based on PU learning is proposed. By improving the detector training process, considerable improvements in detection capabilities on long and short ChatGPT corpus can be achieved under the same conditions, solving the pain point of low accuracy of short text recognition by current detectors.

Paper address:
https://arxiv.org/abs/2305.18149
Code address (MindSpore):
https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
Code address (PyTorch):
https://github.com/YuchuanTian/AIGC_text_detector
Introduction
As the generation effects of large language models become more and more realistic, various industries urgently need a reliable AI-generated text detector. However, different industries have different requirements for detection corpus. For example, in academia, it is generally necessary to detect large and complete academic texts; on social platforms, relatively short and fragmented fake news needs to be detected. However, existing detectors often cannot meet various needs. For example, some mainstream AI text detectors generally have poor prediction capabilities for shorter corpus.
Regarding the different detection effects of corpus of different lengths, the author observed that there may be some "uncertainty" in the attribution of shorter AI-generated texts; or to put it more bluntly, because some AI-generated short sentences are often also It is used by humans, so it is difficult to determine whether the short text generated by AI comes from humans or AI. Here are several examples of humans and AI answering the same question:

It can be seen from these examples that it is difficult to identify short answers generated by AI: the difference between this type of corpus and humans is too small, and it is difficult to strictly judge its true attributes. Therefore, it is inappropriate to simply annotate short texts as human/AI and follow the traditional binary classification problem for text detection.
In response to this problem, this study transforms the human/AI binary classification detection part into a partial PU (Positive-Unlabeled) learning problem, that is, in shorter sentences, the human language is positive (Positive), and the machine The language is Unlabeled, which improves the training loss function. This improvement significantly improves the detector's classification performance on various corpora.
Algorithm details
Under the traditional PU learning setting, a two-classification model can only learn based on positive training samples and unlabeled training samples. A commonly used PU learning method is to estimate the binary classification loss corresponding to negative samples by formulating PU loss:
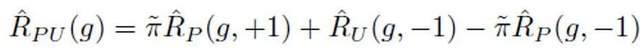
Among them, represents the binary classification loss calculated by positive samples and positive labels; represents the binary classification loss calculated by assuming all unlabeled samples to be negative labels; represents the binary classification loss calculated by assuming positive samples as negative labels; represents The prior positive sample probability is the estimated proportion of positive samples in all PU samples. In traditional PU learning, the prior is usually set to a fixed hyperparameter. However, in the text detection scenario, the detector needs to process various texts of different lengths; and for texts of different lengths, the estimated proportion of positive samples among all PU samples of the same length as the sample is also different. . Therefore, this study improves PU Loss and proposes a length-sensitive multi-scale PU (MPU) loss function.
Specifically, this study proposes an abstract recurrent model to model shorter text detection. When traditional NLP models process sequences, they usually have a Markov chain structure, such as RNN, LSTM, etc. The process of this type of cyclic model can usually be understood as a gradually iterative process, that is, the prediction of each token output is obtained by transforming and merging the prediction results of the previous token and the previous sequence with the prediction results of this token. That is the following process:
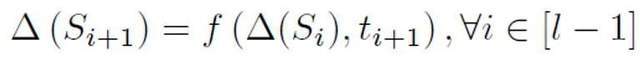
In order to estimate the prior probability based on this abstract model, it is necessary to assume that the output of the model is the confidence that a certain sentence is positive, that is, the probability of judging it to be a sample spoken by a person. It is assumed that the contribution size of each token is the inverse proportion of the length of the sentence token, it is positive, that is, unlabeled, and the probability of being unlabeled is much greater than the probability of being positive. Because as the vocabulary of large models gradually approaches that of humans, most words will appear in both AI and human corpora. Based on this simplified model and the set positive token probability, the final prior estimate is obtained by finding the total expectation of the model output confidence under different input conditions.
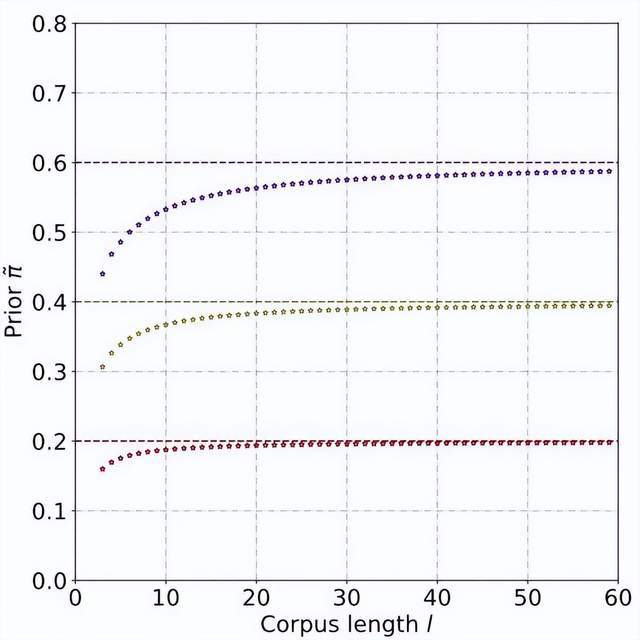
Through theoretical derivation and experiments, it is estimated that the prior probability increases as the length of the text increases, and eventually stabilizes. This phenomenon is also expected, because as the text becomes longer, the detector can capture more information, and the "source uncertainty" of the text gradually weakens:
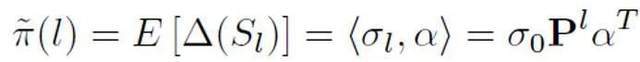
After that, for each positive sample, the PU loss is calculated based on the unique prior obtained from its sample length. Finally, since shorter texts only have some "uncertainty" (that is, shorter texts will also contain text features of some people or AI), the binary loss and MPU loss can be weighted and added as the final optimization goal:
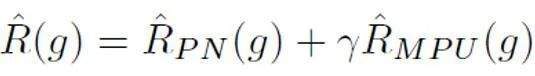
In addition, it should be noted that MPU loss adapts to training corpus of various lengths. If the existing training data is obviously homogeneous and most of the corpus consists of long and lengthy texts, the MPU method cannot fully exert its effectiveness. In order to make the length of the training corpus more diverse, this study also introduces a multi-scaling module at the sentence level. This module randomly covers some sentences in the training corpus and reorganizes the remaining sentences while retaining the original order. After multi-scale operation of the training corpus, the training text has been greatly enriched in length, thus making full use of PU learning for AI text detector training.
Experimental results

As shown in the table above, the author first tested the effect of MPU loss on the shorter AI-generated corpus data set Tweep-Fake. The corpus in this data set is all relatively short segments on Twitter. The author also replaces the traditional two-category loss with an optimization goal containing MPU loss based on traditional language model fine-tuning. The improved language model detector is more effective and surpasses other baseline algorithms.
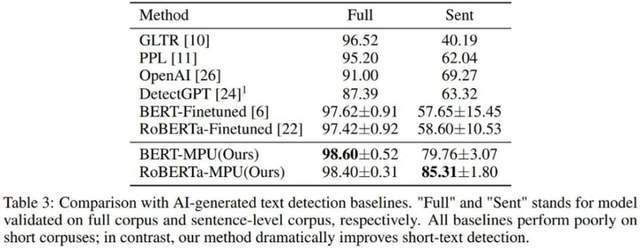
The author also tested the text generated by chatGPT. The language model detector obtained through traditional fine-tuning performed poorly on short sentences; the detector trained under the same conditions through MPU method performed well on short sentences, and At the same time, it can achieve considerable performance improvement on the complete corpus, with the F1-score increasing by 1%, surpassing SOTA algorithms such as OpenAI and DetectGPT.
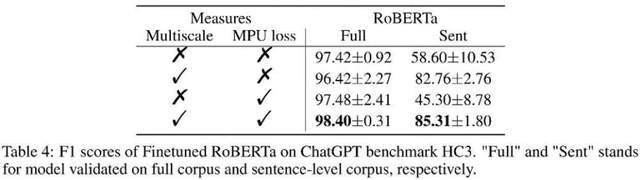
As shown in the table above, the author observed the effect gain brought by each part in the ablation experiment. MPU loss enhances the classification effect of long and short materials.

The author also compared traditional PU and Multiscale PU (MPU). It can be seen from the above table that the MPU effect is better and can better adapt to the task of AI multi-scale text detection.
Summarize
The author solved the problem of short sentence recognition by text detectors by proposing a solution based on multi-scale PU learning. With the proliferation of AIGC generation models in the future, the detection of this type of content will become increasingly important. This research has taken a solid step forward in the issue of AI text detection. It is hoped that there will be more similar research in the future to better control AIGC content and prevent the abuse of AI-generated content.
The above is the detailed content of Identifying ChatGPT fraud, the effect surpasses OpenAI: Peking University and Huawei's AI-generated detectors are here. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



