

Index is a data structure that helps MySQL perform efficient queries. Like the table of contents of a book, it can speed up the query
The index can have B-Tree index and Hash index. The index is implemented in the storage engine
InnoDB/MyISAM only supports B-Tree index
Memory/Heap supports B-Tree index and Hash index
B-Tree
B-Tree is a data structure that is very suitable for disk operations. It is a multi-way balanced search tree. Its height is generally 2-4, and its non-leaf nodes and leaf nodes will store data. All its leaf nodes are on the same layer. The picture below is a B-Tree
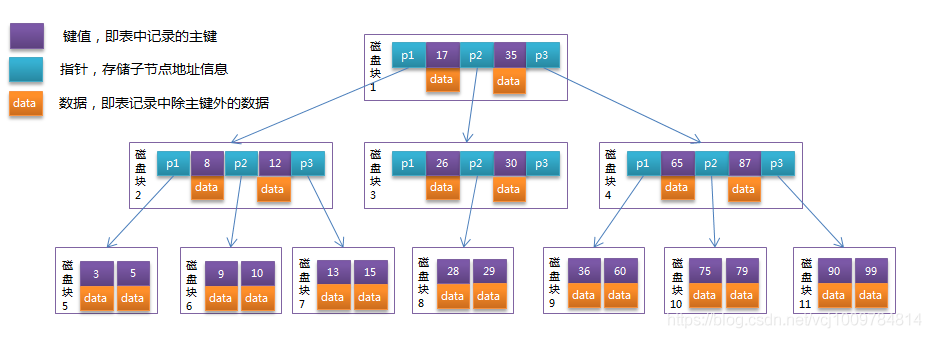
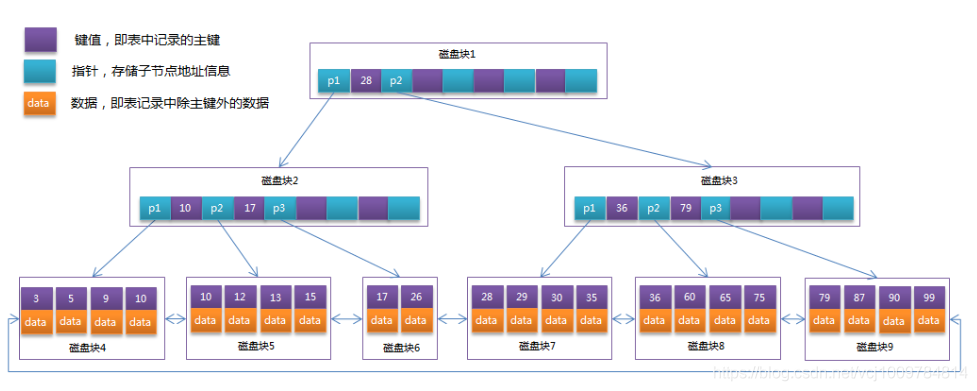
MyISAM index and data are stored separately. In the primary key index of MyISAM, the record address is stored in the leaf node of the B tree, so MyISAM needs to go through 2 IOs through the index query
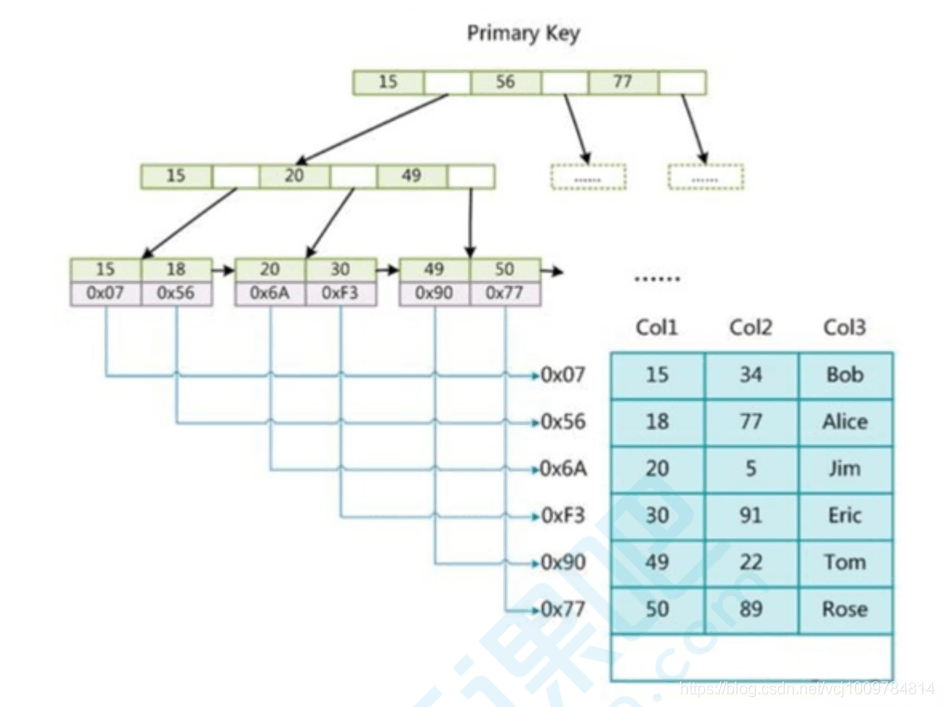
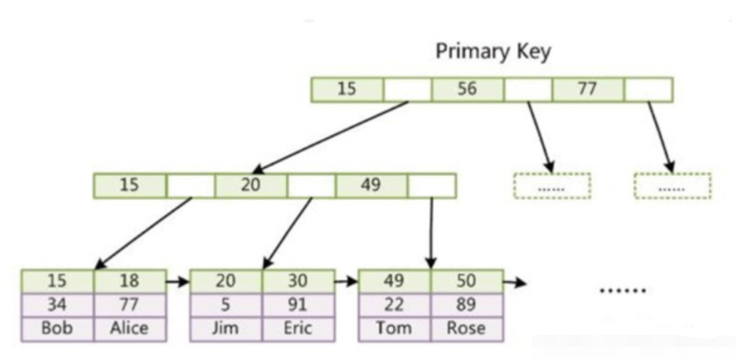
InnoDB Data and indexes are stored together, also called clustered indexes. Data is indexed by the primary key and stored on the leaf nodes of the primary key index B-tree.
InnoDB primary key index, the data is already included in the leaf nodes, that is, the index and data are stored together, which is a clustered index.
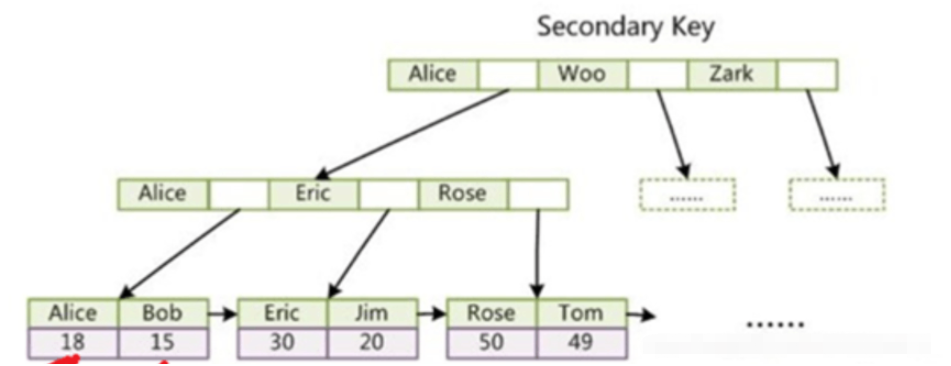
Question:
Why doesn’t InnoDB use overly long fields as primary keys? A primary key that is too long will make the auxiliary index take up a lot of space
Why is it recommended that InnoDB use auto-incrementing primary keys? If you use an auto-incrementing primary key, each time a new record is inserted, the new record will be sequentially added to the subsequent position of the current index node. When one page is full, a new page will be opened, so that The index structure is very compact, and there is no need to move existing data every time it is inserted, which is very efficient. If you do not use an auto-incrementing primary key, each time you insert a new record, you have to select an insertion position, and the data may need to be moved, which makes the efficiency not high and the index structure not compact
Why use B-tree instead of B-tree
The index will occupy additional storage space
The index will reduce the efficiency of updating table data. When adding, deleting, or modifying operations, you must not only save the data, but also update the corresponding index
Single column index
Primary key index
Unique index
Normal index
Combined index
to create an index
CREATE INDEX index_name ON table_name(col_name); -- 或者 ALTER TABLE table_name ADD INDEX index_name(col_name)
Delete index
DROP INDEX index_name ON table_name;
Scenarios that require indexing
Frequent The columns used as query conditions need to be indexed
In multi-table association, the associated fields need to be indexed
The sorting fields in the query need to be indexed Building an index
Scenarios where indexing is not suitable

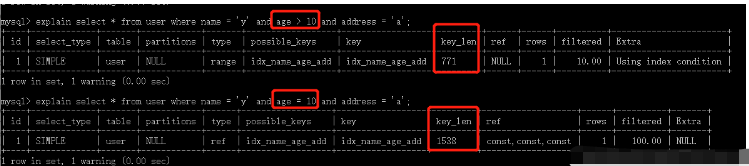
explain select * from user where name = 'am';

possible_keysPossibly used index
keyActually used index
key_lenThe length of the index used for query
refIf it is an equivalent query, it will be const
rowsEstimated number of rows to be scanned (not an exact value)
extra
indicates that the results returned by the storage engine also need to be filtered at the SQL Layer layer
indicates that there is no need to query back to the table. Generally, it will be when using a covering index. this value. Covering index means that the columns in the select are all index columns. The query that does not need to be returned to the table means that you can get the value of the index column directly by going through the auxiliary index, and there is no need to go to the primary key index to fetch records
MySQL 5.6.x and later supports the ICP feature (Index Condition Pushdown), which can push the check conditions to the storage engine layer. Records that do not meet the conditions will not be read directly, instead of reading them out first and then reading them as before. SQL Layer layer filtering, which reduces the number of rows scanned by the storage engine layer




##Note that when like, the wildcard character % cannot be placed at the beginning, otherwise it will cause a full table scan
 ##index :
##index :

 #all that does not completely match the index, but does not need to be queried back to the table : Scan the entire table, and then filter the records that meet the requirements in the SQL Layer
#all that does not completely match the index, but does not need to be queried back to the table : Scan the entire table, and then filter the records that meet the requirements in the SQL Layer
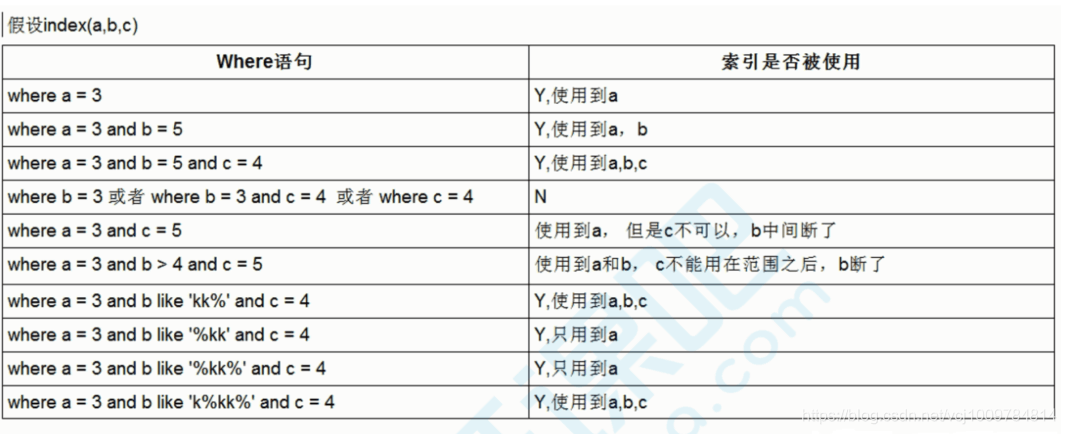
全值匹配
在索引列上使用等值查询
explain select * from user where name = 'y' and age = 15;

2. 最左前缀
组合索引中,查询条件要从组合索引的最左列开始,如上述example中组合索引idx_name_age_add,是建立在三个列name,age,address的,若跳过name,直接用age查询,则会变为全表扫描
explain select * from user where age = 15;

3. 不要在索引列上做计算
4. 范围条件右侧的索引列会失效
看到第一个SQL语句,没有用上addresss索引
5. 尽量使用覆盖索引
explain select name,age from user where name = 'y' and age = 1;
可以避免回表查询
6. 索引字段不要使用不等(!= 或 ),不要判断null(is null/ is not null)
会导致索引失效,转为全表扫描


7. 索引字段上使用like时,不要以%开头

8. 索引字段如果是字符串,记得加单引号
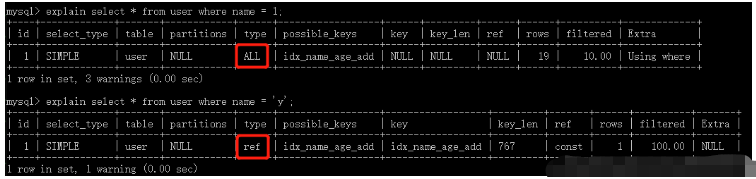
9. 索引字段不要用or

The above is the detailed content of What are the knowledge points about MySQL indexing and optimization?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



