
 Technology peripherals
AI
Crushing LLaMA, 'Falcon' is completely open source! 40 billion parameters, trillions of token training, dominating Hugging Face
Technology peripherals
AI
Crushing LLaMA, 'Falcon' is completely open source! 40 billion parameters, trillions of token training, dominating Hugging Face
Crushing LLaMA, 'Falcon' is completely open source! 40 billion parameters, trillions of token training, dominating Hugging Face

In the era of large models, what is most important?
The answer LeCun once gave is: open source.
When the code for Meta’s LLaMA was leaked on GitHub, developers around the world had access to it. An LLM that reaches GPT level.
Next, various LLMs give various angles to the open source of AI models.
LLaMA paved the way and set the stage for models such as Stanford's Alpac and Vicuna, making them leaders in open source.
At this moment, the Falcon "Falcon" broke out of the siege again.
Falcon Falcon
"Falcon" was developed by the Technology Innovation Institute (TII) in Abu Dhabi, United Arab Emirates. In terms of performance, Falcon performs better than LLaMA good.
Currently, "Falcon" has three versions-1B, 7B and 40B.
TII stated that Falcon is the most powerful open source language model to date. Its largest version, Falcon 40B, has 40 billion parameters, which is still a bit smaller in scale than LLaMA, which has 65 billion parameters.
Although the scale is small, the performance is high.
Faisal Al Bannai, Secretary General of the Advanced Technology Research Council (ATRC), believes that the release of “Falcon” will break the way to obtain LLM and allow researchers and entrepreneurs to propose the best solutions. Most innovative use cases.
The two versions of FalconLM, Falcon 40B Instruct and Falcon 40B, rank in the top two on the Hugging Face OpenLLM rankings, while Meta's LLaMA is ranked third.
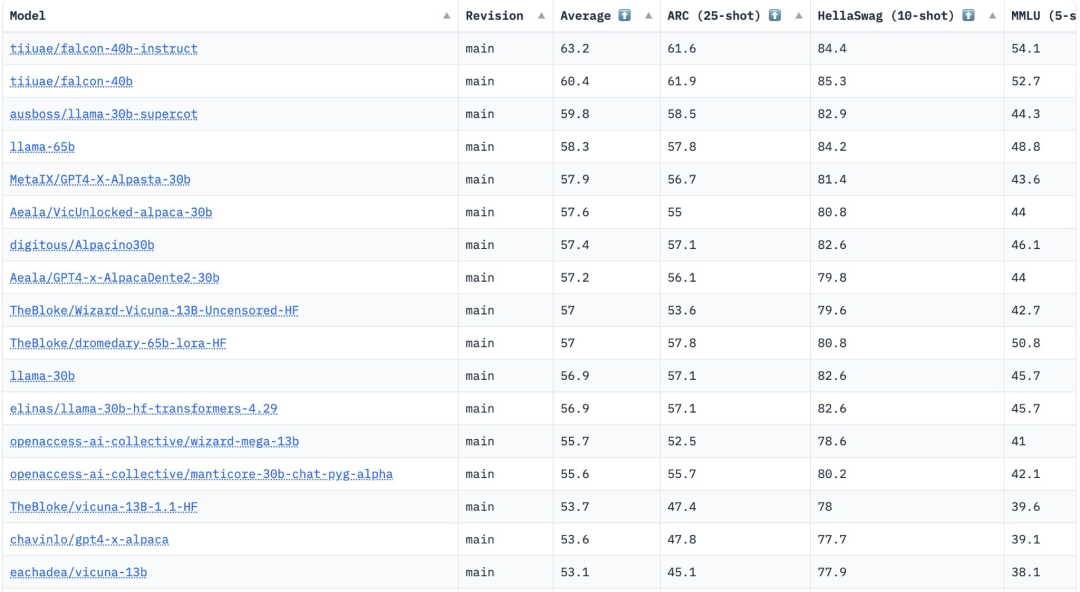
It is worth mentioning that Hugging Face passed four current benchmarks for comparing manifolds-AI2 Reasoning Challenge , HellaSwag, MMLU and TruthfulQA are used to evaluate these models.
Although the "Falcon" paper has not yet been publicly released, Falcon 40B has been extensively trained on a carefully screened 1 trillion token network data set.
Researchers revealed that “Falcon” attaches great importance to the importance of achieving high performance on large-scale data during the training process.
What we all know is that LLM is very sensitive to the quality of training data, which is why researchers spend a lot of effort building one that can perform efficient processing on tens of thousands of CPU cores data pipeline.
The purpose is to extract high-quality content from the Internet based on filtering and deduplication.
Currently, TII has released a refined network data set, which is a carefully filtered and deduplicated data set. Practice has proved that it is very effective.
The model trained using only this data set can be on par with other LLMs, or even surpass them in performance. This demonstrates the excellent quality and influence of "Falcon".

In addition, the Falcon model also has multi-language capabilities.
It understands English, German, Spanish and French, and some small European languages such as Dutch, Italian, Romanian, Portuguese, Czech, Polish and Swedish I also know a lot about it.
Falcon 40B is the second truly open source model after the release of the H2O.ai model. However, since H2O.ai has not been benchmarked against other models in this ranking, these two models have not yet entered the ring.
Looking back at LLaMA, although its code is available on GitHub, its weights have never been open source.
This means that the commercial use of this model is subject to certain restrictions.
Moreover, all versions of LLaMA depend on the original LLaMA license, which makes LLaMA unsuitable for small-scale commercial applications.
At this point, “Falcon” comes out on top again.
The only free commercial model!
Falcon is currently the only open source model that can be used commercially for free.
In the early days, TII required that if Falcon is used for commercial purposes and generates more than $1 million in attributable income, a 10% "use tax" will be charged.
But it didn’t take long for the wealthy Middle Eastern tycoons to lift this restriction.
At least so far, all commercial use and fine-tuning of Falcon will be free of charge.
The wealthy people said that they do not need to make money through this model for the time being.
Moreover, TII is also soliciting commercialization plans from around the world.
For potential scientific research and commercialization solutions, they will also provide more "training computing power support" or provide further commercialization opportunities.

##Project submission email: Submissions.falconllm@tii.ae
This is simply saying: as long as the project is good, the model is free! Enough computing power! If you don’t have enough money, we can still collect it for you!
For start-ups, this is simply a "one-stop solution for AI large model entrepreneurship" from the Middle East tycoon.
High-Quality Training DataAccording to the development team, an important aspect of FalconLM’s competitive advantage is the selection of training data.
The research team developed a process to extract high-quality data from public crawled datasets and remove duplicate data.
After thorough cleaning of redundant and duplicate content, 5 trillion tokens were retained—enough to train powerful language models.
The 40B Falcon LM uses 1 trillion tokens for training, and the 7B version of the model uses 1.5 trillion tokens for training.
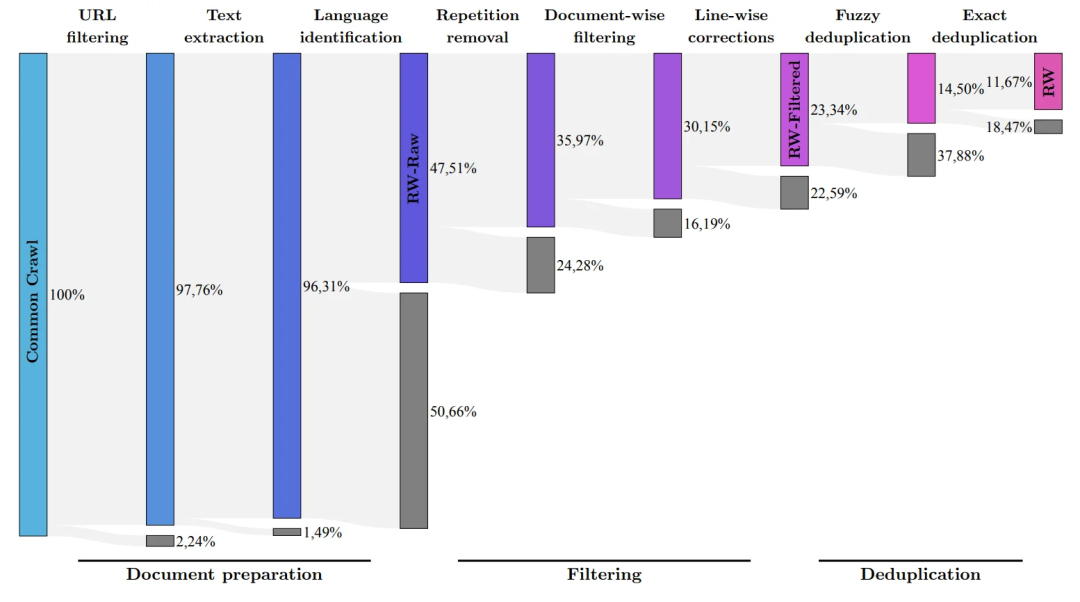
(The research team aims to filter out only the highest quality raw data from the Common Crawl using the RefinedWeb dataset)
More controllable training costsTII said that compared with GPT-3, Falcon achieved the A significant performance improvement.
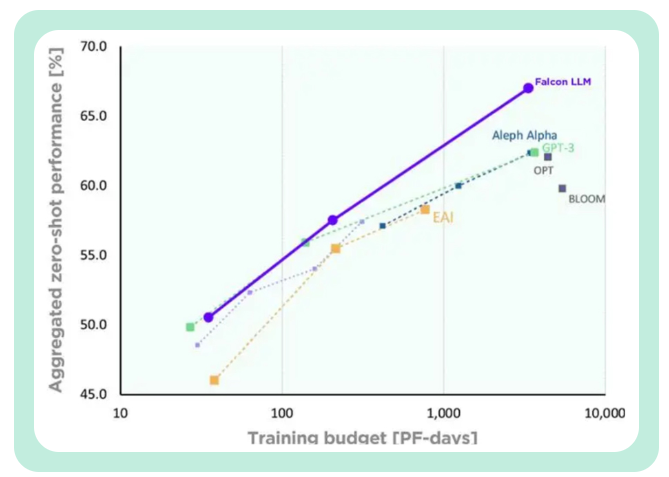
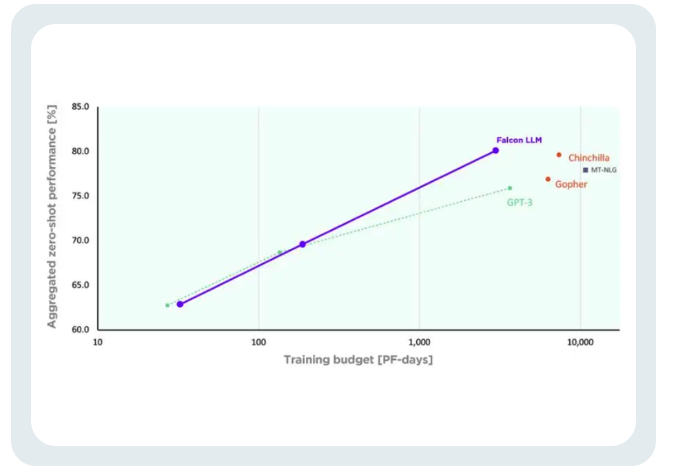
Falcon’s training cost is only equivalent to 40% of Chinchilla’s and 80% of PaLM-62B’s. Successfully achieved efficient utilization of computing resources.
The above is the detailed content of Crushing LLaMA, 'Falcon' is completely open source! 40 billion parameters, trillions of token training, dominating Hugging Face. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files using Visual Studio Code? Create a header file and declare symbols in the header file using the .h or .hpp suffix name (such as classes, functions, variables) Compile the program using the #include directive to include the header file in the source file. The header file will be included and the declared symbols are available.
 Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Writing C in VS Code is not only feasible, but also efficient and elegant. The key is to install the excellent C/C extension, which provides functions such as code completion, syntax highlighting, and debugging. VS Code's debugging capabilities help you quickly locate bugs, while printf output is an old-fashioned but effective debugging method. In addition, when dynamic memory allocation, the return value should be checked and memory freed to prevent memory leaks, and debugging these issues is convenient in VS Code. Although VS Code cannot directly help with performance optimization, it provides a good development environment for easy analysis of code performance. Good programming habits, readability and maintainability are also crucial. Anyway, VS Code is
 Docker uses yaml
Apr 15, 2025 am 07:21 AM
Docker uses yaml
Apr 15, 2025 am 07:21 AM
YAML is used to configure containers, images, and services for Docker. To configure: For containers, specify the name, image, port, and environment variables in docker-compose.yml. For images, basic images, build commands, and default commands are provided in Dockerfile. For services, set the name, mirror, port, volume, and environment variables in docker-compose.service.yml.
 Can vscode run kotlin
Apr 15, 2025 pm 06:57 PM
Can vscode run kotlin
Apr 15, 2025 pm 06:57 PM
Running Kotlin in VS Code requires the following environment configuration: Java Development Kit (JDK) and Kotlin compiler Kotlin-related plugins (such as Kotlin Language and Kotlin Extension for VS Code) create Kotlin files and run code for testing to ensure successful environment configuration
 Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Depending on the specific needs and project size, choose the most suitable IDE: large projects (especially C#, C) and complex debugging: Visual Studio, which provides powerful debugging capabilities and perfect support for large projects. Small projects, rapid prototyping, low configuration machines: VS Code, lightweight, fast startup speed, low resource utilization, and extremely high scalability. Ultimately, by trying and experiencing VS Code and Visual Studio, you can find the best solution for you. You can even consider using both for the best results.
 How to build vscode c
Apr 15, 2025 pm 05:03 PM
How to build vscode c
Apr 15, 2025 pm 05:03 PM
VS Code provides a powerful C development environment that improves development efficiency. When configuring, you need to pay attention to path issues, memory leaks and dependency management. Advantages include extended ecosystems, excellent code editing capabilities, and integrated debuggers, while disadvantages are extended dependencies and resource consumption.
 Can vscode be used for java
Apr 15, 2025 pm 08:33 PM
Can vscode be used for java
Apr 15, 2025 pm 08:33 PM
VS Code is absolutely competent for Java development, and its powerful expansion ecosystem provides comprehensive Java development capabilities, including code completion, debugging, version control and building tool integration. In addition, VS Code's lightweight, flexibility and cross-platformity make it better than bloated IDEs. After installing JDK and configuring JAVA_HOME, you can experience VS Code's Java development capabilities by installing "Java Extension Pack" and other extensions, including intelligent code completion, powerful debugging functions, construction tool support, etc. Despite possible compatibility issues or complex project configuration challenges, these issues can be addressed by reading extended documents or searching for solutions online, making the most of VS Code’s
 What does sublime renewal balm mean
Apr 16, 2025 am 08:00 AM
What does sublime renewal balm mean
Apr 16, 2025 am 08:00 AM
Sublime Text is a powerful customizable text editor with advantages and disadvantages. 1. Its powerful scalability allows users to customize editors through plug-ins, such as adding syntax highlighting and Git support; 2. Multiple selection and simultaneous editing functions improve efficiency, such as batch renaming variables; 3. The "Goto Anything" function can quickly jump to a specified line number, file or symbol; but it lacks built-in debugging functions and needs to be implemented by plug-ins, and plug-in management requires caution. Ultimately, the effectiveness of Sublime Text depends on the user's ability to effectively configure and manage it.
