


Xinxixi (Public account: aichip001)
Author | ZeR0
Editor | Mo Ying
One way to rewrite it is: The AI large model competition is setting off an unprecedented craze. According to the core report on May 30, the rise of ChatGPT is the key driving force of this competition. In this competition, speed is the key to gaining first-mover advantage. From model training to implementation, there is an urgent need for higher-performance AI chips.
In March this year, Aixin Yuanzhi, an AI visual perception chip R&D and basic computing platform company, launched the third-generation SoC chip AX650N with high computing power and high energy efficiency. Liu Jianwei, co-founder and vice president of Aixin Yuanzhi, said in a recent interview with Xinxi and other media that the AX650N chip has obvious advantages when running Transformer, and Transformer is a structure commonly used in current large models.
Transformer was initially used to handle tasks in the field of natural language processing, and gradually expanded into the field of computer vision, showing the potential to replace the traditional mainstream computer vision algorithm CNN in more and more visual tasks. How to efficiently deploy Transformer on the device side and edge side has become a core consideration for more and more users who have large model deployment requirements when choosing a platform.
Compared with using GPU to deploy Transformer large models in the cloud, Aixin Yuanzhi believes that the biggest challenge in deploying Transformer on the edge side and terminal side comes from power consumption, which makes Aixin Yuanzhi have both high performance and low power consumption. Mixed-precision NPU has become the preferred platform for deploying Transformers on both the end and edge sides.
Data shows that when the mainstream visual model Swin Transformer (SwinT) is run on the Aixin Yuanzhi AX650N platform, the performance is as high as 361FPS, the accuracy is as high as 80.45%, and the power consumption is as low as 199FPS/W, which is very useful in landing deployment. Competitiveness.
1. It has both high computing power and high energy efficiency, and has been adapted to a variety of Transformer models
AX650N chip is another high-performance intelligent vision chip launched by Aixin Yuanzhi after the AX620 and AX630 series.
This SoC adopts a heterogeneous multi-core design, integrating an 8-core A55 CPU, a high computing power NPU of 43.2TOPs@INT4 or 10.8TOPs@INT8, an ISP that supports 8K@30fps, and H.264 and H.265 editors. Decoded VPU.
In terms of interfaces, AX650N supports 64bit LPDDR4x, multiple MIPI inputs, Gigabit Ethernet, USB and HDMI 2.0b outputs, and supports 32 channels of 1080p@30fps decoding.
For the deployment of large models on the edge and end sides, AX650N has the advantages of high performance, high precision, low power consumption, and easy deployment.
Specifically, when Aixin Yuanzhi AX650N runs SwinT, the high performance of 361 frames is comparable to high-end GPU-based domain control SoCs in the field of automotive autonomous driving; the high accuracy of 80.45% is higher than the market average; 199FPS/W The speed reflects low power consumption, which is several times better than the current high-end GPU-based domain control SoC.

Aixin Yuanzhi explained that in the early days, edge-side and end-side customers paid more attention to the number of T computing power, but this is an indirect data. What users ultimately care about is how fast the model can run in actual business, as well as deployment How low is the cost and cost of use.
In this regard, AX650N supports low-bit mixed precision. If users use INT4, they can greatly reduce memory and bandwidth usage and effectively control the cost of end-side and edge-side deployment.
Currently, AX650N has been adapted to Transformer models such as ViT/DeiT, Swin/SwinV2, DETR, etc., and can also run above 30 frames in DINOv2, which makes detection, classification, segmentation and other operations more convenient for users. AX650N-based products have already been applied in important computer vision scenarios such as smart cities, smart education, and intelligent manufacturing..

2. It is easy to deploy large models and can run the original GitHub model
Aixin Yuanzhi also created a new generation of AI tool chain Pulsar2. The tool chain includes four-in-one functions of model conversion, offline quantification, model compilation, and heterogeneous scheduling, which further strengthens the need for efficient deployment of network models. While deeply optimizing the NPU architecture, it also expands operator & model support. capabilities and scope, as well as support for Transformer structure networks.
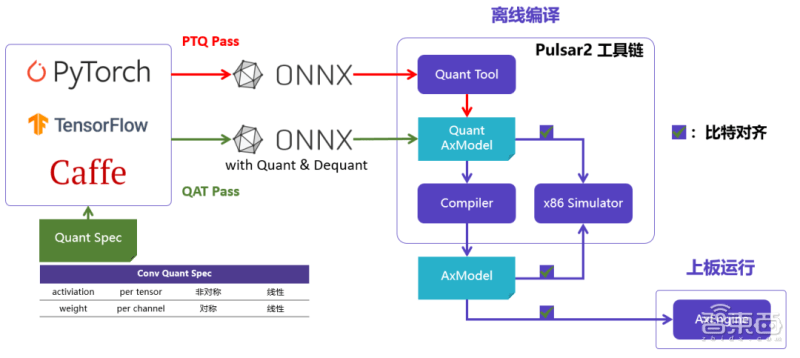
Aixin Yuanzhi found in practice that companies on the market that promote chips that can run SwinT usually need to make some modifications to the model. The modifications may cause a series of problems and bring more inconvenience to users.
Previously, most of the visual Transformer models similar to SwinT were deployed on cloud servers because GPUs are more friendly to MHA structure calculation support. On the contrary, edge-side/device-side AI chips have to ensure the CNN structure model due to their architectural limitations. The efficiency is better. Basically, there is not much performance optimization on the MHA structure, and the network structure even needs to be modified before it can be deployed reluctantly.
The AX650N is easy to deploy. You can efficiently run the original model on GitHub on the Aixin Yuanzhi platform without modifying it or retraining QAT.
"Our users have reported that our platform is currently the best platform for Transformer support, and we also see the possibility of implementing large models on our platform." Liu Jianwei said that customers can appreciate the AX650N As an AI computing power platform, the final implementation effect is better and easier to use, it is more adaptable to scenarios, and it is faster to get started, which greatly improves user efficiency and shortens the mass production cycle.
Customer feedback collected by Aixin Yuanzhi shows that after getting the development board and documentation of Aixin Yuanzhi, it can basically complete the reproduction of the demo and run the private network model in one hour.
The AX650N chip can quickly adapt to emerging network structures, thanks to a certain degree of flexibility and programmability in hardware and software design. Next, Aixin Yuanzhi AX650N will continue to optimize the Transformer structure and explore more large Transformer models such as multi-modal large models.
Aixin Yuanzhi will also launch the AXera-Pi Pro development board based on AX650N, and put more information and AI examples on GitHub so that developers can quickly explore richer product applications.
3. Visual application scenarios have created an urgent need for the Transformer model
According to Aixin Yuanzhi, deploying large visual models on the edge or end side can help solve the problem of high investment in AI intelligent applications in long-tail scenarios.
The previous method of river garbage monitoring was that after discovering garbage on the river, data collection and labeling were first required, and then model training was performed. If new litter appears in a river channel that has not been previously covered by data annotations and trained models, the model may not be able to identify it. Retraining from scratch is time-consuming and labor-intensive.
The Transformer large model has semantic understanding capabilities and is more versatile than the traditional CNN model. It can understand and perform a wider range of downstream tasks without knowing all complex visual scenes in advance. Using pre-trained large models with unsupervised training, new garbage that has never been seen before can be identified.
Aixin Yuanzhi told Xinxi that at present, all application scenarios that use cameras to capture images have begun to have an urgent demand for Transformer large models. The specific implementation speed depends on the R&D and development of customers in each segment. Resource investment status.
From the perspective of chip architecture design, in order to make the Transformer model deploy faster on the edge or end side, on the one hand, we must try to reduce the bandwidth usage of large models, and on the other hand, we need to optimize the structure of the Transformer. The relevant person in charge of Aixin Yuanzhi said that the engineering experience accumulated in the actual deployment of AX650N will be iterated into the next generation chip platform, allowing the Transformer model to run faster and better, giving it a certain first-mover advantage compared to other peers.
“This is why Aixin’s chip platform is the best choice for the implementation of Transformer, because when everyone is making the model smaller, they must want to see the effect of running on the end side. We have such a platform that can do this Such a closed-loop experiment,” he said.
In order to further optimize the Transformer inference effect, Aixin Yuanzhi will focus on how to enable the hardware to efficiently read discrete data, and to enable supporting calculations to match the data reading. In addition, Aixin Yuanzhi is also trying to use 4bit to solve the problem of large model parameters, and exploring support for some sparse or mixed expert system (MOE, Mixture of Experts) models.
Conclusion: High-performance AI chips form the cornerstone of large-scale model deployment
From the mass production of the first high-performance AI vision chip AX630A in 2020, to the second-generation self-developed edge-side smart chip AX620A in 2021, to the newly released third-generation AX650N chip, Aixin Yuanzhi has continued to Launched AI vision chips with high computing power and high energy efficiency to meet the needs of AI applications on the end and edge sides.
Dr. Qiu Xiaoxin, founder, chairman and CEO of Aixin Yuanzhi, said that the development of artificial intelligence technology continues to create new opportunities. Previous waves of technology have promoted Aixin Yuanzhi’s development in chip technologies such as visual processing and automotive electronics. The recent progress in large models has created new opportunities for Aixin’s persistent exploration on the end side and edge side in the past few years.
The related R&D and implementation plans of Aixin all aim at one goal, that is, when users or potential users think of Transformer, they can think of Aixin Yuanzhi, and then develop more based on Aixin Yuanzhi's AI computing power platform. The application of the Transformer model will ultimately accelerate the implementation of large models and intelligent applications on the end and edge sides.
In turn, the accumulation of more deployment experience will also promote the continuous evolution of Aixin Yuanzhi’s chips and software, and help algorithm engineers further promote Transformer model innovation by providing higher-performance, easier-to-use tools. The door to applied imagination.
The above is the detailed content of What kind of AI chip is needed to put a large model into a camera? Aixin Yuanzhi's answer is AX650N. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



