

Because our business is relatively complex, multiple related SQL statements that make up a transaction are necessary. So, let’s first explain what a transaction is. A transaction refers to a group of SQL statements that are executed together. All must be executed successfully or all failed. Partial success or partial failure is not allowed. A transaction has ACID characteristics:
Atomicity: Either all succeed or all fail, so as to ensure the consistency of the transaction;
Consistency: For example, in a bank transfer, if you deduct one person's money, you must add money to another person. You cannot just deduct without adding. In this way, there will be problems in the business and the consistency of the data will be Destroyed;
Persistence:When we commit the data, the data is written to the cache first, and the data in the cache still takes time to be transferred to the disk. Write above, if there is a power outage, downtime or restart at this time, we have redo log to ensure the durability of the database;
Isolation: This section can explain why transactions must be isolated, because transactions must be allowed to be executed concurrently. One business involves many transactions, and we often have many businesses in the background. We must be able to allow them to execute concurrently. If all transactions are executed serially, If so, then when we write a multi-threaded program, we only have one thread to do things, which is very inefficient. Therefore, transactions must be executed concurrently, but concurrent execution involves some issues: Security & Consistency of Transactions and Concurrency Efficiency Issues. We use these two things as reference points to We have obtained different levels of concurrency/isolation in MySQL. If we do not isolate the transaction at all when the transaction is executed concurrently, dirty reading may occur (transaction B reads the uncommitted data of transaction A and then uses the transaction A's uncommitted data is used for calculations, and many other results are obtained. Then transaction A rolls back that data. Then transaction B's calculations are all problematic data, and dirty reading will definitely cause problems), Non-repeatable reading (Retrieve a piece of data under the same conditions, and then find that the value of the data has changed when querying again. Of course, non-repeatable reading may not be a problem. It is allowed in some business scenarios. This is the same as Whether the security and consistency of business data are strictly related) and phantom reading (the amount of data in the results of two queries before and after the same conditions are different in the transaction) are these issues.
Then in order to solve the problems encountered in the concurrent execution of transactions, we give the isolation level of the transaction:
Serialization. Serialization is completely implemented using locks. All transactions are sorted through locks and executed in order. In this way, data security is high but concurrency efficiency is very low. Generally, we will not do this.
Uncommitted read, for the multi-threaded program we wrote, there is no concurrency control for the critical section code segment. Although the concurrency is high, the data security is very low. Committed reads also allow the existence of dirty reads, which is problematic so uncommitted reads should never be used. Serialization and uncommitted read will not be used in actual projects. Generally, the database engine works on committed read and repeatable read by default. These two isolation levels combine the security & consistency of the data. and data concurrency efficiency, these two are implemented by the MVCC multi-version concurrency control mechanism.
Read committed, Oracle default work level. Reading of uncommitted data is not allowed. This level still allows non-repeatable reads and virtual reads to occur.
Repeatable read, MySQL default working level. It is guaranteed that the same data will still be obtained when the transaction is read again, which partially solves the virtual read, but the virtual read will still occur

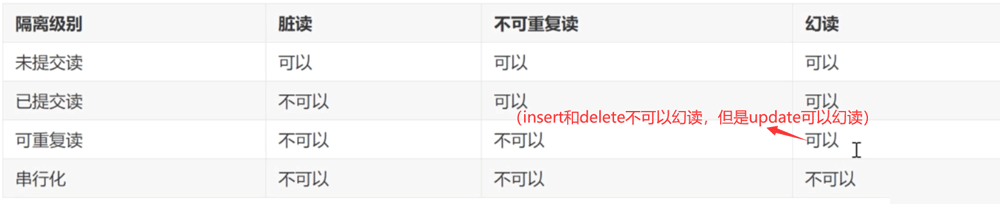
Note:
The higher the transaction isolation level, the more performance is spent to avoid conflicts, that is, the efficiency is low.
At the "repeatable read" level, it can actually solve some of the virtual read problems, but it cannot prevent the virtual read problems caused by update updates. To prohibit the occurrence of virtual reads, you still need to set Serialization isolation level.
The implementation principle of transaction isolation level: Lock MVCC. The underlying implementation principle of serialization is locks. Locks include shared locks, exclusive locks, intention shared locks, intention exclusive locks, gap locks and deadlocks. The underlying implementation principle of InnoDB's committed read and repeatable read: MVCC (multiple Version concurrency control), MVCC provides a concurrent reading method, including snapshot reading (the same data will have multiple versions), current reading, undo log and redo log. MVCC is the principle of committed read and repeatable read, and lock is the principle of serialization

Transaction logs are used to implement ACID features, while shared locks, exclusive locks, and MVCC are used to implement consistency (I) features. The transaction log is divided into undo log (rollback log) and redo log (redo log)
Table Level lock: Lock the entire table. The overhead is small (because you don’t need to find the record of a certain row in the table to lock it. If you want to modify this table, you directly apply for the lock of this table), the lock is fast, and there will be no
Deadlock is present;The lock granularity is large, the probability of lock conflict is high, and the concurrency is low
Row-level lock:For a certain Row records are locked. It is expensive (you need to find the corresponding record in the table, and there is a process of searching the table and index), locking is slow, and deadlock will occur; the locking granularity is the smallest, the probability of lock conflict is the lowest, and the concurrency is high
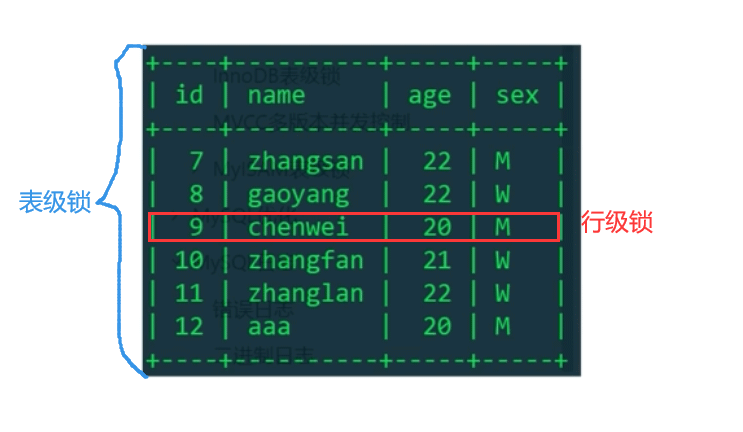
MyISAM storage engine only supports table-level locks, while InnoDB supports transaction processing, row-level locks, and better concurrency capabilities

##Exclusive lock: Also known as X lock, write lock
Shared lock: Also known as S lock, read lock

Check the isolation level:

First open a transaction A and add an exclusive lock to the data with id=7:

Open transaction B on another client:
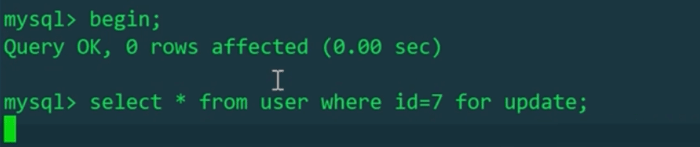

Summary: For data locks between different transactions, only SS locks can coexist, XX, SX, and XS cannot coexist.
2. Test row locks added in The execution lock on the index itemis added to the index tree.



InnoDB’s row lock is implemented by locking index entries, rather than locking table row records
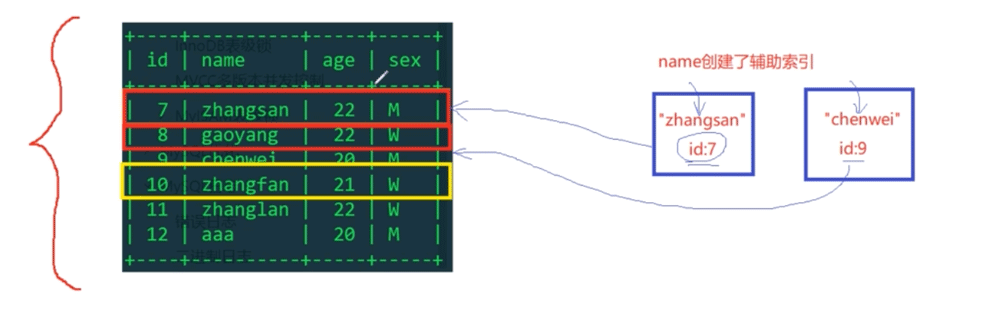
And we Using name as a filter condition does not use an index, so naturally row locks will not be used, but table locks will be used. This means that InnoDB uses row-level locks only when data is retrieved through the index, otherwise InnoDB will use table locks!!!We add an index to the name field:
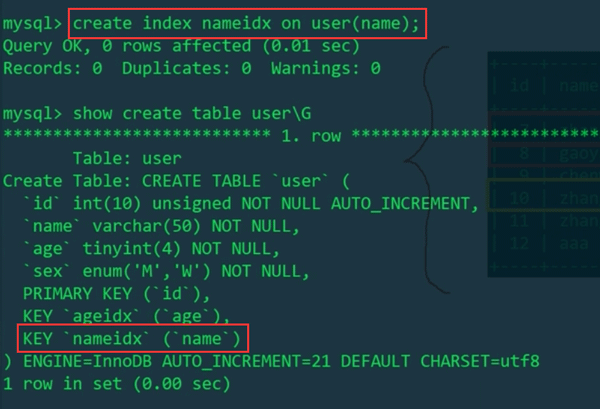
Then do the operation just now:

We found that after adding an index to name, two transactions can obtain exclusive locks (for update) on different rows, which once again proves that InnoDB's row locks are added to the index items.
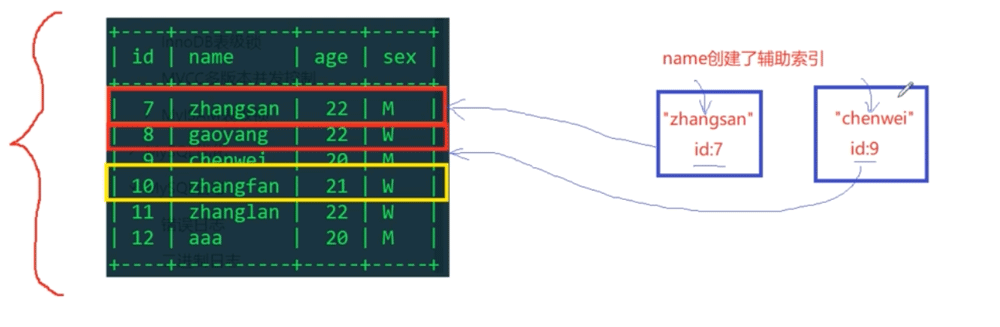
Because name now goes through the index, use zhangsan to find the id of the row record where it is located in the auxiliary index tree, which is 7, and then go to the primary key index tree to get the corresponding row. Record exclusive lock (personal guess is that the corresponding records in the auxiliary index tree and primary key index tree are locked)
Serialize all transactions are all shared locks or exclusive locks, no need to add them manually. Select acquires a shared lock, and insert, delete, and update acquire exclusive locks.
Set serialization isolation level:

Two transactions can acquire shared locks at the same time (SS coexistence:
Now let transaction 2 insert data;

Because Insert needs to be added It locks, but since transaction 1 has added a shared lock to the entire table, transaction 2 can no longer successfully lock the table (sx does not coexist)
Rollback and change all lock acquisition statuses Roll back:

##Open two transactions:
Transaction 2update;



If there is an index, use the row lock; if there is no index, Then use table locks.
Table-level locks or row-level locks refer to the granularity of the lock, while shared locks and exclusive locks refer to the nature of the lock, whether it is a table lock or a row lock. , there is a distinction between shared locks and exclusive locks.
Serialization plays with exclusive locks and shared locks. At the repeatable read level, if you do not manually lock, MVCC is used The mechanism actually does not use locks. We can also manually add locks. If InnoDB does not create an index, it uses table locks. If the index item is used in the query, it uses row locks. Row locks are Lock the index instead of simply locking a row of data.The above is the detailed content of What are table-level locks, row-level locks, exclusive locks and shared locks in MySQL?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



