

How to solve the problem of count distinct multiple columns in mysql

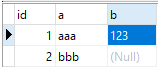
The reproduced test database is as follows:
CREATE TABLE `test_distinct` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` varchar(50) CHARACTER SET utf8 DEFAULT NULL, `b` varchar(50) CHARACTER SET utf8 DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
The test data in the table is as follows. Now we need to count the number of columns after deduplication of these three columns.
Problem Analysis
My friend gave me four query statements to locate the problem
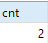
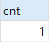
SELECT COUNT(*) AS cnt FROM test_distinct; SELECT COUNT(DISTINCT id, a, b) as cnt FROM test_distinct; SELECT id, a, b, COUNT(*) AS cnt FROM test_distinct GROUP BY id, a, b HAVING cnt > 1; SELECT l.id AS l_id, l.a AS l_a, l.b AS l_b, r.id AS r_id, r.a AS r_a, r.b AS r_b FROM test_distinct l LEFT JOIN test_distinct r ON l.id = r.id AND l.a = r.a AND l.b = r.b WHERE r.id is NULL or r.id = 'null';
The query results are as follows:


Notice! ! ! From the test data, we can quickly guess where the problem lies, but it turns out that there are more than 30,000 pieces of data in the table, and it is impossible to view the data with the naked eye.
There are two counterintuitive points in the above query results:
The second piece of data is missing after deduplication statistics, but the result of the third piece of data shows There is no identical data.
When using the same table to do a left outer connection, the driving table has data, but the driven table is empty.
Let’s look at the second question first. The official document has the following explanation:
When using the ON clause, the conditions it contains The expression is the same as that used in the WHERE clause. A common situation is to use the ON clause to specify the join conditions of the table, and use the WHERE clause to limit the rows included in the result set.
If there are no matching rows in the right table for the conditions in the ON or USING part of the LEFT JOIN, then the right table uses all columns set to NULL.
You cannot use arithmetic comparison operators (such as =, < or <>) to compare NULL.
SELECT NULL = NULL; SELECT NULL IS NULL;
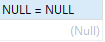
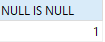
So the second problem is that the result of NULL=NULL is always False, which results in the two rows originally Equal data results are not equal.
But this does not solve the first problem: why a piece of data disappeared after deduplication. However, we can guess that the missing data is probably related to the NULL value.
We separate the two operations of count and distinct:
SELECT COUNT(*) as cnt FROM (SELECT DISTINCT id, a, b FROM test_distinct) as tmp;
Huh? The result is correct, which means that the query plan generated by count(distinct expr) may be different from what we imagined. It is not to remove duplicates first and then count. Use explain to analyze the query plan of the two statements. As shown below:


As you can see from the table, the mysql execution engine directly counts count(distinct expr)As a query, check the official documentation:
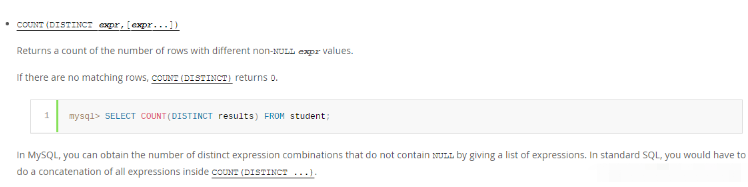
Solution
The problem has finally been clarified. There are two ways to solve this problem. The first is to remove duplicates first and then count. The second is to use the IFNULL() function:
SELECT COUNT(DISTINCT id, a, IFNULL(b, '0')) as cnt FROM test_distinct;
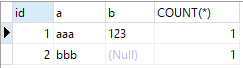
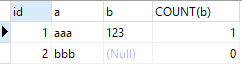
In addition, count( )Use:
SELECT id, a, b, COUNT(*) FROM test_distinct GROUP BY id, a, b; SELECT id, a, b, COUNT(b) FROM test_distinct GROUP BY id, a, b;
Knowledge point
You cannot use arithmetic comparison operators (such as =, ) to compare null values;
count(distinct expr) returns the number of distinct and non-empty rows in the expr column;
COUNT() has two distinct uses: it can be used to count the number of values in a column, or it can be used to count the number of rows. When counting column values, the column value is required to be non-empty (NULL is not counted). When a column or expression is specified in parentheses of the COUNT() function, the function counts the number of results that have a value in the expression. Another function of COUNT() is to count the number of rows in the result set. When MySQL confirms that the expression value within the parentheses cannot be empty, it is actually counting the number of rows. The simplest thing is when we use COUNT(). In this case, the wildcard does not expand to all columns as we guessed. In fact, it will ignore all columns and directly count all rows - "High-Performance MySQL";
In InnoDB, SELECT COUNT(*) and SELECT COUNT(1) are processed in the same way, and there is no performance difference.
The above is the detailed content of How to solve the problem of count distinct multiple columns in mysql. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL: The Ease of Data Management for Beginners
Apr 09, 2025 am 12:07 AM
MySQL is suitable for beginners because it is simple to install, powerful and easy to manage data. 1. Simple installation and configuration, suitable for a variety of operating systems. 2. Support basic operations such as creating databases and tables, inserting, querying, updating and deleting data. 3. Provide advanced functions such as JOIN operations and subqueries. 4. Performance can be improved through indexing, query optimization and table partitioning. 5. Support backup, recovery and security measures to ensure data security and consistency.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to create navicat premium
Apr 09, 2025 am 07:09 AM
How to create navicat premium
Apr 09, 2025 am 07:09 AM
Create a database using Navicat Premium: Connect to the database server and enter the connection parameters. Right-click on the server and select Create Database. Enter the name of the new database and the specified character set and collation. Connect to the new database and create the table in the Object Browser. Right-click on the table and select Insert Data to insert the data.
 How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
How to create a new connection to mysql in navicat
Apr 09, 2025 am 07:21 AM
You can create a new MySQL connection in Navicat by following the steps: Open the application and select New Connection (Ctrl N). Select "MySQL" as the connection type. Enter the hostname/IP address, port, username, and password. (Optional) Configure advanced options. Save the connection and enter the connection name.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
How to execute sql in navicat
Apr 08, 2025 pm 11:42 PM
Steps to perform SQL in Navicat: Connect to the database. Create a SQL Editor window. Write SQL queries or scripts. Click the Run button to execute a query or script. View the results (if the query is executed).
 Navicat connects to database error code and solution
Apr 08, 2025 pm 11:06 PM
Navicat connects to database error code and solution
Apr 08, 2025 pm 11:06 PM
Common errors and solutions when connecting to databases: Username or password (Error 1045) Firewall blocks connection (Error 2003) Connection timeout (Error 10060) Unable to use socket connection (Error 1042) SSL connection error (Error 10055) Too many connection attempts result in the host being blocked (Error 1129) Database does not exist (Error 1049) No permission to connect to database (Error 1000)
