

What are the pitfalls of redis distributed locks?

1 Non-atomic operation
When using redis distributed lock, the first thing we think of may be the setNx command.
if (jedis.setnx(lockKey, val) == 1) {
jedis.expire(lockKey, timeout);
}Easy, three times five divided by two, we can write the code.
This code can indeed lock successfully, but have you found any problems?
The locking operation and the following setting the timeout period are separate and non-atomic operations.
If the lock is successful but the timeout cannot be set, the lockKey will be valid forever. If in a high-concurrency scenario, a large number of lockKeys are successfully locked but will not fail, it may directly lead to insufficient redis memory space.
So, is there a locking command that guarantees atomicity?
The answer is: Yes, please see below.
2 Forgot to release the lock
As mentioned above, the locking operation using the setNx command and setting the timeout are separate and are not atomic operations.
There is also a set command in redis, which can specify multiple parameters.
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;Among them:
lockKey: The identification of the lockrequestId: Request idNX: The key is set only when the key does not exist.#PX: Set the expiration time of the key to millisecond milliseconds.expireTime: expiration time
set command is an atomic operation, locking and setting Timeout can be easily solved with one command.
Use the set command to lock, and there seems to be no problem on the surface. But if you think about it carefully, after locking, would it be a bit unreasonable to release the lock after the timeout period is reached every time? After locking, if the lock is not released in time, there will be many problems.
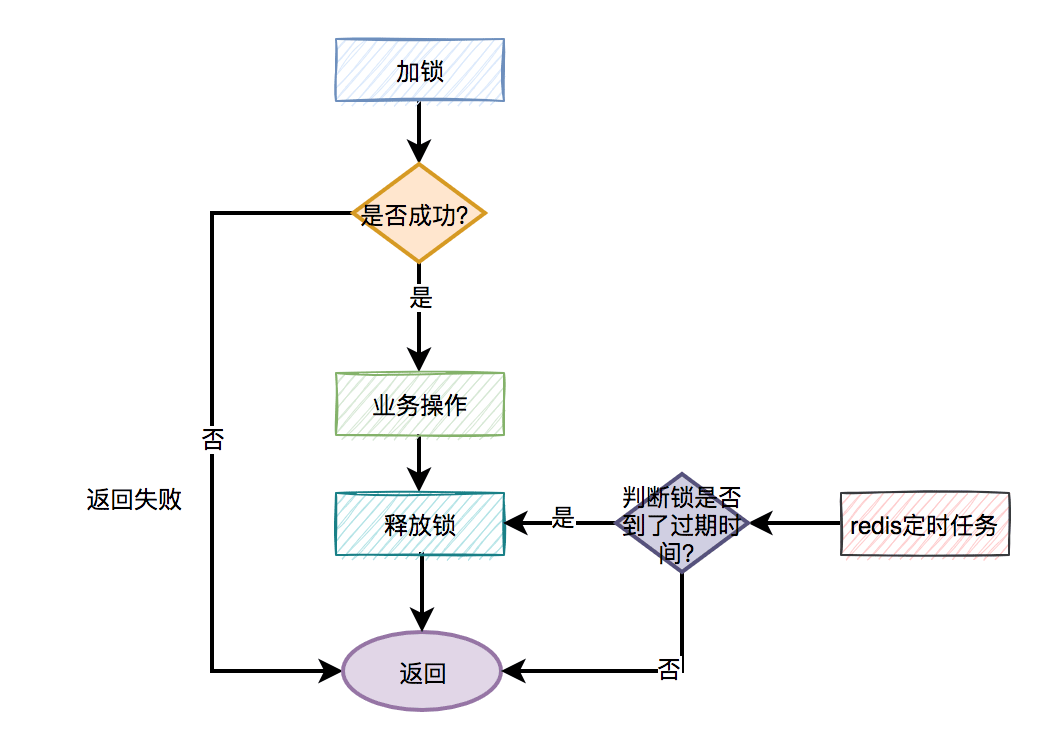
A more reasonable usage of distributed lock is:
Manual locking
Business operation
Manually releasing the lock
If the manual lock release fails, the timeout is reached and redis will automatically release the lock.
The general flow chart is as follows:
Then the question is, how to release the lock?
The pseudo code is as follows:
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
} Need to catch the exception of the business code, and then release the lock in finally. In other words: regardless of whether the code execution succeeds or fails, the lock needs to be released.
At this point, some friends may ask: If the system is restarted just when the lock is released, or the network is disconnected, or the computer room has a breakpoint, will it also cause the lock release to fail?
This is a good question, because this small probability problem does exist.
But do you remember that we set the timeout for the lock earlier? Even if an abnormal situation occurs and the lock release fails, the lock will still be automatically released by redis after the timeout we set.
But is it enough to only release the lock in finally?
3 Release someone else's lock
Answering the previous question is a kind gesture, but it is not enough to release the lock in finally, because the way the lock is released is also important.
What's wrong?
Answer: In a multi-threaded scenario, someone else's lock may be released.
Some friends may refute: Suppose in a multi-threaded scenario, thread A acquires the lock, but if thread A does not release the lock, at this time, thread B cannot acquire the lock, so how can it release others? Lock theory?
Answer: If thread A and thread B both use lockKey to lock. Although thread A successfully acquired the lock, the execution time of its business function exceeded the timeout setting. At this time, redis will automatically release the lockKey lock. At this time, thread B can successfully lock the lockKey and then perform its business operations. At exactly this time, thread A has finished executing the business function, and then releases the lockKey in the finally method. Isn't there a problem? Thread B's lock is released by thread A.
I think at this time, Thread B must have fainted in the toilet crying, and he was still talking plausibly.
So, how to solve this problem?
I wonder if you have noticed? When using the set command to lock, in addition to using the lockKey lock identifier, an additional parameter is set: requestId. Why do we need to record the requestId?
Answer: requestId is used when releasing the lock.
The pseudo code is as follows:
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;When releasing the lock, first obtain the value of the lock (the previously set value is requestId), and then determine the value that is the same as the previously set value. Whether the values are the same, if they are the same, the lock is allowed to be deleted and success is returned. If they are different, failure will be returned directly.
In other words: You can only release the locks you added, and you are not allowed to release the locks added by others.
Why do we need to use requestId here? Can't we use userId?
If userId is used, it is not unique for the request. It is possible that different requests will use the same userId. The requestId is globally unique, and there is no confusion in locking and releasing locks.
此外,使用lua脚本,也能解决释放了别人的锁的问题:
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end
lua脚本能保证查询锁是否存在和删除锁是原子操作,用它来释放锁效果更好一些。
说到lua脚本,其实加锁操作也建议使用lua脚本:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);这是redisson框架的加锁代码,写的不错,大家可以借鉴一下。
有趣,下面还有哪些好玩的东西?
4 大量失败请求
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
在秒杀场景下,会有什么问题?
答:每1万个请求,有1个成功。再1万个请求,有1个成功。如此下去,直到库存不足。这就变成均匀分布的秒杀了,跟我们想象中的不一样。
如何解决这个问题呢?
此外,还有一种场景:
比如,有两个线程同时上传文件到sftp,上传文件前先要创建目录。假设两个线程需要创建的目录名都是当天的日期,比如:20210920,如果不做任何控制,直接并发的创建目录,第二个线程必然会失败。
这时候有些朋友可能会说:这还不容易,加一个redis分布式锁就能解决问题了,此外再判断一下,如果目录已经存在就不创建,只有目录不存在才需要创建。
伪代码如下:
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;一切看似美好,但经不起仔细推敲。
来自灵魂的一问:第二个请求如果加锁失败了,接下来,是返回失败,还是返回成功呢?
主要流程图如下:
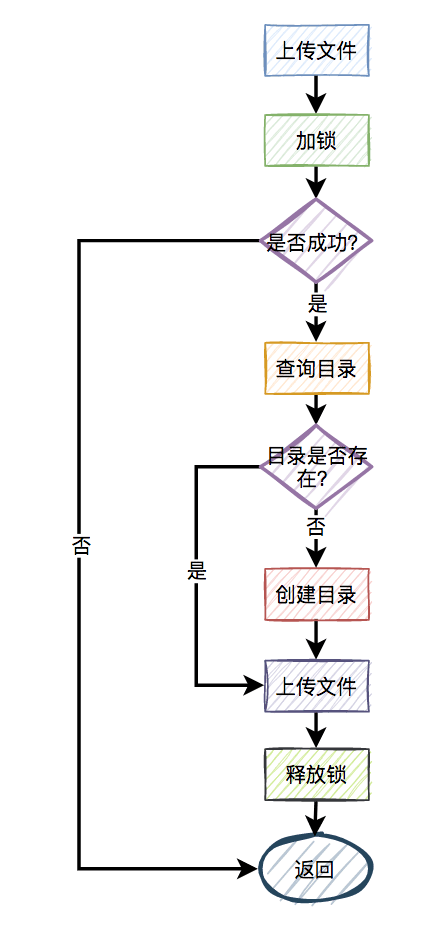
显然第二个请求,肯定是不能返回失败的,如果返回失败了,这个问题还是没有被解决。如果文件还没有上传成功,直接返回成功会有更大的问题。头疼,到底该如何解决呢?
答:使用自旋锁。
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
long time = System.currentTimeMillis() - start;
if (time>=timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;在规定的时间,比如500毫秒内,自旋不断尝试加锁(说白了,就是在死循环中,不断尝试加锁),如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
好吧,学到一招了,还有吗?
5 锁重入问题
我们都知道redis分布式锁是互斥的。如果已经对一个key进行了加锁,并且该key对应的锁尚未失效,那么如果再次使用相同的key进行加锁,很可能会失败。
没错,大部分场景是没问题的。
为什么说是大部分场景呢?
因为还有这样的场景:
假设在某个请求中,需要获取一颗满足条件的菜单树或者分类树。我们以菜单为例,这就需要在接口中从根节点开始,递归遍历出所有满足条件的子节点,然后组装成一颗菜单树。
在后台系统中运营同学可以动态地添加、修改和删除菜单,因此需要注意菜单是可变的,不能一成不变。为了确保在并发情况下每次都可以获取到最新数据,可以使用Redis分布式锁。
加redis分布式锁的思路是对的。然而,随后出现了一个问题,即递归方法中进行多次递归遍历时,每次都需要获取同一把锁。当然,在递归的第一层可以成功加锁,但在第二、第三……第N层就会失败
递归方法中加锁的伪代码如下:
private int expireTime = 1000;
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}如果你直接这么用,看起来好像没有问题。但最终执行程序之后发现,等待你的结果只有一个:出现异常。
因为从根节点开始,第一层递归加锁成功,还没释放锁,就直接进入第二层递归。因为锁名为lockKey,并且值为requestId的锁已经存在,所以第二层递归大概率会加锁失败,然后返回到第一层。第一层接下来正常释放锁,然后整个递归方法直接返回了。
这下子,大家知道出现什么问题了吧?
没错,递归方法其实只执行了第一层递归就返回了,其他层递归由于加锁失败,根本没法执行。
那么这个问题该如何解决呢?
答:使用可重入锁。
我们以redisson框架为例,它的内部实现了可重入锁的功能。
古时候有句话说得好:为人不识陈近南,便称英雄也枉然。
我说:分布式锁不识redisson,便称好锁也枉然。哈哈哈,只是自娱自乐一下。
由此可见,redisson在redis分布式锁中的江湖地位很高。
伪代码如下:
private int expireTime = 1000;
public void run(String lockKey) {
RLock lock = redisson.getLock(lockKey);
this.fun(lock,1);
}
public void fun(RLock lock,int level){
try{
lock.lock(5, TimeUnit.SECONDS);
if(level<=10){
this.fun(lock,++level);
} else {
return;
}
} finally {
lock.unlock();
}
}上面的代码也许并不完美,这里只是给了一个大致的思路,如果大家有这方面需求的话,以上代码仅供参考。
接下来,聊聊redisson可重入锁的实现原理。
加锁主要是通过以下脚本实现的:
if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);
其中:
KEYS[1]:锁名
ARGV[1]:过期时间
ARGV[2]:uuid + ":" + threadId,可认为是requestId
先判断如果锁名不存在,则加锁。
接下来,判断如果锁名和requestId值都存在,则使用hincrby命令给该锁名和requestId值计数,每次都加1。注意一下,这里就是重入锁的关键,锁重入一次值就加1。
如果锁名存在,但值不是requestId,则返回过期时间。
释放锁主要是通过以下脚本实现的:
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then
return nil
end
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil先判断如果锁名和requestId值不存在,则直接返回。
如果锁名和requestId值存在,则重入锁减1。
如果减1后,重入锁的value值还大于0,说明还有引用,则重试设置过期时间。
如果减1后,重入锁的value值还等于0,则可以删除锁,然后发消息通知等待线程抢锁。
再次强调一下,如果你们系统可以容忍数据暂时不一致,有些场景不加锁也行,我在这里只是举个例子,本节内容并不适用于所有场景。
6 锁竞争问题
如果有大量需要写入数据的业务场景,使用普通的redis分布式锁是没有问题的。
但如果有些业务场景,写入的操作比较少,反而有大量读取的操作。这样直接使用普通的redis分布式锁,会不会有点浪费性能?
我们都知道,锁的粒度越粗,多个线程抢锁时竞争就越激烈,造成多个线程锁等待的时间也就越长,性能也就越差。
所以,提升redis分布式锁性能的第一步,就是要把锁的粒度变细。
6.1 读写锁
众所周知,加锁的目的是为了保证,在并发环境中读写数据的安全性,即不会出现数据错误或者不一致的情况。
在大多数实际业务场景中,通常读取数据的频率远高于写入数据的频率。而线程间的并发读操作是并不涉及并发安全问题,我们没有必要给读操作加互斥锁,只要保证读写、写写并发操作上锁是互斥的就行,这样可以提升系统的性能。
我们以redisson框架为例,它内部已经实现了读写锁的功能。
读锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//业务操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}写锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//业务操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}将读锁和写锁分离的主要优点在于提高读取操作的性能,因为读取操作之间是共享的,而不存在互斥关系。而我们的实际业务场景中,绝大多数数据操作都是读操作。所以,如果提升了读操作的性能,也就会提升整个锁的性能。
下面总结一个读写锁的特点:
读与读是共享的,不互斥
读与写互斥
写与写互斥
6.2 锁分段
此外,为了减小锁的粒度,比较常见的做法是将大锁:分段。
在java中ConcurrentHashMap,就是将数据分为16段,每一段都有单独的锁,并且处于不同锁段的数据互不干扰,以此来提升锁的性能。
放在实际业务场景中,我们可以这样做:
比如在秒杀扣库存的场景中,现在的库存中有2000个商品,用户可以秒杀。为了防止出现超卖的情况,通常情况下,可以对库存加锁。如果有1W的用户竞争同一把锁,显然系统吞吐量会非常低。
为了提升系统性能,我们可以将库存分段,比如:分为100段,这样每段就有20个商品可以参与秒杀。
在秒杀过程中,先通过哈希函数获取用户ID的哈希值,然后对100取模。模为1的用户访问第1段库存,模为2的用户访问第2段库存,模为3的用户访问第3段库存,后面以此类推,到最后模为100的用户访问第100段库存。
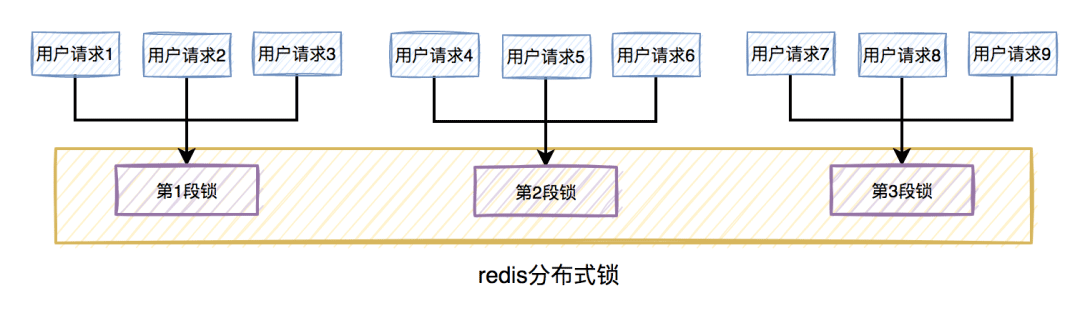
如此一来,在多线程环境中,可以大大的减少锁的冲突。以前多个线程只能同时竞争1把锁,尤其在秒杀的场景中,竞争太激烈了,简直可以用惨绝人寰来形容,其后果是导致绝大数线程在锁等待。由于多个线程同时竞争100把锁,等待线程数量减少,因此系统吞吐量提高了。
分段锁虽然能提高系统性能,但也会增加系统复杂度,需要注意。因为它需要引入额外的路由算法,跨段统计等功能。我们在实际业务场景中,需要综合考虑,不是说一定要将锁分段。
7 锁超时问题
我在前面提到过,如果线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间,这时候redis会自动释放线程A加的锁。
有些朋友可能会说:到了超时时间,锁被释放了就释放了呗,对功能又没啥影响。
答:错,错,错。对功能其实有影响。
我们通常会对关键资源进行加锁,以避免在访问时产生数据异常。比如:线程A在修改数据C的值,线程B也在修改数据C的值,如果不做控制,在并发情况下,数据C的值会出问题。
为了保证某个方法,或者段代码的互斥性,即如果线程A执行了某段代码,是不允许其他线程在某一时刻同时执行的,我们可以用synchronized关键字加锁。
但这种锁有很大的局限性,只能保证单个节点的互斥性。如果需要在多个节点中保持互斥性,就需要用redis分布式锁。
做了这么多铺垫,现在回到正题。
假设线程A加redis分布式锁的代码,包含代码1和代码2两段代码。
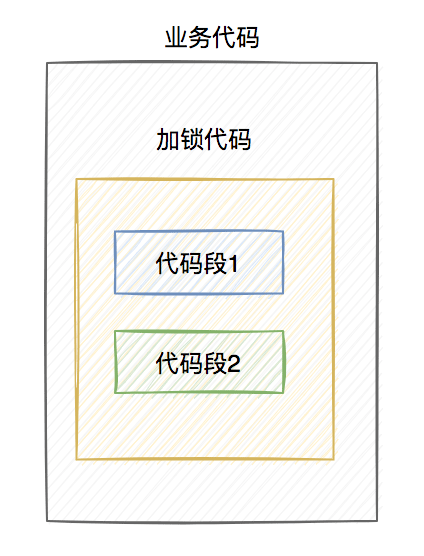
由于该线程要执行的业务操作非常耗时,程序在执行完代码1的时,已经到了设置的超时时间,redis自动释放了锁。而代码2还没来得及执行。
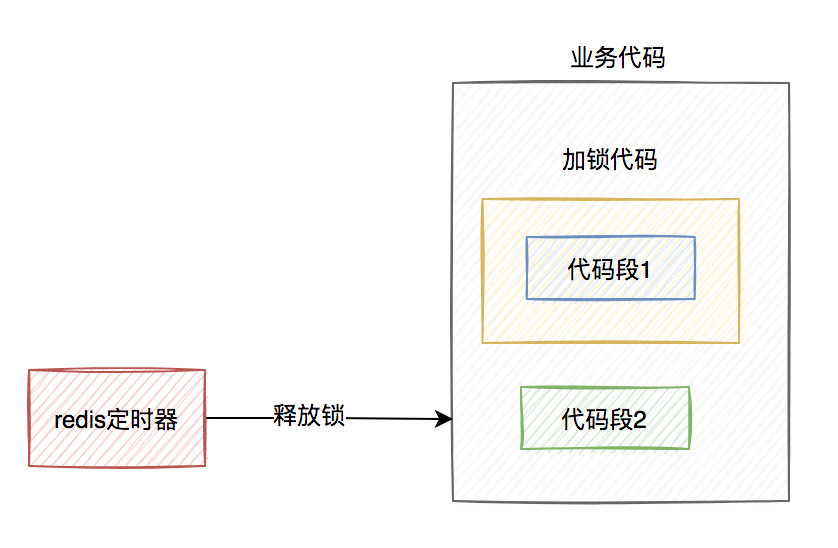
此时,代码2相当于裸奔的状态,无法保证互斥性。当多个线程访问同一临界资源时,如果存在并发访问,可能会导致数据异常。(PS:我说的访问临界资源,不单单指读取,还包含写入)
那么,如何解决这个问题呢?
答:如果达到了超时时间,但业务代码还没执行完,需要给锁自动续期。
我们可以使用TimerTask类,来实现自动续期的功能:
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自动续期逻辑
}
}, 10000, TimeUnit.MILLISECONDS);获取锁之后,自动开启一个定时任务,每隔10秒钟,自动刷新一次过期时间。这种机制在redisson框架中,有个比较霸气的名字:watch dog,即传说中的看门狗。
当然自动续期功能,我们还是优先推荐使用lua脚本实现,比如:
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('pexpire', KEYS[1], ARGV[1]); return 1; end; return 0;
需要注意的地方是:在实现自动续期功能时,还需要设置一个总的过期时间,可以跟redisson保持一致,设置成30秒。自动续期将在总的过期时间到达后停止,即使业务代码未完成执行。
实现自动续期的功能需要在获得锁之后开启一个定时任务,每隔10秒检查一次锁是否存在,如果存在则更新过期时间。如果续期3次,也就是30秒之后,业务方法还是没有执行完,就不再续期了。
8 主从复制的问题
上面花了这么多篇幅介绍的内容,对单个redis实例是没有问题的。
but,如果redis存在多个实例。当使用主从复制或哨兵模式,并且基于Redis分布式锁功能进行操作时,可能会遇到问题。
具体是什么问题?
假定当前Redis采用主从复制模式,具有一个主节点和三个从节点。master节点负责写数据,slave节点负责读数据。
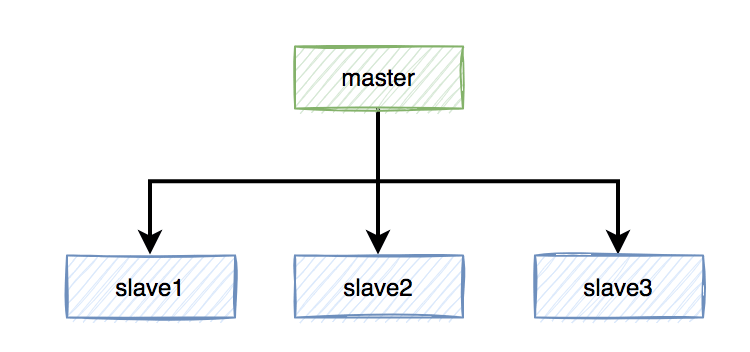
本来是和谐共处,相安无事的。在Redis中,加锁操作是在主节点上执行的,加锁成功后,会异步将锁同步到所有从节点。
突然有一天,master节点由于某些不可逆的原因,挂掉了。
这样需要找一个slave升级为新的master节点,假如slave1被选举出来了。
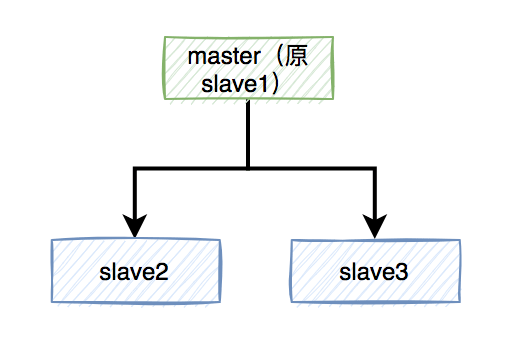
如果有个锁A比较悲催,刚加锁成功master就挂了,还没来得及同步到slave1。
这样会导致新master节点中的锁A丢失了。后面,如果有新的线程,使用锁A加锁,依然可以成功,分布式锁失效了。
那么,如何解决这个问题呢?
答:redisson框架为了解决这个问题,提供了一个专门的类:RedissonRedLock,使用了Redlock算法。
RedissonRedLock解决问题的思路如下:
需要搭建几套相互独立的redis环境,假如我们在这里搭建了5套。
每套环境都有一个redisson node节点。
Multiple redisson node nodes form RedissonRedLock.
The environment includes: stand-alone, master-slave, sentinel and cluster modes, which can be one or a mixture of multiple types.
Here we take the master-slave as an example. The architecture diagram is as follows:
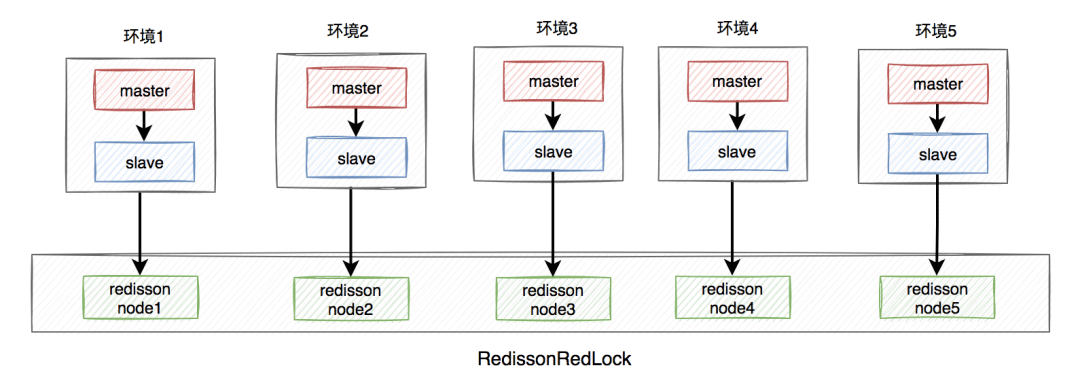
RedissonRedLock The locking process is as follows:
Get all redisson node information, and lock all redisson nodes in a loop. Assume that the number of nodes is N. In the example, N is equal to 5.
If among N nodes, N/2 1 nodes are successfully locked, then the entire RedissonRedLock lock is successful.
If among N nodes, less than N/2 1 node is successfully locked, then the entire RedissonRedLock lock fails.
If it is discovered that the total time spent on locking each node is greater than or equal to the set maximum waiting time, failure will be returned directly.
As can be seen from the above, using the Redlock algorithm can indeed solve the problem of distributed lock failure in multi-instance scenarios if the master node hangs up.
But it also raises some new questions, such as:
It is necessary to build multiple additional environments and apply for more resources, which needs to be evaluated. Cost and value for money.
If there are N redisson node nodes, it needs to be locked N times, at least N/2 times, to know whether the redlock lock is successful. Obviously, the extra time cost is added, which is not worth the gain.
It can be seen that in actual business scenarios, especially in high-concurrency businesses, RedissonRedLock is not actually used much.
In a distributed environment, CAP cannot be bypassed.
CAP refers to in a distributed system:
Consistency
Availability
Partition tolerance
These three elements can only achieve at most two at the same time. Point, it is impossible to take care of all three.
In your actual business scenario, what is more important is to ensure data consistency. Then please use a CP type distributed lock, such as zookeeper, which is disk-based and the performance may not be that good, but data will generally not be lost.
If you have an actual business scenario, what is more needed is to ensure high data availability. It is recommended to use memory-based distributed locks, such as AP type locks in Redis. Although its performance is better, there is a certain risk of data loss.
The above is the detailed content of What are the pitfalls of redis distributed locks?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
