

ChatGPT has been criticized for its mathematical abilities since its release.
Even "mathematical genius" Terence Tao once said that GPT-4 did not add much value in his own field of mathematics expertise.
What should I do, just let ChatGPT be a "mathematically retarded"?
OpenAI is working hard - In order to improve the mathematical reasoning capabilities of GPT-4, the OpenAI team uses "Process Supervision" (PRM) to train the model.
Let us verify step by step!

Paper address: https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step .pdf
In the paper, the researchers trained the model to achieve better results in mathematical problem solving by rewarding each correct reasoning step, known as "process supervision", rather than just rewarding the correct final result (result supervision). Latest SOTA.
Specifically, PRM solved 78.2% of the problems in the representative subset of the MATH test set.

# In addition, OpenAI found that "process supervision" is of great value in alignment - training the model to produce a chain of thoughts recognized by humans.
The latest research is of course indispensable for forwarding by Sam Altman, "Our Mathgen team has achieved very exciting results in process supervision, which is a positive sign of alignment."
In practice, "process supervision" requires manual feedback, which is extremely costly for large models and various tasks. Therefore, this work is of great significance and can be said to determine the future research direction of OpenAI.
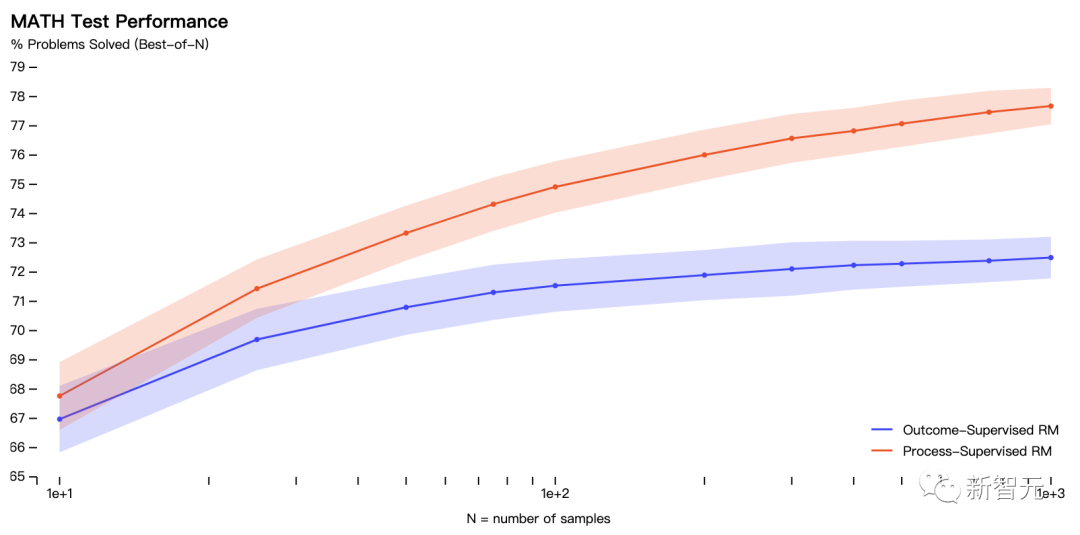
In the experiment, the researchers used questions in the MATH data set to evaluate the reward models of "process supervision" and "result supervision".
Have the model generate many solutions for each problem and then pick the solution with the highest ranking for each reward model.

The figure shows the percentage of selected solutions that resulted in a correct final answer as a function of the number of solutions considered.
The "process supervision" reward model not only performed better overall, but the performance gap widened as more solutions to each problem were considered.
This shows that the "process supervision" reward model is more reliable.
Below, OpenAI presents 10 mathematical problems and solutions for the model, as well as comments on the pros and cons of the reward model.
The model was evaluated from the following three types of indicators, true (TP), true negative (TN), and false positive (FP).
Let’s simplify the trigonometric function formula first.
This challenging trigonometric function problem requires the application of several identities in an unobvious order.
But most attempts at solution fail because it is difficult to choose which identities are actually useful.
While GPT-4 generally fails to solve this problem, with only 0.1% of solutions attempting to achieve the correct answer, the reward model correctly identifies this solution as valid.

Here, GPT-4 successfully performs a series of complex polynomial factorizations.
Using the Sophie-Germain identity in step 5 is an important step. It can be seen that this step is very insightful.

In steps 7 and 8, GPT-4 starts performing guesses and checks.
This is a common place where the model can "hallucinate" and claim that a particular guess was successful. In this case, the reward model validates each step and determines that the chain of thought is correct.

The model successfully applies several trigonometric identities to simplify the expression.

In step 7, GPT-4 attempts to simplify an expression, but the attempt fails. The reward model caught this bug.

In step 11, GPT-4 made a simple calculation error. Also discovered by the reward model.

GPT-4 attempted to use the squared difference formula in step 12, but this expression is not actually the squared difference.

The rationale for step 8 is weird, but the bonus model makes it pass. However, in step 9, the model incorrectly factors the expression.
The reward model corrects this error.

In step 4, GPT-4 incorrectly claims that "the sequence repeats every 12 items ”, but actually repeats every 10 items. This counting error occasionally fools the reward model.

In step 13, GPT-4 attempts to simplify the equation by combining similar terms. It correctly moves and combines the linear terms to the left, but incorrectly leaves the right side unchanged. The reward model is fooled by this error.

GPT-4 tries to do long division, but in step 16 it forgets to include the leading zero in the repeating part of the decimal. The reward model is fooled by this error.

GPT-4 made a subtle counting error in step 9.
On the surface, the claim that there are 5 ways to exchange balls of the same color (since there are 5 colors) seems reasonable.
However, this count is underestimated by a factor of 2 because Bob has 2 choices, namely deciding which ball to give to Alice. The reward model is fooled by this error.

Although large language models have greatly improved in terms of complex reasoning capabilities, even the most advanced The model still produces logical errors or nonsense, which is often called "illusion".
In the craze of generative artificial intelligence, the illusion of large language models has always troubled people.
Musk said, what we need is TruthGPT
For example, recently, an American lawyer in a New York federal court filing It cited the fabricated case of ChatGPT and may face sanctions.
OpenAI researchers mentioned in the report: “These illusions are particularly problematic in fields that require multi-step reasoning, because a simple logic error can cause great damage to the entire solution. .”
Moreover, mitigating hallucinations is also the key to building consistent AGI.
How to reduce the illusion of large models? There are generally two methods - process supervision and result supervision.
"Result supervision", as the name suggests, is to give feedback to the large model based on the final results, while "process supervision" can provide feedback for each step in the thinking chain.

In process supervision, large models are rewarded for their correct reasoning steps, not just their correct final conclusions. This process will encourage the model to follow more human-like thinking method chains, thus making it more likely to create better explainable AI.
OpenAI researchers said that although process supervision was not invented by OpenAI, OpenAI is working hard to push it forward.
In the latest research, OpenAI tried both methods of "result supervision" or "process supervision". And using the MATH data set as a test platform, a detailed comparison of the two methods is conducted.
The results found that "process supervision" can significantly improve model performance.
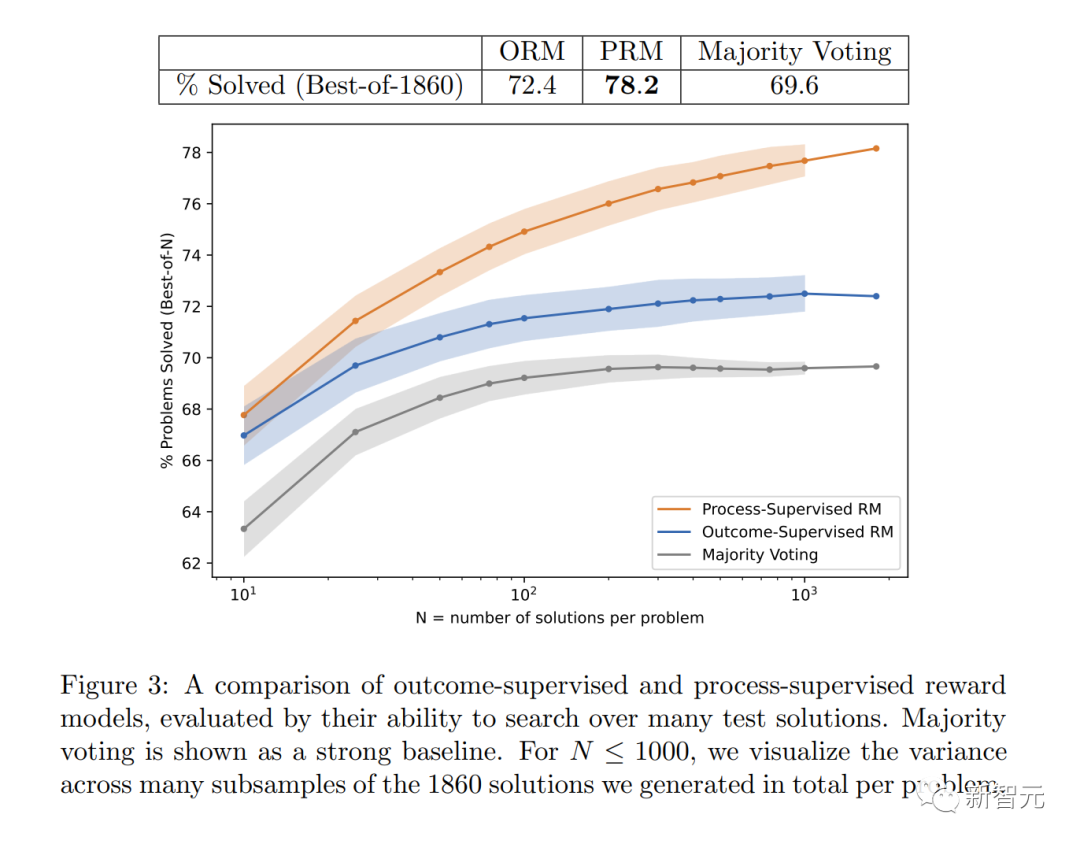
For mathematical tasks, Process Supervision produced significantly better results for both large and small models, meaning that the models were generally correct, and also exhibits a more human-like thought process.
In this way, illusions or logical errors that are difficult to avoid even in the most powerful models can be reduced.
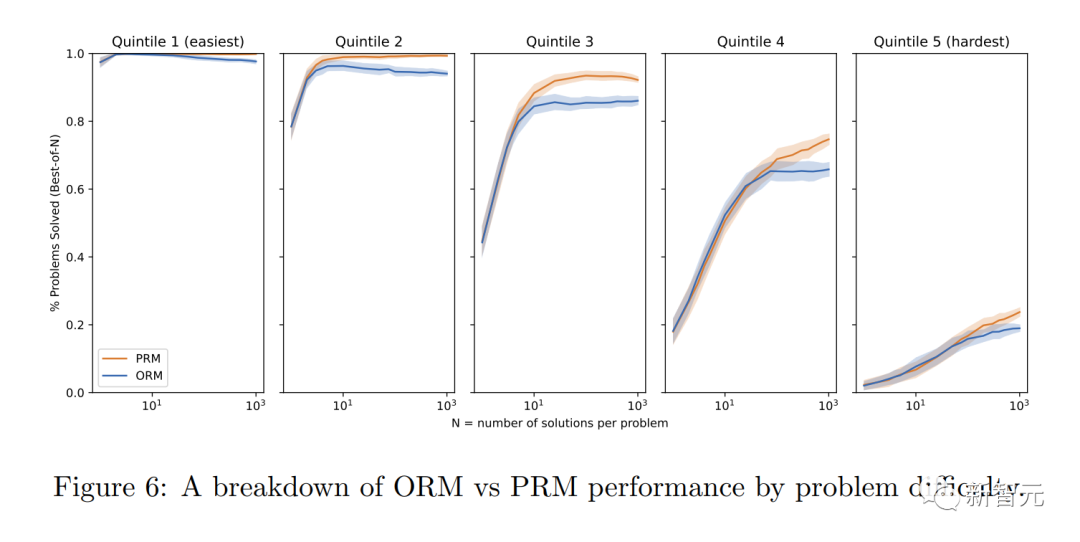
Researchers found that "process supervision" has several alignment advantages over "result supervision":
· Direct rewards follow a consistent thought chain model because each step in the process is precisely supervised.
· More likely to produce explainable reasoning because "process supervision" encourages models to follow human-approved processes. In contrast, outcomes monitoring may reward an inconsistent process and is often more difficult to review.
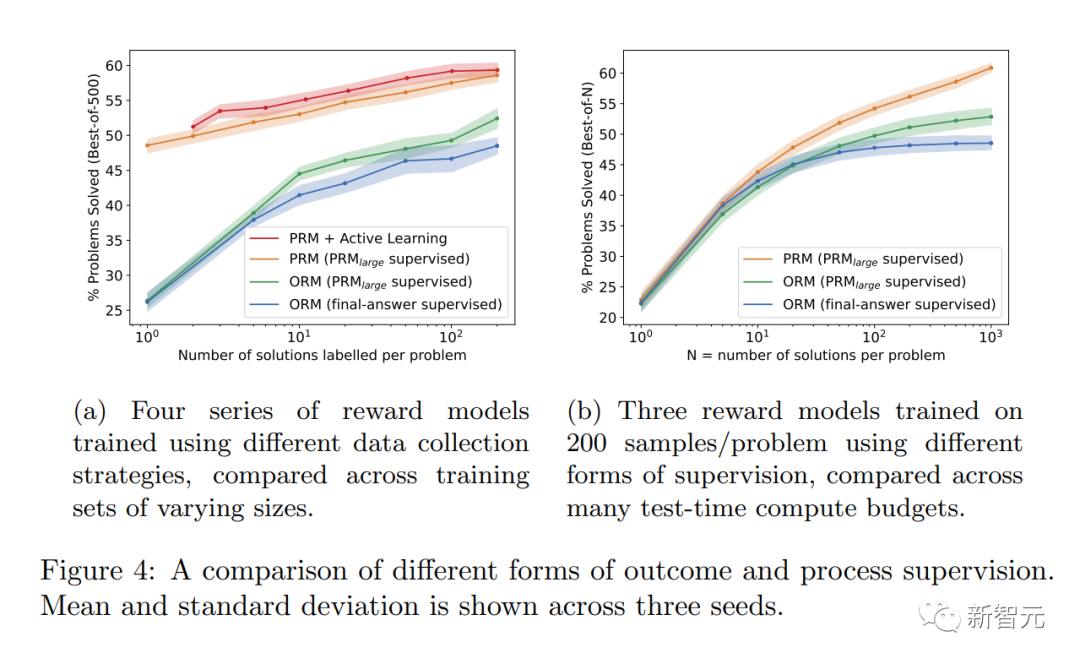
It’s also worth mentioning that in some cases, methods of making AI systems safer may result in performance degradation. This cost is called an "alignment tax."
Generally speaking, any "alignment tax" cost may hinder the adoption of alignment methods in order to deploy the most capable model.
However, the researchers’ results below show that “process supervision” actually produces a “negative alignment tax” during testing in the mathematics domain.
It can be said that there is no major performance loss due to alignment.
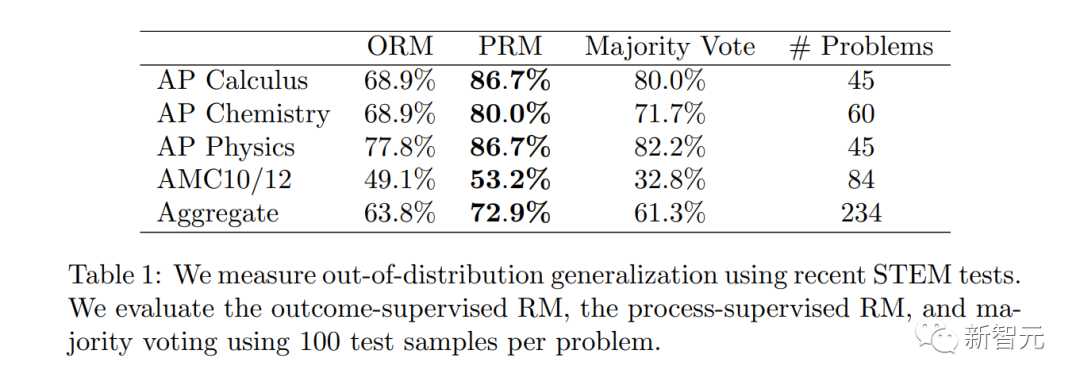
It is worth noting that PRM requires more human annotations, or deep I cannot live without RLHF.
How applicable is process supervision in fields other than mathematics? This process requires further exploration.
OpenAI researchers have opened up this human feedback data set PRM, which contains 800,000 step-level correct annotations: 75K solutions generated from 12K math problems

The following is an example of annotation. OpenAI is releasing the raw annotations, along with instructions to annotators during Phases 1 and 2 of the project.
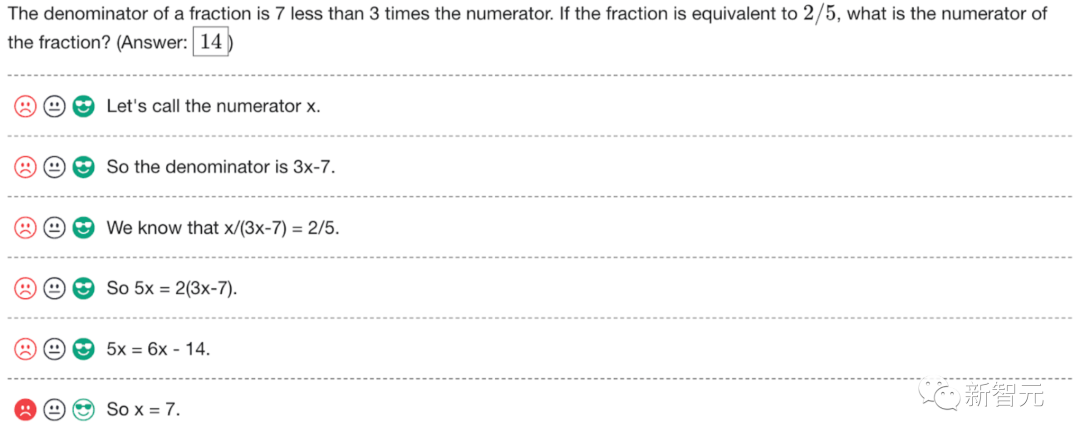
NVIDIA scientist Jim Fan made a summary of the latest research on OpenAI:
For Challenging step-by-step questions that give rewards at each step rather than a single reward at the end. Basically, dense reward signal > sparse reward signal. The Process Reward Model (PRM) can select solutions for difficult MATH benchmarks better than the Outcome Reward Model (ORM). The obvious next step is to fine-tune GPT-4 with PRM, which this article has not done yet. It should be noted that PRM requires more human annotation. OpenAI released a human feedback dataset: 800K step-level annotations on 75K solutions to 12K math problems.
##This is like an old saying often said in school, learn how to think .

##ChatGPT is super weak in math. Today I tried to solve a math problem from a 4th grade math book. ChatGPT gave the wrong answer. I checked my answers with answers from ChatGPT, answers from perplexity AI, Google, and my fourth grade teacher. It can be confirmed everywhere that chatgpt's answer is wrong.
 ## References:
## References:
The above is the detailed content of GPT-4 has great mathematical ability! OpenAI's explosive research on 'Process Supervision” breaks through 78.2% of the problems and eliminates hallucinations. For more information, please follow other related articles on the PHP Chinese website!
 What are the office software
What are the office software
 Introduction to the meaning of cloud download windows
Introduction to the meaning of cloud download windows
 What to do if temporary file rename fails
What to do if temporary file rename fails
 What to do if avast reports false positives
What to do if avast reports false positives
 The difference between get and post
The difference between get and post
 Telecom cdma
Telecom cdma
 What should I do if the CAD image cannot be moved?
What should I do if the CAD image cannot be moved?
 fakepath path solution
fakepath path solution
 Check if the port is open in linux
Check if the port is open in linux










![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



