

Another practical tool for group meetings with access to large model capabilities, now open for free public beta!
The big model behind it is Alibaba’s Tongyi Qianwen. As for why it is said to be a magical tool for group meetings -
Look, this is my instructor at Station B, Mr. Li Mu, who is leading the students to read a large model paper intensively.
Unfortunately at this moment, the boss urged me to move the bricks quickly. I had no choice but to silently take off my headphones, click on the plug-in called "Tongyi Listening", and then switch pages.
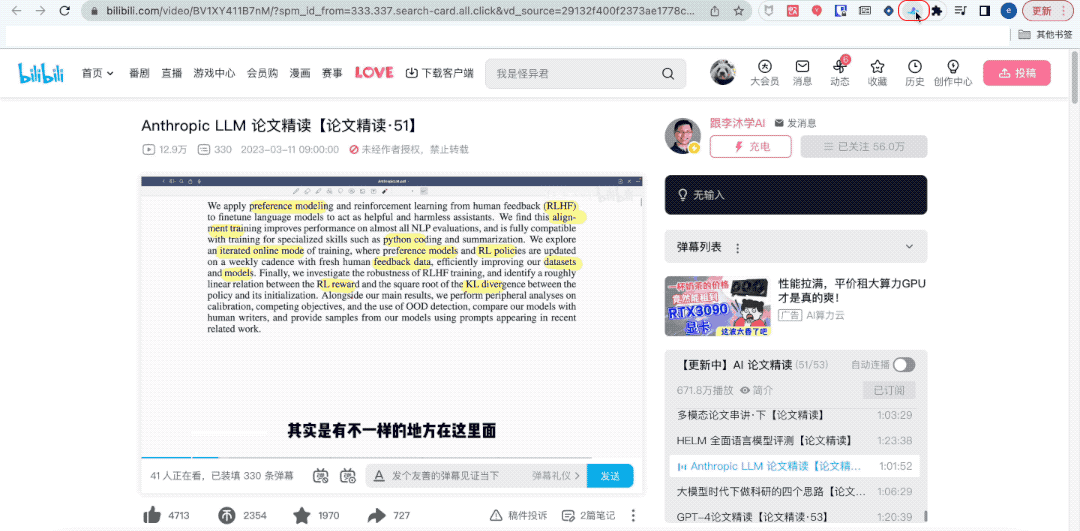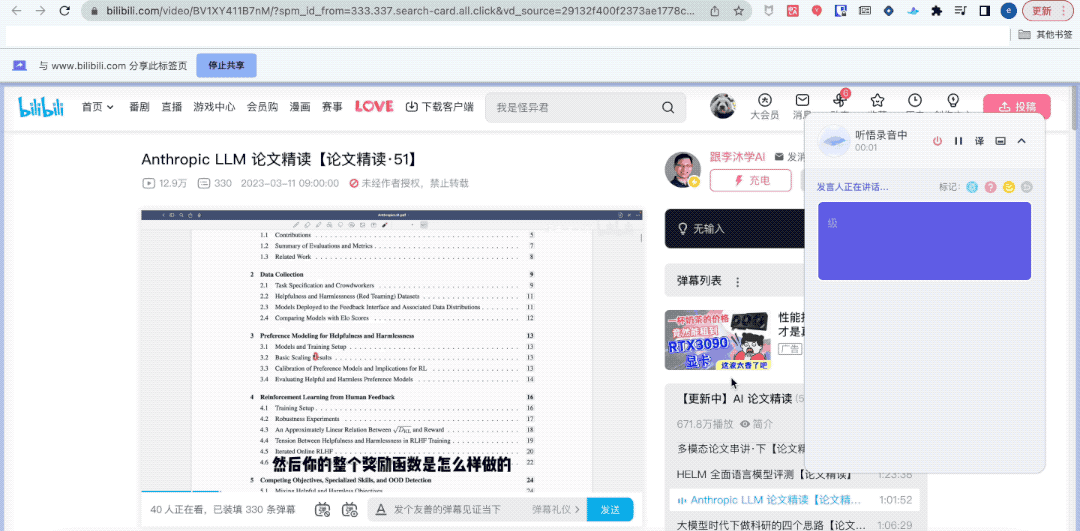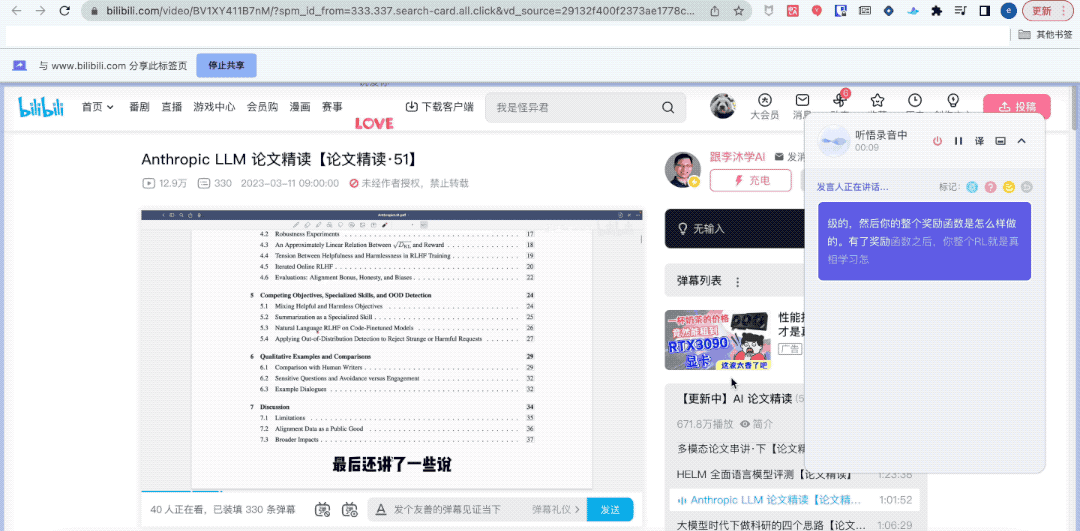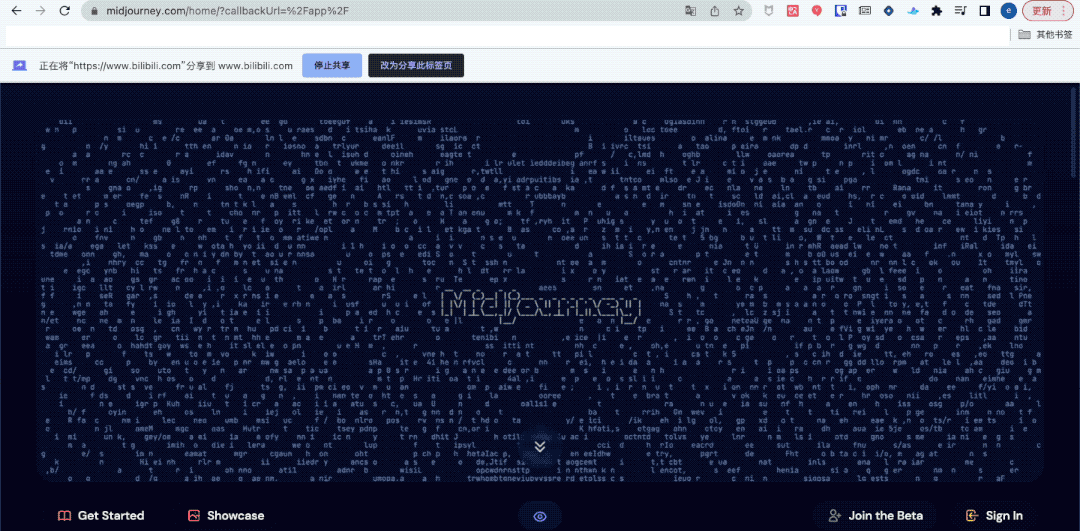
guess what? Although I was not at the "group meeting", Tingwu has helped me completely record the content of the group meeting.
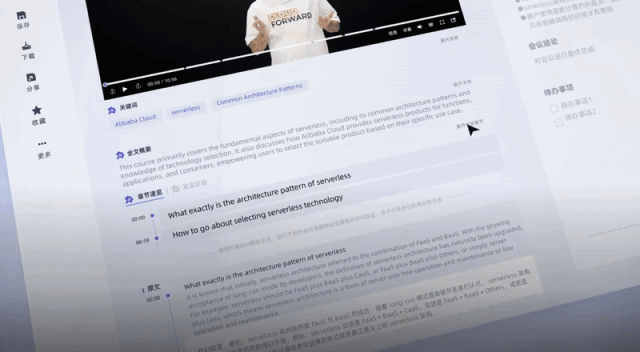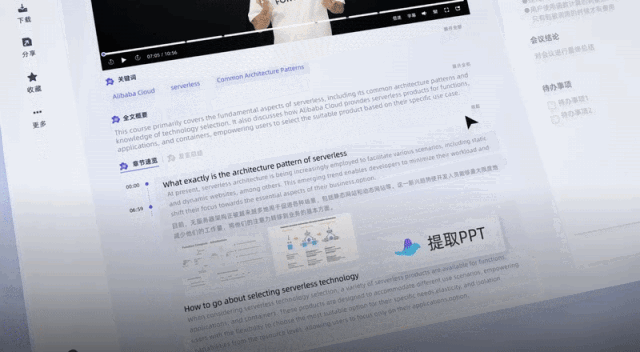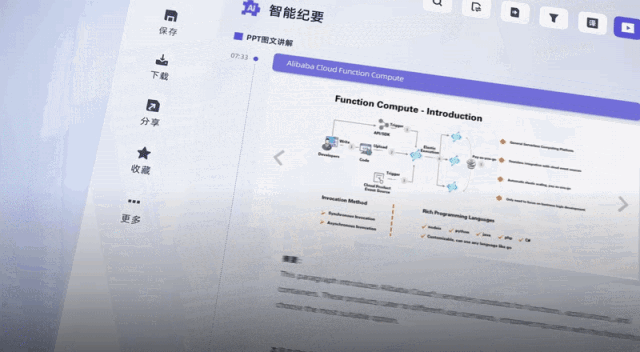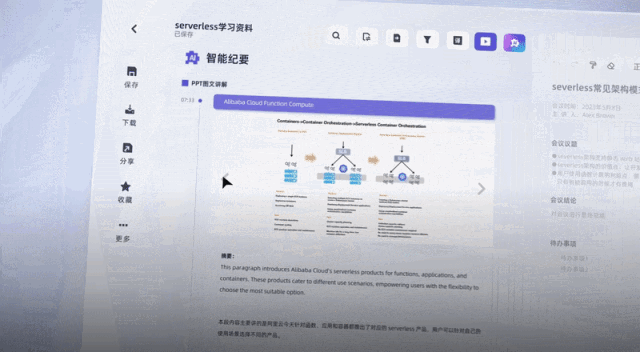
Even helped me summarize key words, full text summary and learning points with one click.

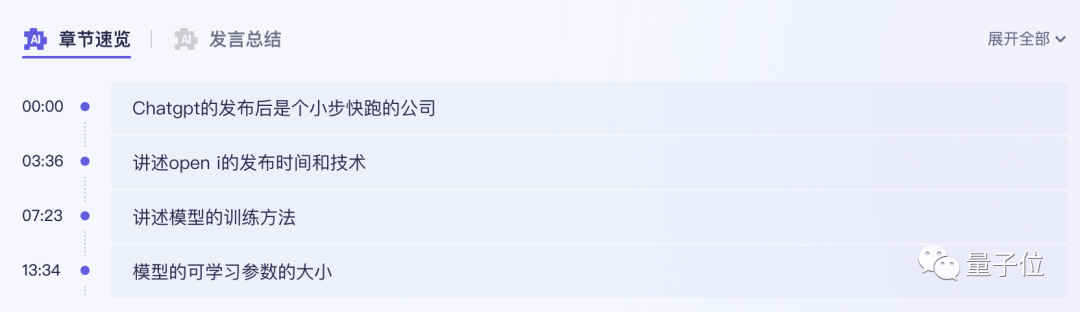
To put it simply, this "General Meaning Listening Comprehension" that has just been accessed to the large model ability is a large model version of Focus Work and study AI assistant for audio and video content.
Unlike previous recording transcription tools, it can not only convert recordings and videos into text. You can summarize the entire text with one click, and you can also summarize the views of different speakers:
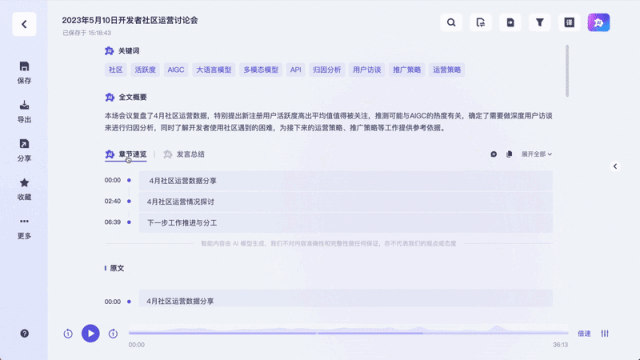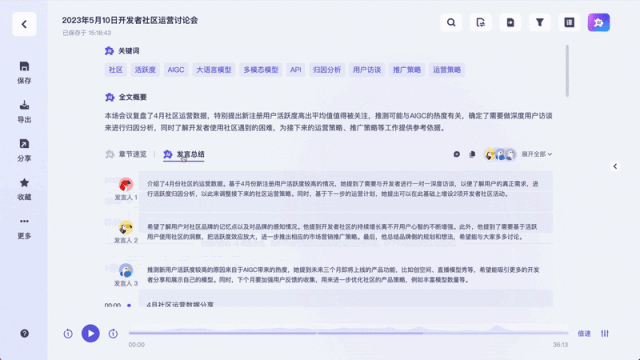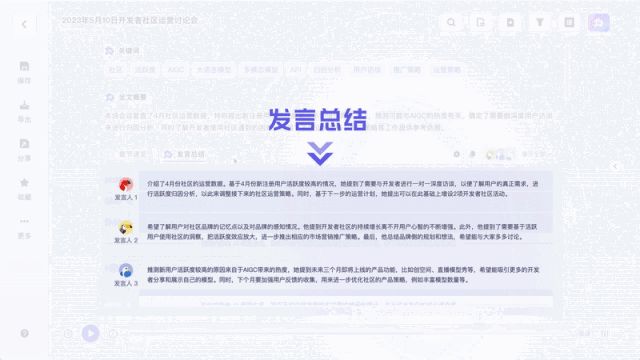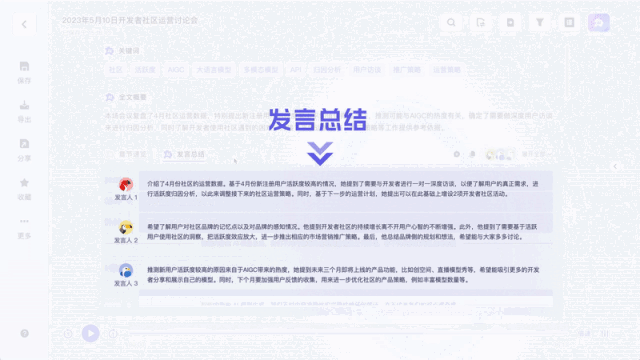
It can even be used as real-time subtitle translation:

It seems that it is not only useful for holding group meetings, but also a new artifact for daily work for qubits who often have to deal with a lot of recording, staying up late and various foreign conferences.
We quickly conducted an in-depth test.
The most basic and important thing about the organization and analysis of audio content is the accuracy of transcription.
Round 1, let’s first upload a Chinese video of about 10 minutes to see how Tingwu performs in terms of accuracy compared with similar tools.
Basically, AI processes this medium-length audio and video very quickly, and it can be transcribed in less than 2 minutes.

Let’s first take a look at the performance of Tingwu:

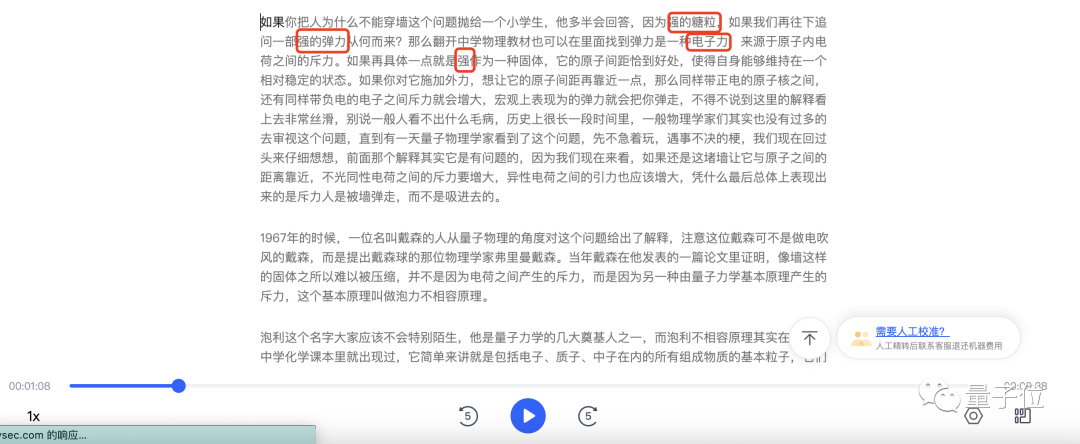
In this paragraph of about 200 words, Tingwu There were only two mistakes: strong → wall, both good → just right. Physical terms such as atomic nucleus, electric charge, and repulsion can be understood by listening.
We also tested it on Feishu Miaoji using the same video. The basic problem is not big, but compared to listening to Wu, Feishu made two more mistakes. One of the "atoms" was written as "garden", and "repulsion" was read as "power".

What’s interesting is that Feishu also replicated the mistakes Hengwu made one by one. It seems that this pot has to be shouldered by a certain up master who speaks and swallows words in Qubit (manual dog head).
iFlytek heard it, but it was able to distinguish the "just right" that the first two contestants did not recognize. But iFlytek basically translated all "wall" into "strong", and the magical combination of "strong sugar grains" appeared. In addition, among the three contestants, only iFlytek misunderstood "electromagnetic force" as "electronic force."
Generally speaking, Chinese recognition is not difficult for these AI tools. So how will they perform in the face of English materials?
We have uploaded a latest interview with Musk about his past disputes with OpenAI.
Let’s take a look at the results given by Tingwu first. In Musk's answers, except for Larry Page's name, Hua Wu basically correctly identified everyone else.
It is worth mentioning that Tingwu can directly translate the English transliteration results into Chinese and display bilingual comparisons. The translation quality is also quite good.
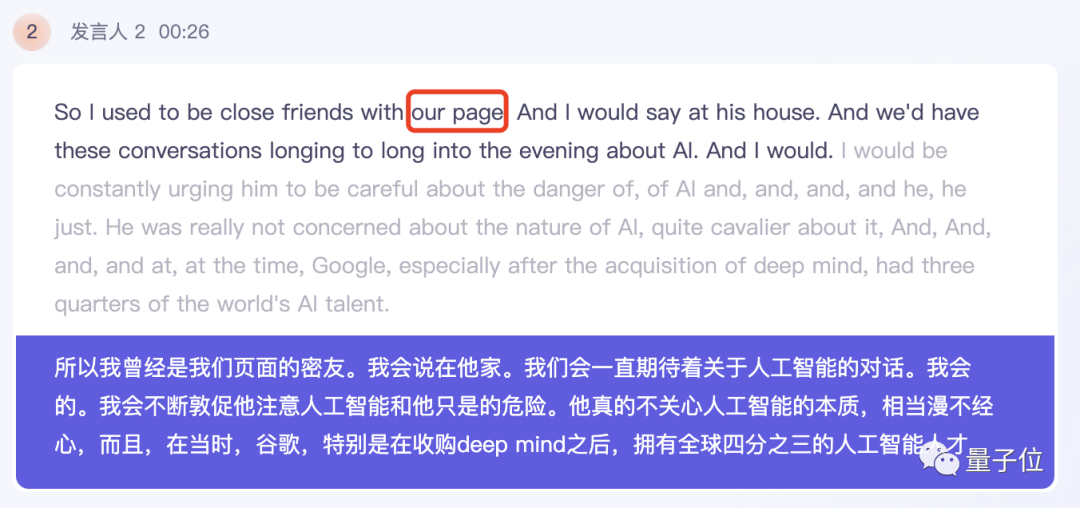
Feishu Miaoji successfully recognized Larry Page’s name, but like Listening, Musk’s overall speaking speed is faster and he has some colloquialisms. There are some minor errors in the expression, such as writing "stay at his house" instead of "say this house".

iFlytek heard here, the names and pronunciation details are handled well, but there are also cases of being misled by Musk's colloquial expressions, such as "long into" the evening" as "longing to the evening".

It seems that in terms of basic ability speech recognition, AI tools have reached a very high accuracy rate. In the face of extremely high efficiency, some small problems have been solved. Flaws do not cover up strengths.
Then, we will raise the difficulty level to Round 2 to test their ability to summarize videos that are about an hour long.
The test video is a 40-minute roundtable discussion with the theme of new opportunities for AIGC in China. A total of 5 people participated in the roundtable discussion.
On the listening side, it took less than 5 minutes in total from the completion of the transcription to the AI to extract keywords and provide a full text summary.
The result is Aunt Jiang’s:


Not only gives the keywords, but also summarizes the content of the roundtable discussion. It's very accurate, and it also divides the key points of the video.
Comparing the topic points excerpted by human editors, I smelled a hint of crisis...

It is worth mentioning that for the speeches of different guests, Listening to Wu Can provide corresponding summary of the speech.
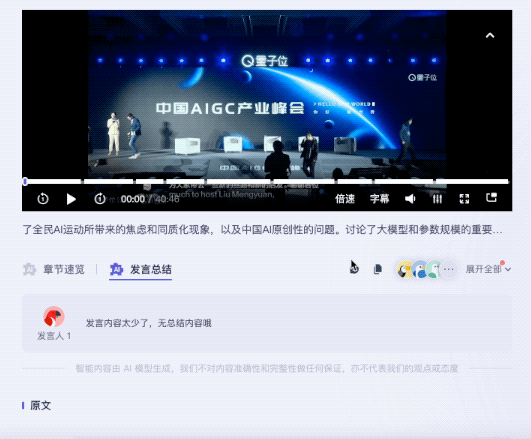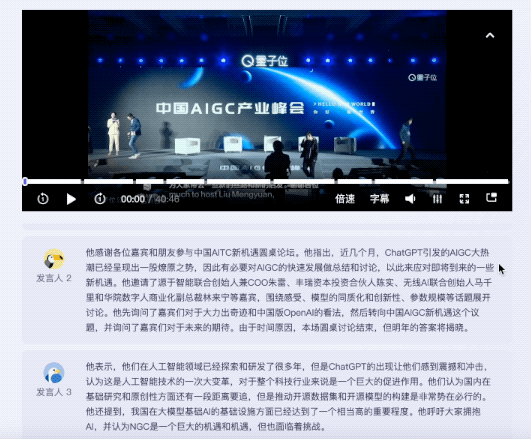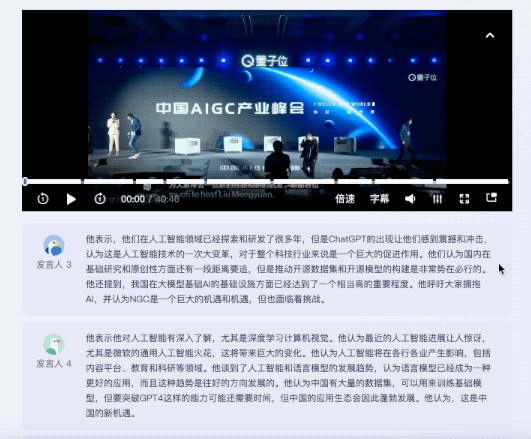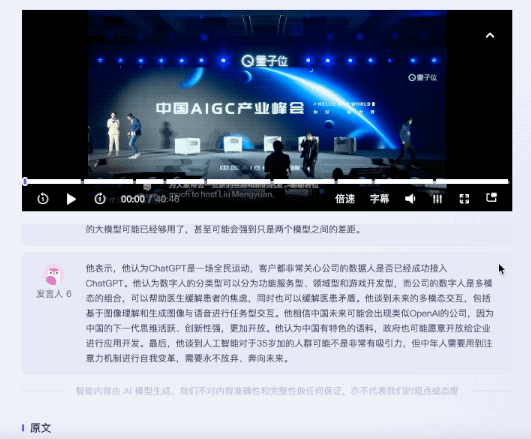
The same question was thrown to Feishu Miaoji. Currently, in terms of content summary, Feishu Miaoji can only provide keywords.

Meeting minutes need to be marked manually on the transcribed text.

#iFlytek heard that they are internally testing a product based on the Spark cognitive large model, which can analyze the content of files, but requires filling out an application and waiting in line. (Friends who are qualified for internal testing are welcome to share their experiences~)
In basic iFlytek, there is currently no similar summary function.

It seems that this round of testing:
However, in this actual test, the most surprising thing about Tongyi Tingwu is actually a "small" design:
Chrome plug-in function.
Whether you are watching English videos, watching live broadcasts, or attending meetings in class, you can achieve real-time transcription and translation of audio and video by clicking on the Listening plug-in.
As shown at the beginning, it can be used as real-time subtitles, with low latency, fast translation, and bilingual comparison function. At the same time, the recording and transcribed text can be saved with one click for subsequent use. .
Mom no longer has to worry about me not being able to chew down English video materials.
In addition, I have a bold idea...
Turn on listening when holding a group meeting, and you no longer have to worry about being suddenly checked by the instructor.
Currently, Tingwu has been connected with Alibaba Cloud Disk. Audio and video content stored in the cloud disk can be transcribed with one click, and subtitles can be automatically displayed when playing cloud disk videos online. AI-processed audio and video files can be quickly shared internally in the enterprise version in the future.

Tingwu officials also revealed that in the future, Tingwu will continue to add new large-scale model capabilities, such as directly extracting images from videos. PPT screenshots, you can directly ask AI questions about audio and video content...



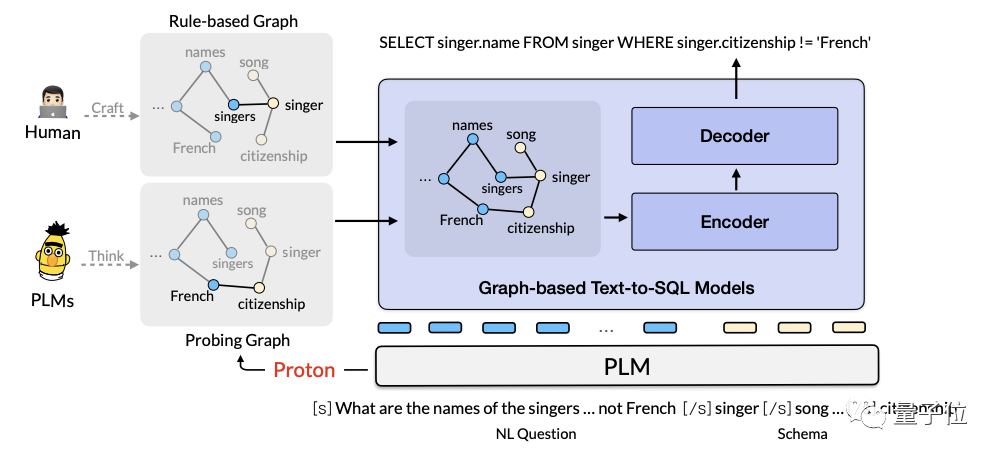
In addition, the R&D team behind Wu also released the Chinese ultra-large-scale document conversation data set Doc2Bot. The team's Re3G method to improve the model's question answering capabilities has been selected for ICASSP 2023: This method can improve the model's response to user questions through four stages: Retrieve (retrieval), Rerank (reranking), Refine (fine tuning) and Generate (generation). Its understanding, knowledge retrieval and reply generation capabilities ranked first in the two major document dialogue lists of Doc2Dial and Multi Doc2Dial.
In addition to large model capabilities, Tingwu is also the master of Alibaba’s voice technology.
The speech recognition model Paraformer behind it comes from Alibaba Damo Academy. It solves the problem of balancing end-to-end recognition effect and efficiency at the industrial level application level for the first time:
It not only improves reasoning efficiency It is 10 times better than the traditional model in terms of performance, and it also broke the records of many authoritative data sets when it was first launched, refreshing the SOTA accuracy rate of speech recognition. In the professional third-party full-network public cloud Chinese speech recognition evaluation SpeechIO TIOBE white box test, Paraformer-large is still the Chinese speech recognition model with the highest accuracy.
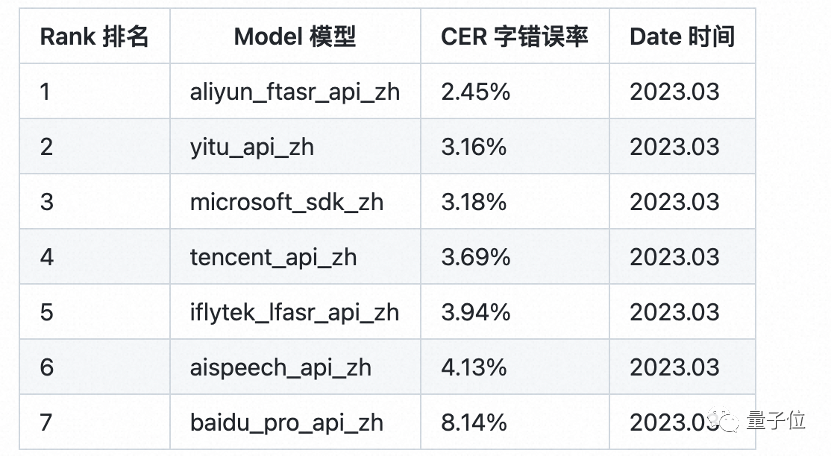
Paraformer is a single-round non-autoregressive model, consisting of five parts: encoder, predictor, sampler, decoder and loss function .
Through the innovative design of the predictor, Paraformer achieves accurate prediction of the number of target words and the corresponding acoustic latent variables.
In addition, the researchers also introduced the idea of browsing language model (GLM) in the field of machine translation, designed a sampler based on GLM, and enhanced the model's modeling of contextual semantics.
At the same time, Paraformer also used tens of thousands of hours of training on ultra-large-scale industrial data sets covering rich scenarios, further improving the recognition accuracy.
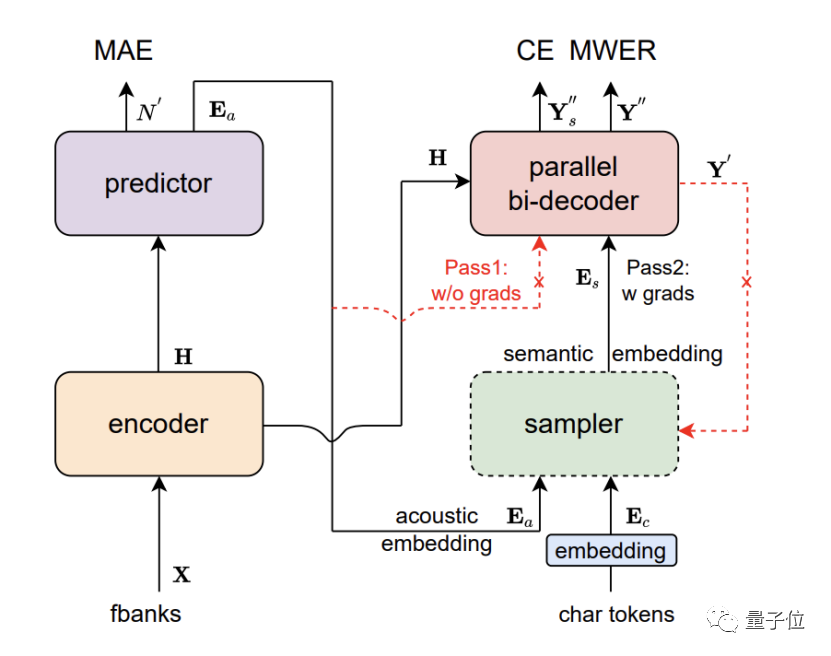
The accurate identification of speakers in multi-person discussions benefits from DAMO Academy’s CAM speaker recognition basic model. This model uses a delay network D-TDNN based on dense connections. The input of each layer is spliced from the output of all previous layers. This hierarchical feature multiplexing and one-dimensional convolution of the delay network can significantly improve Computational efficiency of the network.
On the industry's mainstream Chinese and English test sets VoxCeleb and CN-Celeb, CAM has refreshed the best accuracy.
According to the report of the China Institute of Scientific and Technological Information, according to incomplete statistics, currently domestic 79 large models were released.
Under this trend of large-scale model development, the speed of AI application evolution has once again entered a sprint stage.
From the user's perspective, a welcome situation is gradually taking shape:
Under the "coordination" of large models, various AI technologies have begun to flourish on the application side, making tools more and more popular. The more efficient and smarter it becomes.
From smart documents that can help you automatically write a work plan with a slash, to audio and video recording and analysis tools that quickly help you summarize elements, the spark of AGI, generative large models, is making more and more people More and more people are feeling the magic of AI.
At the same time, for technology companies, new challenges and new opportunities have undoubtedly emerged.
The challenge is that all products will be swept by the storm of large models, and technological innovation has become an unavoidable key issue.
The existing market structure has reached a moment of opportunity to rewrite it for new killer applications. Who can take the lead will depend on who is more technically prepared and whose technology evolves faster.
No matter what, the technical development will ultimately benefit users.
The above is the detailed content of Alibaba Cloud's new large model is released! AI artifact 'Tongyi Listening' is in public beta: long videos can be summarized in one second, and it can also automatically take notes and turn subtitles | Wool can be harvested. For more information, please follow other related articles on the PHP Chinese website!
 What are the registration-free spaces in China?
What are the registration-free spaces in China?
 Alibaba Cloud Computer Usage
Alibaba Cloud Computer Usage
 Regular expression tool
Regular expression tool
 How to solve the problem that laptop network sharing does not have permissions?
How to solve the problem that laptop network sharing does not have permissions?
 The role of parseint function
The role of parseint function
 How to turn off sublime auto-completion
How to turn off sublime auto-completion
 What are the inscribed coins?
What are the inscribed coins?
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



