

What is the internal implementation mechanism of Mysql lock?

Overview
Although modern relational databases are increasingly similar, they may have completely different mechanisms behind their implementation. In terms of actual use, because of the existence of SQL syntax specifications, it is not difficult for us to be familiar with multiple relational databases, but there may be as many lock implementation methods as there are databases.
Microsoft Sql Server only provided page locks before 2005. It was not until the 2005 version that it began to support optimistic concurrency and pessimistic concurrency. Optimistic mode allows row-level locks to be implemented. In the design of Sql Server, locks are a scarce resource. Locks The greater the number, the greater the overhead. In order to avoid a cliff-like drop in performance due to the rapid increase in the number of locks, it supports a mechanism called lock upgrade. Once the row lock is upgraded to a page lock, the concurrency performance will return to the original point. .
In fact, there are still many disputes about the interpretation of locking functions by different execution engines in the same database. MyISAM only supports table-level locking, which is fine for concurrent reading, but has certain limitations in concurrent modification. Innodb is very similar to Oracle, providing non-locking consistent reading and row lock support. The obvious difference from Sql Server is that as the total number of locks increases, Innodb only needs to pay a small price.
Row lock structure
Innodb supports row locks, and there is no particularly large overhead in describing the locks. Therefore, there is no need for a lock upgrade mechanism as a rescue measure after a large number of locks cause performance degradation.
Excerpted from the lock0priv.h file, Innodb defines row locks as follows:
/** Record lock for a page */
struct lock_rec_t {
/* space id */
ulint space;
/* page number */
ulint page_no;
/**
* number of bits in the lock bitmap;
* NOTE: the lock bitmap is placed immediately after the lock struct
*/
ulint n_bits;
};Although concurrency control can be refined at the row level, the lock management method is organized in units of pages. of. In the design of Innodb, the only data page can be determined through the two necessary conditions of space id and page number. n_bits indicates how many bits are needed to describe the row lock information of the page.
Each record in the same data page is assigned a unique continuous increasing sequence number: heap_no. If you want to know whether a certain row of records is locked, you only need to determine whether the number in the heap_no position of the bitmap is one. Since the lock bitmap allocates memory space based on the number of records in the data page, it is not explicitly defined, and the page records may continue to increase, so a space of LOCK_PAGE_BITMAP_MARGIN size is reserved.
/** * Safety margin when creating a new record lock: this many extra records * can be inserted to the page without need to create a lock with * a bigger bitmap */ #define LOCK_PAGE_BITMAP_MARGIN 64
Assume that the data page with space id = 20, page number = 100 currently has 160 records, and the records with heap_no of 2, 3, and 4 have been locked, then the corresponding lock_rec_t structure and data page should be like this Depiction:
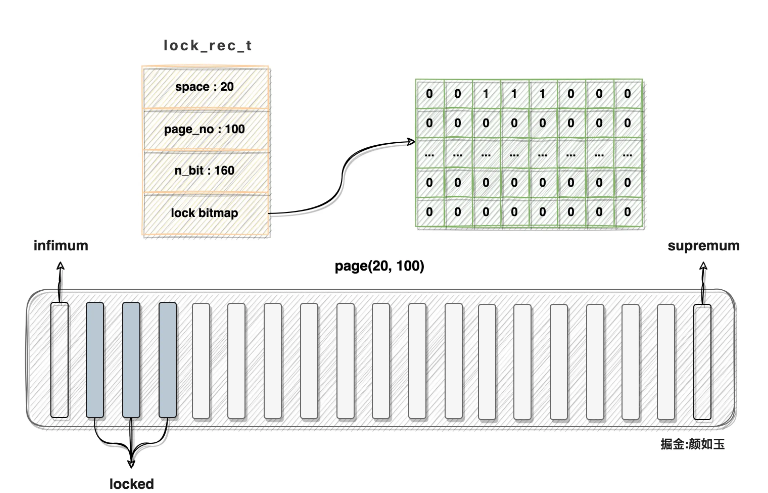
Note:
The lock bitmap in the memory should be linearly distributed. The two-dimensional structure shown in the figure is In order to facilitate the description
bitmap and lock_rec_t structures are a continuous memory, and the reference relationship in the figure is also required for drawing
You can see the corresponding page The second, third, and fourth positions of the bitmap are all set to 1. The memory consumed by describing a data page row lock is quite limited from the perspective of perception. How much does it occupy specifically? We can calculate:
160 / 8 8 1 = 29byte.
160 records correspond to 160bit
8 is because 64bit needs to be reserved
1 This is because 1 byte is reserved in the source code
In order to avoid the problem of small result values, an additional 1 is added here. This can avoid errors caused by integer division. If there are 161 records, if it is not 1, the calculated 20 bytes are not enough to describe the lock information of all records (without using reserved bits).
Excerpted from the lock0priv.h file:
/* lock_rec_create函数代码片段 */
n_bits = page_dir_get_n_heap(page) + LOCK_PAGE_BITMAP_MARGIN;
n_bytes = 1 + n_bits / 8;
/* 注意这里是分配的连续内存 */
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(lock_t) + n_bytes)
);
/**
* Gets the number of records in the heap.
* @return number of user records
*/
UNIV_INLINE ulint page_dir_get_n_heap(const page_t* page)
{
return(page_header_get_field(page, PAGE_N_HEAP) & 0x7fff);
}Table lock structure
Innodb also supports table locks. Table locks can be divided into two categories: intention locks and auto-increment locks. The data structure is defined as follows:
Extracted from the lock0priv.h file
struct lock_table_t {
/* database table in dictionary cache */
dict_table_t* table;
/* list of locks on the same table */
UT_LIST_NODE_T(lock_t) locks;
};Excerpted from the ut0lst.h file
struct ut_list_node {
/* pointer to the previous node, NULL if start of list */
TYPE* prev;
/* pointer to next node, NULL if end of list */
TYPE* next;
};
#define UT_LIST_NODE_T(TYPE) ut_list_node<TYPE>Description of locks in transactions
The above lock_rec_t, lock_table_t The structure is just a separate definition. The lock is generated in the transaction. Therefore, the row lock and table lock corresponding to each transaction will have a corresponding lock structure. Its definition is as follows:
Excerpted from the lock0priv.h file
/** Lock struct; protected by lock_sys->mutex */
struct lock_t {
/* transaction owning the lock */
trx_t* trx;
/* list of the locks of the transaction */
UT_LIST_NODE_T(lock_t) trx_locks;
/**
* lock type, mode, LOCK_GAP or LOCK_REC_NOT_GAP,
* LOCK_INSERT_INTENTION, wait flag, ORed
*/
ulint type_mode;
/* hash chain node for a record lock */
hash_node_t hash;
/*!< index for a record lock */
dict_index_t* index;
/* lock details */
union {
/* table lock */
lock_table_t tab_lock;
/* record lock */
lock_rec_t rec_lock;
} un_member;
};lock_t is defined based on each page (or table) of each transaction, but a transaction often involves multiple pages, so the linked list trx_locks is needed to concatenate all the lock information related to a transaction. In addition to querying all lock information based on transactions, the actual scenario also requires that the system must be able to quickly and efficiently detect whether a row record has been locked. Therefore, there must be a global variable to support querying lock information for row records. Innodb chose the hash table, which is defined as follows:
Extracted from the lock0lock.h file
/** The lock system struct */
struct lock_sys_t {
/* Mutex protecting the locks */
ib_mutex_t mutex;
/* 就是这里: hash table of the record locks */
hash_table_t* rec_hash;
/* Mutex protecting the next two fields */
ib_mutex_t wait_mutex;
/**
* Array of user threads suspended while waiting forlocks within InnoDB,
* protected by the lock_sys->wait_mutex
*/
srv_slot_t* waiting_threads;
/*
* highest slot ever used in the waiting_threads array,
* protected by lock_sys->wait_mutex
*/
srv_slot_t* last_slot;
/**
* TRUE if rollback of all recovered transactions is complete.
* Protected by lock_sys->mutex
*/
ibool rollback_complete;
/* Max wait time */
ulint n_lock_max_wait_time;
/**
* Set to the event that is created in the lock wait monitor thread.
* A value of 0 means the thread is not active
*/
os_event_t timeout_event;
/* True if the timeout thread is running */
bool timeout_thread_active;
};The function lock_sys_create is responsible for initializing the lock_sys_t structure when the database starts. The srv_lock_table_size variable determines the size of the number of hash slots in rec_hash. The key value of the rec_hash hash table is computed by using the space id and page number of the page..
Excerpted from lock0lock.ic, ut0rnd.ic files
/**
* Calculates the fold value of a page file address: used in inserting or
* searching for a lock in the hash table.
*
* @return folded value
*/
UNIV_INLINE ulint lock_rec_fold(ulint space, ulint page_no)
{
return(ut_fold_ulint_pair(space, page_no));
}
/**
* Folds a pair of ulints.
*
* @return folded value
*/
UNIV_INLINE ulint ut_fold_ulint_pair(ulint n1, ulint n2)
{
return (
(
(((n1 ^ n2 ^ UT_HASH_RANDOM_MASK2) << 8) + n1)
^ UT_HASH_RANDOM_MASK
)
+ n2
);
}This will mean that there is no way to provide a way for us to directly know whether a certain row is locked. Instead, you should first obtain the space id and page number through the page where it is located, obtain the key value through the lock_rec_fold function, and then obtain lock_rec_t through hash query, and then scan the bit map according to heap_no to finally determine the lock information. The lock_rec_get_first function implements the above logic:
这里返回的其实是lock_t对象,摘自lock0lock.cc文件
/**
* Gets the first explicit lock request on a record.
*
* @param block : block containing the record
* @param heap_no : heap number of the record
*
* @return first lock, NULL if none exists
*/
UNIV_INLINE lock_t* lock_rec_get_first(const buf_block_t* block, ulint heap_no)
{
lock_t* lock;
ut_ad(lock_mutex_own());
for (lock = lock_rec_get_first_on_page(block); lock;
lock = lock_rec_get_next_on_page(lock)
) {
if (lock_rec_get_nth_bit(lock, heap_no)) {
break;
}
}
return(lock);
}以页面为粒度进行锁维护并非最直接有效的方式,它明显是时间换空间,不过这种设计使得锁开销很小。某一事务对任一行上锁的开销都是一样的,锁数量的上升也不会带来额外的内存消耗。
对应每个事务的内存对象trx_t中,包含了该事务的锁信息链表和等待的锁信息。因此存在如下两种途径对锁进行查询:
根据事务: 通过trx_t对象的trx_locks链表,再通过lock_t对象中的trx_locks遍历可得某事务持有、等待的所有锁信息。
根据记录: 根据记录所在的页,通过space id、page number在lock_sys_t结构中定位到lock_t对象,扫描bitmap找到heap_no对应的bit位。
上述各种数据结构,对其整理关系如下图所示:
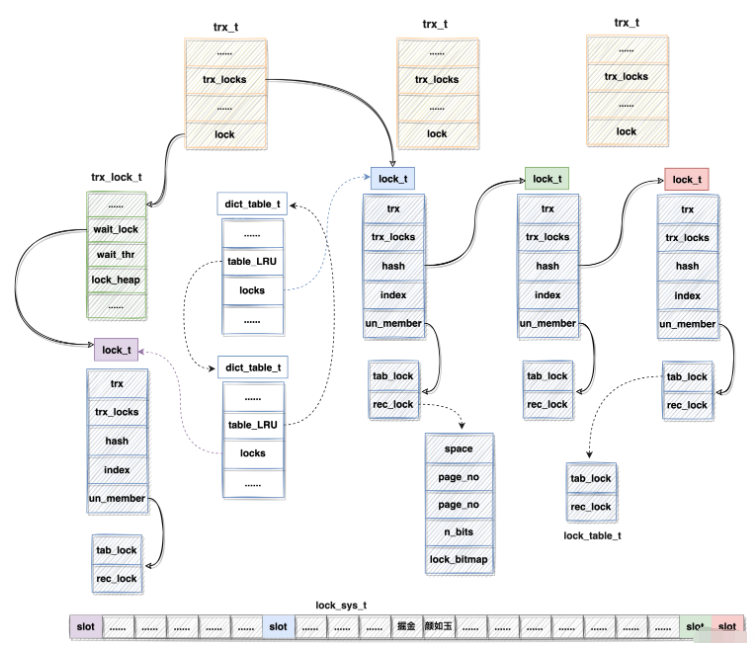
注:
lock_sys_t中的slot颜色与lock_t颜色相同则表明lock_sys_t slot持有lock_t 指针信息,实在是没法连线,不然图很混乱
The above is the detailed content of What is the internal implementation mechanism of Mysql lock?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
