
 Technology peripherals
AI
Identifying 'ChatGPT fraud', the effect surpasses OpenAI: Peking University and Huawei's AI-generated detectors are here
Technology peripherals
AI
Identifying 'ChatGPT fraud', the effect surpasses OpenAI: Peking University and Huawei's AI-generated detectors are here
Identifying 'ChatGPT fraud', the effect surpasses OpenAI: Peking University and Huawei's AI-generated detectors are here

With the continuous advancement of large generative models, the corpus they generate is gradually approaching that of humans. Although large models are liberating the hands of countless clerks, their powerful ability to fake real things has also been used by some criminals, causing a series of social problems:



#From Peking University, Huawei Researchers have proposed a reliable text detector for identifying various AI-generated corpora. According to the different characteristics of long and short texts, a multi-scale AI-generated text detector training method based on PU learning is proposed. By improving the detector training process, considerable improvements in detection capabilities on long and short ChatGPT corpus can be achieved under the same conditions, solving the pain point of low accuracy of short text recognition by current detectors.
- Paper address: https://arxiv.org/abs/2305.18149
- Code address (MindSpore): https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
- Code address (PyTorch) :https://github.com/YuchuanTian/AIGC_text_detector ##Introduction
Regarding the different detection effects of corpus of different lengths, the author observed that there may be some "uncertainty" in the attribution of shorter AI-generated texts; or to put it more bluntly, due to Some short sentences generated by AI are also often used by humans, so it is difficult to determine whether the short text generated by AI comes from humans or AI. Here are several examples of people and AI answering the same question respectively:

To address this problem, this study transforms the human/AI binary classification detection part into a partial PU (Positive-Unlabeled) learning problem, that is, in shorter sentences, human The language is a positive class (Positive) and the machine language is an unlabeled class (Unlabeled), thereby improving the training loss function. This improvement significantly improves the detector's classification performance on various corpora.
Algorithm details
Under the traditional PU learning setting, a two-classification model can only learn based on positive training samples and unlabeled training samples. A commonly used PU learning method is to estimate the binary classification loss corresponding to negative samples by formulating PU loss:
Among them, 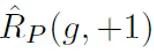 represents the binary classification loss calculated by positive samples and positive labels;
represents the binary classification loss calculated by positive samples and positive labels; 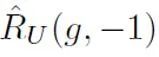 represents the loss calculated by assuming that all unlabeled samples are negative labels. Binary classification loss;
represents the loss calculated by assuming that all unlabeled samples are negative labels. Binary classification loss; 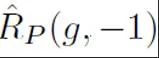 represents the binary classification loss calculated assuming that the positive sample is a negative label;
represents the binary classification loss calculated assuming that the positive sample is a negative label; 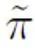 represents the prior positive sample probability, that is, the positive sample is in all Estimated share of PU sample. In traditional PU learning, the prior is usually set to a fixed hyperparameter. However, in the text detection scenario, the detector needs to process various texts of different lengths; and for texts of different lengths, the estimated proportion of positive samples among all PU samples of the same length as the sample is also different. . Therefore, this study improves PU Loss and proposes a length-sensitive multi-scale PU (MPU) loss function.
represents the prior positive sample probability, that is, the positive sample is in all Estimated share of PU sample. In traditional PU learning, the prior is usually set to a fixed hyperparameter. However, in the text detection scenario, the detector needs to process various texts of different lengths; and for texts of different lengths, the estimated proportion of positive samples among all PU samples of the same length as the sample is also different. . Therefore, this study improves PU Loss and proposes a length-sensitive multi-scale PU (MPU) loss function.
Specifically, this study proposes an abstract cycle model to model shorter text detection. When traditional NLP models process sequences, they usually have a Markov chain structure, such as RNN, LSTM, etc. The process of this type of cyclic model can usually be understood as a gradual iterative process, that is, the prediction of each token output is obtained by transforming and merging the prediction results of the previous token and the previous sequence with the prediction results of this token. That is, the following process:
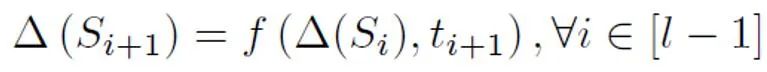
In order to estimate the prior probability based on this abstract model, it is necessary to assume that the output of the model is that a certain sentence is positive. The confidence of the class (Positive) is the probability that the sample is judged to be spoken by a person. It is assumed that the contribution size of each token is the inverse proportion of the length of the sentence token, it is positive, that is, unlabeled, and the probability of being unlabeled is much greater than the probability of being positive. Because as the vocabulary of large models gradually approaches that of humans, most words will appear in both AI and human corpora. Based on this simplified model and the set positive token probability, the final prior estimate is obtained by finding the total expectation of the model output confidence under different input conditions.
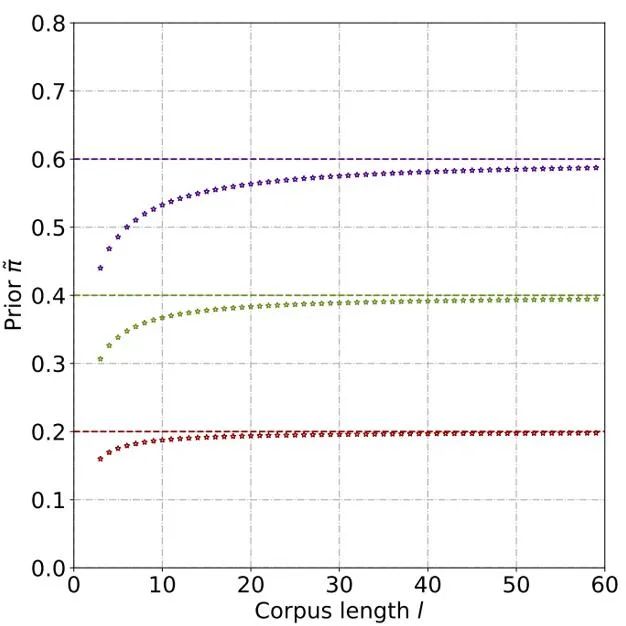
Through theoretical derivation and experiments, it is estimated that the prior probability increases as the length of the text increases, and eventually stabilizes . This phenomenon is also expected, because as the text becomes longer, the detector can capture more information, and the "source uncertainty" of the text gradually weakens:
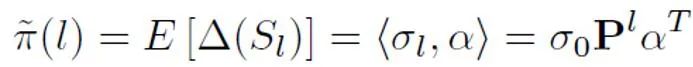
After that, for each positive sample, the PU loss is calculated based on the unique prior obtained from its sample length. Finally, since shorter texts only have some "uncertainty" (that is, shorter texts will also contain text features of some people or AI), the binary loss and MPU loss can be weighted and added as the final optimization goal:
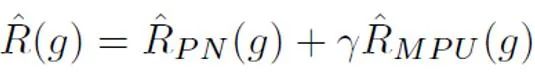
In addition, it should be noted that MPU loss adapts to training corpus of various lengths. If the existing training data is obviously homogeneous and most of the corpus consists of long and lengthy texts, the MPU method cannot fully exert its effectiveness. In order to make the length of the training corpus more diverse, this study also introduces a multi-scaling module at the sentence level. This module randomly covers some sentences in the training corpus and reorganizes the remaining sentences while retaining the original order. After multi-scale operation of the training corpus, the training text has been greatly enriched in length, thus making full use of PU learning for AI text detector training.
Experimental results

#As shown in the table above, the author first tested it on the shorter AI-generated corpus data set Tweep-Fake The effect of MPU loss. The corpus in this data set is all relatively short segments on Twitter. The author also replaces the traditional two-category loss with an optimization goal containing MPU loss based on traditional language model fine-tuning. The improved language model detector is more effective and surpasses other baseline algorithms.
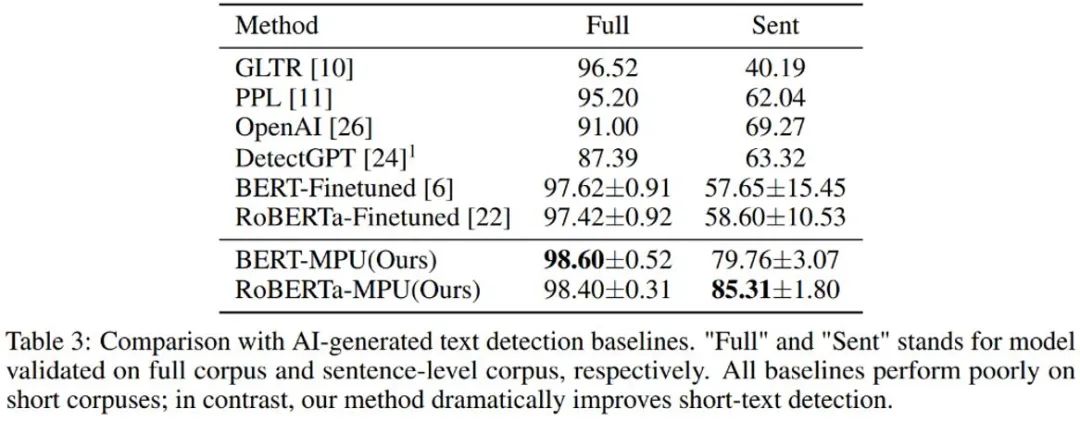
The author also tested the text generated by chatGPT. The language model detector obtained after traditional fine-tuning is better on short sentences. The performance is poor; the detector trained by MPU method under the same conditions performs well on short sentences, and at the same time can achieve considerable effect improvement on the complete corpus. The F1-score is increased by 1%, surpassing OpenAI and DetectGPT. SOTA algorithm.
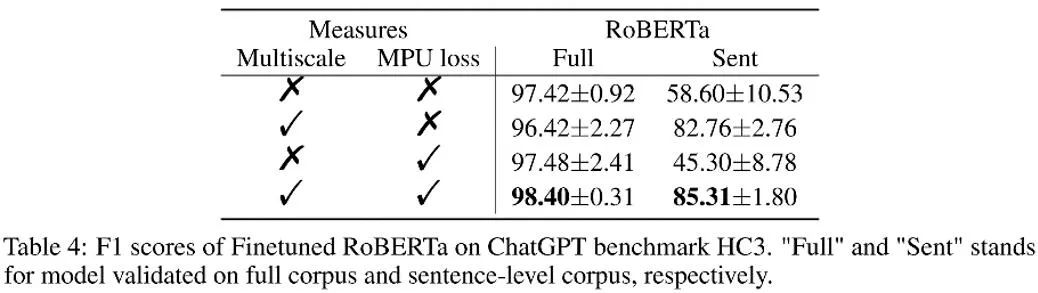
As shown in the table above, the author observed the effect gain brought by each part in the ablation experiment. MPU loss enhances the classification effect of long and short materials.

The author also compared traditional PU and Multiscale PU (MPU). It can be seen from the above table that the MPU effect is better and can better adapt to the task of AI multi-scale text detection.
Summary
The author solved the problem of short sentence recognition by text detector by proposing a solution based on multi-scale PU learning. With the proliferation of AIGC generation models in the future , the detection of this type of content will become increasingly important. This research has taken a solid step forward in the issue of AI text detection. It is hoped that there will be more similar research in the future to better control AIGC content and prevent the abuse of AI-generated content.
The above is the detailed content of Identifying 'ChatGPT fraud', the effect surpasses OpenAI: Peking University and Huawei's AI-generated detectors are here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
How to solve SQL parsing problem? Use greenlion/php-sql-parser!
Apr 17, 2025 pm 09:15 PM
When developing a project that requires parsing SQL statements, I encountered a tricky problem: how to efficiently parse MySQL's SQL statements and extract the key information. After trying many methods, I found that the greenlion/php-sql-parser library can perfectly solve my needs.
 How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
How to solve complex BelongsToThrough relationship problem in Laravel? Use Composer!
Apr 17, 2025 pm 09:54 PM
In Laravel development, dealing with complex model relationships has always been a challenge, especially when it comes to multi-level BelongsToThrough relationships. Recently, I encountered this problem in a project dealing with a multi-level model relationship, where traditional HasManyThrough relationships fail to meet the needs, resulting in data queries becoming complex and inefficient. After some exploration, I found the library staudenmeir/belongs-to-through, which easily installed and solved my troubles through Composer.
 Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
Solve CSS prefix problem using Composer: Practice of padaliyajay/php-autoprefixer library
Apr 17, 2025 pm 11:27 PM
I'm having a tricky problem when developing a front-end project: I need to manually add a browser prefix to the CSS properties to ensure compatibility. This is not only time consuming, but also error-prone. After some exploration, I discovered the padaliyajay/php-autoprefixer library, which easily solved my troubles with Composer.
 How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
How to solve the problem of PHP project code coverage reporting? Using php-coveralls is OK!
Apr 17, 2025 pm 08:03 PM
When developing PHP projects, ensuring code coverage is an important part of ensuring code quality. However, when I was using TravisCI for continuous integration, I encountered a problem: the test coverage report was not uploaded to the Coveralls platform, resulting in the inability to monitor and improve code coverage. After some exploration, I found the tool php-coveralls, which not only solved my problem, but also greatly simplified the configuration process.
 How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
How to solve the complex problem of PHP geodata processing? Use Composer and GeoPHP!
Apr 17, 2025 pm 08:30 PM
When developing a Geographic Information System (GIS), I encountered a difficult problem: how to efficiently handle various geographic data formats such as WKT, WKB, GeoJSON, etc. in PHP. I've tried multiple methods, but none of them can effectively solve the conversion and operational issues between these formats. Finally, I found the GeoPHP library, which easily integrates through Composer, and it completely solved my troubles.
 git software installation tutorial
Apr 17, 2025 pm 12:06 PM
git software installation tutorial
Apr 17, 2025 pm 12:06 PM
Git Software Installation Guide: Visit the official Git website to download the installer for Windows, MacOS, or Linux. Run the installer and follow the prompts. Configure Git: Set username, email, and select a text editor. For Windows users, configure the Git Bash environment.
 The latest tutorial on how to read the key of git software
Apr 17, 2025 pm 12:12 PM
The latest tutorial on how to read the key of git software
Apr 17, 2025 pm 12:12 PM
This article will explain in detail how to view keys in Git software. It is crucial to master this because Git keys are secure credentials for authentication and secure transfer of code. The article will guide readers step by step how to display and manage their Git keys, including SSH and GPG keys, using different commands and options. By following the steps in this guide, users can easily ensure their Git repository is secure and collaboratively smoothly with others.
