

What are the methods of using Redis integer collection?

1. Overview of Collections
For collections, I believe everyone is familiar with STL’s set. Its underlying implementation is a red-black tree. Regardless of insertion, deletion, or search, the time complexity is O(log n). Of course, if a hash table is used to implement a collection, insertion, deletion, and search can all reach O(1). So why does the collection use red-black trees and not hash tables? I think the biggest possibility is based on the characteristics of the set itself. The set has its own unique operations: intersection, union, and difference. All three operations are O(n) for hash tables. Compared to an unordered hash table, it is more appropriate to use an ordered red-black tree, because this is important.
2. Redis integer set (intset)
The integer set we are going to talk about today, also called intset, is a unique data structure of Redis. Its implementation is neither a red-black tree nor a hash table. It's a simple array plus memory encoding. Integer sets are only used when there are few stored elements (the upper limit of the number of elements is defined in the OBJ_SET_MAX_INTSET_ENTRIES macro definition value of server.h is 512) and they are all integers. Its search is O(log n), and insertion and deletion are both O(n). However, when there are relatively few storage elements, the difference between O(log n) and O(n) is not very big. However, using the integer collection of Redis can greatly reduce the memory compared to red-black trees and hash tables. .
Therefore, the existence of Redis's integer set intset is mainly to save memory.
1. Intset structure definition
The intset structure is defined in intset.h:
#define INTSET_ENC_INT16 (sizeof(int16_t))
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
typedef struct intset {
uint32_t encoding; /* a */
uint32_t length; /* b */
int8_t contents[]; /* c */
} intset; a) encoding specifies the encoding method, there are three types: INTSET_ENC_INT16, INTSET_ENC_INT32, and INTSET_ENC_INT64 . As can be seen from the macro definition, these three values are 2, 4, and 8 respectively. From the literal meaning, it can be seen that the range that the three can represent is 16-bit integer, 32-bit integer and 64-bit integer.
b) length stores the number of elements of the integer collection.
c) contents is a flexible array of integer collections, and the element type is not necessarily int8_t type. contents does not occupy the size of the structure, it only serves as the first pointer of the integer collection data. The elements in the integer collection are arranged in contents in ascending order.
2. Encoding method
First, let’s understand the meaning of encoding method. One thing that needs to be made clear is that for a set of integers, the encoding of all elements must be consistent (otherwise each number has to store a code instead of storing it in the intset structure), then the encoding of the entire set of integers Depends on the number in the set with the largest "absolute value" (the reason why it is an absolute value is that integers contain positive and negative numbers).
Get the encoding through the integer with the largest absolute value. The implementation is as follows:
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
} The meaning of this code is that if the integer v cannot be represented by a 32-bit integer, then you need to use INTSET_ENC_INT64 encoding; if not If it is represented by a 16-bit integer, then you need to use INTSET_ENC_INT32 encoding; otherwise, just use INTSET_ENC_INT16 encoding. The core is: if you can use 2 bytes to express it, you don’t need 4 bytes; if you can use 4 bytes to express it, you don’t need 8 bytes. Save what you can.
Several macros are defined in stdint.h, as follows:
/* Minimum of signed integral types. */ # define INT16_MIN (-32767-1) # define INT32_MIN (-2147483647-1) /* Maximum of signed integral types. */ # define INT16_MAX (32767) # define INT32_MAX (2147483647)
3. Encoding upgrade
When the current encoding method is not enough to store integers with larger digits, the encoding needs to be upgraded. For example, the four numbers shown in the figure below are all in the range [-32768, 32767], so INTSET_ENC_INT16 encoding can be used. The array length of contents is sizeof(int16_t) * 4 = 2 * 4 = 8 bytes (that is, 64 binary bits).
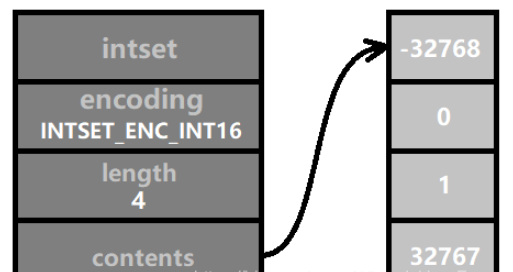
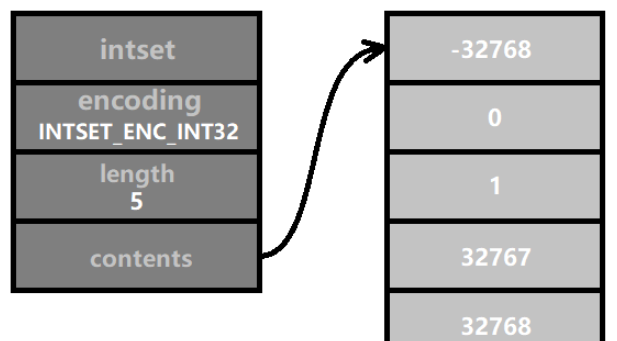
It would be great if we encode all integer sets with INTSET_ENC_INT64 from the beginning, and save trouble. The reason is that the original intention of Redis designing intset is to save memory. It is assumed that the elements of a set will never exceed 16-bit integers. Then using 64-bit integers is equivalent to wasting 3 times the memory.
三、整数集合常用操作
1、创建集合
创建一个整数集合 intsetNew,实现在 intset.c 中:
intset *intsetNew(void) {
intset *is = zmalloc(sizeof(intset));
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
} 初始创建的整数集合为空集合,用 zmalloc 进行内存分配后,定义编码为 INTSET_ENC_INT16,这样可以使内存尽量小。这里需要注意的是,intset 的存储直接涉及到内存编码,所以需要考虑主机的字节序问题(相关资料请参阅:字节序)。
intrev32ifbe 的意思是 int32 reversal if big endian。即 如果当前主机字节序为大端序,那么将它的内存存储进行翻转操作。简言之,intset 的所有成员存储方式都采用小端序。所以创建一个空的整数集合,内存分布如下:

了解了整数集合的内存编码以后,我们来看看它的 设置 (set)和 获取(get)。
2、元素设置
设置 的含义就是给定整数集合以及一个位置和值,将值设置到这个整数集合的对应位置上。_intsetSet 实现如下:
static void _intsetSet(intset *is, int pos, int64_t value) {
uint32_t encoding = intrev32ifbe(is->encoding); /* a */
if (encoding == INTSET_ENC_INT64) {
((int64_t*)is->contents)[pos] = value; /* b */
memrev64ifbe(((int64_t*)is->contents)+pos); /* c */
} else if (encoding == INTSET_ENC_INT32) {
((int32_t*)is->contents)[pos] = value;
memrev32ifbe(((int32_t*)is->contents)+pos);
} else {
((int16_t*)is->contents)[pos] = value;
memrev16ifbe(((int16_t*)is->contents)+pos);
}
} a) 大端序和小端序只是存储方式,encoding 在存储的时候进行了一次 intrev32ifbe 转换,取出来用的时候需要再进行一次 intrev32ifbe 转换(其实就是序列化和反序列化)。
b) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,然后将 value 的值设置到对应的内存中。
c) memrev64ifbe 的实现参见 字节序 的 memrev64 函数,即将对应内存的值转换成小端序存储。
3、元素获取
获取 的含义就是给定整数集合以及一个位置,返回给定位置的元素的值。_intsetGet 实现如下:
static int64_t _intsetGetEncoded(intset *is, int pos, uint8_t enc) {
int64_t v64;
int32_t v32;
int16_t v16;
if (enc == INTSET_ENC_INT64) {
memcpy(&v64,((int64_t*)is->contents)+pos,sizeof(v64)); /* a */
memrev64ifbe(&v64); /* b */
return v64;
} else if (enc == INTSET_ENC_INT32) {
memcpy(&v32,((int32_t*)is->contents)+pos,sizeof(v32));
memrev32ifbe(&v32);
return v32;
} else {
memcpy(&v16,((int16_t*)is->contents)+pos,sizeof(v16));
memrev16ifbe(&v16);
return v16;
}
}
static int64_t _intsetGet(intset *is, int pos) {
return _intsetGetEncoded(is,pos,intrev32ifbe(is->encoding));
} a) 根据 encoding 的类型,将 contents 转换成指定类型的指针,然后用 pos 进行索引找到对应的内存位置,将内存位置上的值拷贝到临时变量中;
b) 由于是直接的内存拷贝,所以取出来的值还是小端序的,那么在大端序的主机上得到的值是不对的,所以需要再做一次 memrev64ifbe 转换将值还原。
4、元素查找
由于整数集合是有序集合,所以查找某个元素是否在整数集合中,Redis 采用的是二分查找。intsetSearch 实现如下:
static uint8_t intsetSearch(intset *is, int64_t value, uint32_t *pos) {
int min = 0, max = intrev32ifbe(is->length)-1, mid = -1;
int64_t cur = -1;
if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0; /* a */
return 0;
} else { /* b */
if (value > _intsetGet(is,intrev32ifbe(is->length)-1)) {
if (pos) *pos = intrev32ifbe(is->length);
return 0;
} else if (value < _intsetGet(is,0)) {
if (pos) *pos = 0;
return 0;
}
}
while(max >= min) {
mid = ((unsigned int)min + (unsigned int)max) >> 1; /* c */
cur = _intsetGet(is,mid);
if (value > cur) {
min = mid+1;
} else if (value < cur) {
max = mid-1;
} else {
break;
}
}
if (value == cur) { /* d */
if (pos) *pos = mid;
return 1;
} else {
if (pos) *pos = min;
return 0;
}
} a) 整数集合为空,返回0表示查找失败;
b) value 的值比整数集合中的最大值还大,或者比最小值还小,则返回0表示查找失败;
c) 执行二分查找,将找到的值存在 cur 中;
d) 如果找到则返回1,表示查找成功,并且将 pos 设置为 mid 并返回;如果没找到则返回一个需要插入的位置。
5、内存重分配
由于 contents 的内存是动态分配的,所以每次进行元素插入或者删除的时候,都需要重新分配内存,这个实现放在 intsetResize 中,实现如下:
static intset *intsetResize(intset *is, uint32_t len) {
uint32_t size = len*intrev32ifbe(is->encoding);
is = zrealloc(is,sizeof(intset)+size);
return is;
} encoding 本身表示字节个数,所以乘上集合个数 len 就是 contents 数组需要的总字节数了,调用 zrealloc 进行内存重分配,然后返回重新分配后的地址。
注意:zrealloc 的返回值必须返回出去,因为 intset 在进行内存重分配以后,地址可能就变了。即 is = zrealloc(is, ...) 中,此 is 非彼 is。所以,所有调用 intsetResize 的函数都需要连带的返回新的 intset 指针。
6、编码升级
编码升级一定发生在元素插入,并且插入的元素的绝对值比整数集合中的元素都大的时候,所以我们把升级后的元素插入和编码升级放在一个函数实现,名曰 intsetUpgradeAndAdd,实现如下:
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {
uint8_t curenc = intrev32ifbe(is->encoding);
uint8_t newenc = _intsetValueEncoding(value);
int length = intrev32ifbe(is->length);
int prepend = value < 0 ? 1 : 0; /* a */
is->encoding = intrev32ifbe(newenc);
is = intsetResize(is,intrev32ifbe(is->length)+1); /* b */
while(length--)
_intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc)); /* c */
if (prepend)
_intsetSet(is,0,value);
else
_intsetSet(is,intrev32ifbe(is->length),value); /* d */
is->length = intrev32ifbe(intrev32ifbe(is->length)+1);
return is;
} a) curenc 记录升级前的编码,newenc 记录升级后的编码;
b) 将整数集合 is 的编码设置成新的编码后,进行内存重分配;
c) 获取原先内存中的数据,设置到新内存中(注意:由于两段内存空间是重叠的,而且新内存的长度一定大于原先内存,所以需要从后往前进行拷贝);
d) 当插入的值 value 为负数的时候,为了保证集合的有序性,需要插入到 contents 的头部;反之,插入到尾部;当 value 为负数时 prepend 为1,这样就可以保证在内存拷贝的时候将第 0 个位置留空。
如图展示了一个 (-32768, 0, 1, 32767) 的整数集合在插入数字 32768 后的升级的完整过程:
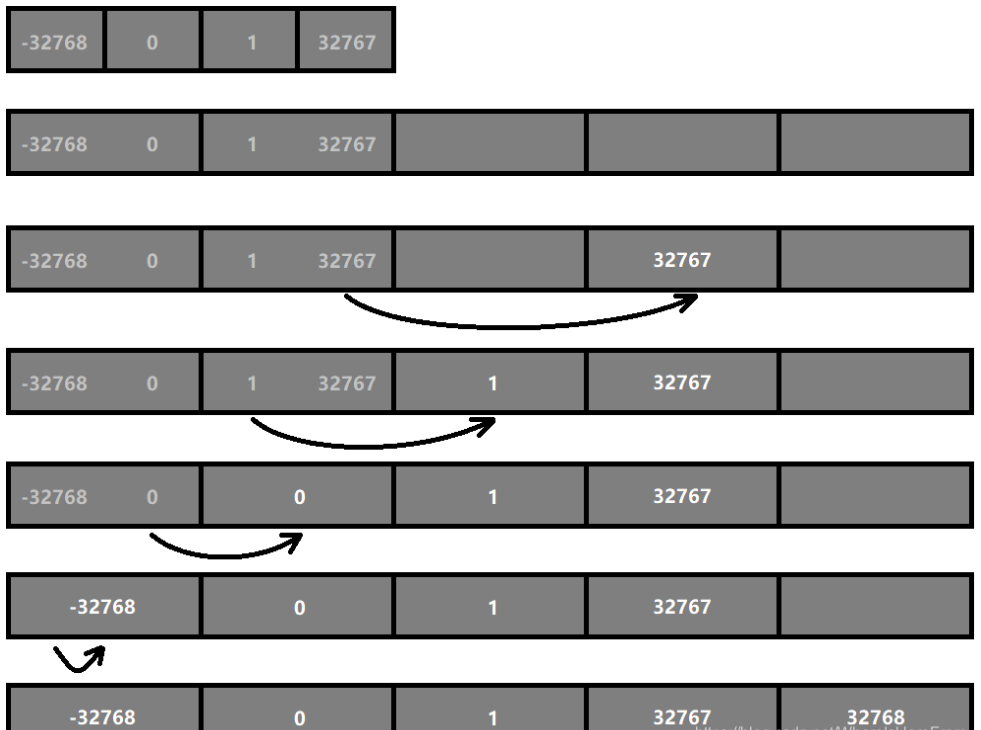
整数集合升级的时间复杂度是 O(n) 的,但是在整数集合的生命期内,升级最多发生两次(从 INTSET_ENC_INT16 到 INTSET_ENC_INT32 以及 从 INTSET_ENC_INT32 到 INTSET_ENC_INT64)。
7、内存迁移
绝大多数情况都是在执行 插入 、删除 、查找 操作。插入 和 删除 会涉及到连续内存的移动。为了实现内存移动,Redis内部实现包括intsetMoveTail函数。
static void intsetMoveTail(intset *is, uint32_t from, uint32_t to) {
void *src, *dst;
uint32_t bytes = intrev32ifbe(is->length)-from; /* a */
uint32_t encoding = intrev32ifbe(is->encoding);
if (encoding == INTSET_ENC_INT64) {
src = (int64_t*)is->contents+from;
dst = (int64_t*)is->contents+to;
bytes *= sizeof(int64_t); /* b */
} else if (encoding == INTSET_ENC_INT32) {
src = (int32_t*)is->contents+from;
dst = (int32_t*)is->contents+to;
bytes *= sizeof(int32_t);
} else {
src = (int16_t*)is->contents+from;
dst = (int16_t*)is->contents+to;
bytes *= sizeof(int16_t);
}
memmove(dst,src,bytes); /* c */
} a) 统计从 from 到结尾,有多少个元素;
b) 根据不同的编码,计算出需要拷贝的内存字节数 bytes,以及拷贝源位置 src,拷贝目标位置 dst;
c) memmove 是 string.h 中的函数:src指向的内存区域拷贝 bytes 个字节到 dst 所指向的内存区域,这个函数是支持内存重叠的;
8、元素插入
最后,讲整数集合的插入和删除,插入调用的是 intsetAdd,在 intset.c 中实现:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 1;
if (valenc > intrev32ifbe(is->encoding)) { /* a */
return intsetUpgradeAndAdd(is,value);
} else {
if (intsetSearch(is,value,&pos)) {
if (success) *success = 0; /* b */
return is;
}
is = intsetResize(is,intrev32ifbe(is->length)+1); /* c */
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); /* d */
}
_intsetSet(is,pos,value);
is->length = intrev32ifbe(intrev32ifbe(is->length)+1); /* e */
return is;
} a) 插入的数值 value 的内存编码大于现有集合的编码,直接调用 intsetUpgradeAndAdd 进行编码升级;
b) 集合元素是不重复的,如果 intsetSearch 能够找到,则将 success 置为0,表示此次插入失败;
c) 如果 intsetSearch 找不到,将 intset 进行内存重分配,即 长度 加 1。
d) pos 为 intsetSearch 过程中找到的 value 将要插入的位置,我们将 pos 以后的内存向后移动1个单位 (这里的1个单位可能是2个字节、4个字节或者8个字节,取决于当前整数集合的内存编码)。
e) 调用 _intsetSet 将 value 的值设置到 pos 的位置上,然后给成员变量 length 加 1。最后返回 intset 指针首地址,因为其间进行了 intsetResize,传入的 intset 指针和返回的有可能不是同一个了。
9、元素删除
删除元素调用的是 intsetRemove ,实现如下:
intset *intsetRemove(intset *is, int64_t value, int *success) {
uint8_t valenc = _intsetValueEncoding(value);
uint32_t pos;
if (success) *success = 0;
if (valenc <= intrev32ifbe(is->encoding) && intsetSearch(is,value,&pos)) { /* a */
uint32_t len = intrev32ifbe(is->length);
if (success) *success = 1;
if (pos < (len-1)) intsetMoveTail(is,pos+1,pos); /* b */
is = intsetResize(is,len-1); /* c */
is->length = intrev32ifbe(len-1);
}
return is;
} a) 当整数集合中存在 value 这个元素时才能执行删除操作;
b) 如果能通过 intsetSearch 找到元素,那么它的位置就在 pos 上,这是通过 intsetMoveTail 将内存往前挪;
c) intsetResize 重新分配内存,并且将集合长度减1;
The above is the detailed content of What are the methods of using Redis integer collection?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
