

How to solve Redis related problems

Redis persistence mechanism
Redis is an in-memory database that supports persistence. It synchronizes data in memory to hard disk files through the persistence mechanism to ensure data persistence. When Redis is restarted, the data can be restored by reloading the hard disk files into the memory.
Implementation: Create a fork() child process separately, copy the database data of the current parent process to the memory of the child process, and then write it to a temporary file by the child process. After the persistence process is over, use this temporary The file replaces the last snapshot file, then the child process exits and the memory is released.
RDB is the default persistence method of Redis. According to a certain time period strategy, the memory data is saved to a binary file on the hard disk in the form of a snapshot. That is, Snapshot snapshot storage, the corresponding generated data file is dump.rdb, and the snapshot cycle is defined through the save parameter in the configuration file. (A snapshot can be a copy of the data it represents, or a copy of the data.)
AOF: Redis will append each received write command to the At the end of the file, it is similar to MySQL's binlog. When Redis restarts, the contents of the entire database will be rebuilt in memory by re-executing the write commands saved in the file.
When both methods are enabled at the same time, data recovery Redis will give priority to AOF recovery.
Cache avalanche, cache penetration, cache preheating, cache update, cache downgrade and other issues
Cache avalancheWe can simply understand it as: due to the original cache failure , during the period when the new cache has not expired
(for example: we used the same expiration time when setting up the cache, and a large area of cache expired at the same time), all requests that should have accessed the cache went to query the database, and the database This causes huge pressure on the CPU and memory, and in severe cases can cause database downtime. This creates a series of chain reactions, causing the entire system to collapse.
Solution:
Most system designers consider using locks (the most common solution) or queues to ensure that there will not be a large number of threads reading and writing the database at one time. , thereby avoiding a large number of concurrent requests from falling on the underlying storage system during a failure. Another simple solution is to spread the cache expiration time.
2. Cache Penetration
Cache penetration refers to user query data, which is not found in the database and naturally will not be found in the cache. This will cause the user to not find it in the cache when querying, and have to go to the database to query again every time, and then return empty (equivalent to two useless queries). In this way, the request bypasses the cache and directly checks the database. This is also a cache hit rate issue that is often raised.
Solution;
The most common is to use Bloom filter to hash all possible data into a bitmap large enough, a certain Data that does not exist will be intercepted by this bitmap, thereby avoiding query pressure on the underlying storage system.
There is also a more simple and crude method. If the data returned by a query is empty (whether the data does not exist or the system fails), we will still cache the empty result, but it The expiration time will be very short, no more than five minutes at most. The default value set directly is stored in the cache, so that the value is obtained the second time in the cache without continuing to access the database. This method is the simplest and crudest.
The 5TB hard disk is full of data. Please write an algorithm to deduplicate the data. How to solve this problem if the data is 32bit size? What if it is 64bit?
The ultimate utilization of space is Bitmap and Bloom Filter.
Bitmap: The typical one is the hash table
The disadvantage is that Bitmap can only record 1 bit of information for each element. If you want to complete additional functions, I am afraid you can only do it by sacrificing more space and time. .
Bloom filter (recommended)
It introduces k(k>1)k(k>1) independent hash functions to ensure that in a given space, error Under the judgment rate, the process of element weight judgment is completed.
Its advantage is that space efficiency and query time are much higher than the general algorithm. Its disadvantage is that it has a certain misrecognition rate and deletion difficulties.
The core idea of the Bloom-Filter algorithm is to use multiple different Hash functions to resolve "conflicts".
There is a conflict (collision) problem with Hash. The values of two URLs obtained by using the same Hash may be the same. In order to reduce conflicts, we can introduce several more hashes. If we find that an element is not in the set through one of the hash values, then the element is definitely not in the set. Only when all Hash functions tell us that the element is in the set can we be sure that the element exists in the set. This is the basic idea of Bloom-Filter.
Bloom-Filter is generally used to determine whether an element exists in a large data set.
Added by reminder: The difference between cache penetration and cache breakdown
Cache breakdown: refers to a key that is very hot, and large concurrency is concentrated on accessing this key. When the key expires, the continued large concurrent access will break through the cache and directly request the database.
Solution; Before accessing the key, use SETNX (set if not exists) to set another short-term key to lock access to the current key, and then delete the short-term key after the access.
3. Cache preheating
Cache preheating should be a relatively common concept. I believe many friends can easily understand it. Cache preheating is when the system goes online. Finally, the relevant cache data is directly loaded into the cache system. In this way, you can avoid the problem of querying the database first and then caching the data when the user requests it! Users directly query cached data that has been preheated!
Solution ideas:
1. Directly write a cache refresh page and do it manually when going online;
2. The amount of data is not large and can be loaded automatically when the project starts;
3. Timing Refresh cache;
4. Cache update
In addition to the cache invalidation strategy that comes with the cache server (Redis has 6 strategies to choose from by default), we can also use There are two common strategies for customized cache elimination based on specific business needs:
(1) Clean up expired caches regularly;
(2) When a user makes a request, then determine the cache used for this request. Whether the cache expires, if it expires, go to the underlying system to get new data and update the cache.
Both have their own advantages and disadvantages. The disadvantage of the first one is that it is more troublesome to maintain a large number of cached keys. The disadvantage of the second one is that every time a user requests it, the cache must be judged to be invalid, and the logic is relatively complicated! Which solution to use specifically can be weighed based on your own application scenarios.
5. Cache downgrade
When the number of visits increases sharply, service problems occur (such as slow response time or no response), or non-core services affect the performance of core processes, it is still necessary to ensure service Still available, even with compromised service. The system can automatically downgrade based on some key data, or configure switches to achieve manual downgrade.
The ultimate goal of downgrading is to ensure that core services are available, even if they are lossy. And some services cannot be downgraded (such as adding to shopping cart, checkout).
Set the plan based on the reference log level:
(1) General: For example, some services occasionally time out due to network jitter or the service is going online, and can be automatically downgraded;
(2) Warning: Some services may time out within a period of time. If the success rate fluctuates (for example, between 95 and 100%), you can automatically downgrade or manually downgrade, and send an alarm;
(3) Error: For example, the availability rate is lower than 90%, or the database connection pool is exhausted , or the number of visits suddenly surges to the maximum threshold that the system can withstand. At this time, it can be automatically downgraded or manually downgraded according to the situation;
(4) Serious error: For example, the data is wrong due to special reasons, and an emergency manual downgrade is required at this time. .
The purpose of service downgrade is to avoid Redis service failure, which in turn causes database avalanche problems. Therefore, for unimportant cached data, a service downgrade strategy can be adopted. For example, a common approach is that if there is a problem with Redis, instead of querying the database, it directly returns the default value to the user.
What are hot data and cold data?
Hot data, cache is valuable
For cold data, most of the data may have been squeezed out of the memory before it is accessed again, which not only takes up memory, and not much value. For data that is frequently modified, consider using caching depending on the situation
For the above two examples, the longevity list and navigation information both have a characteristic, that is, the frequency of information modification is not high, and the read rate is usually very high.
For hot data, such as one of our IM products, birthday greeting module, and birthday list of the day, the cache may be read hundreds of thousands of times. For another example, in a navigation product, we cache navigation information and may read it millions of times in the future.
**Cache only makes sense if the data is read at least twice before updating. This is the most basic strategy. If the cache fails before it takes effect, it will not be of much value.
What about the scenario where the cache does not exist and the frequency of modification is very high, but caching has to be considered? have! For example, this reading interface puts a lot of pressure on the database, but it is also hot data. At this time, you need to consider caching methods to reduce the pressure on the database, such as the number of likes, collections, and shares of one of our assistant products. This is very typical hot data, but it keeps changing. At this time, the data needs to be saved to the Redis cache synchronously to reduce the pressure on the database.
What are the differences between Memcache and Redis?
1). Storage method Memecache stores all data in the memory. It will hang up after a power outage. The data cannot exceed the memory size. Part of Redis is stored on the hard disk, and redis can persist its data
2). All values of the data support type memcached are simple strings. As its replacement, redis supports richer data types and provides list , storage of set, zset, hash and other data structures
3). The underlying models used are different, the underlying implementation methods and the application protocols for communication with the client are different. Redis directly built its own VM mechanism, because if the general system calls system functions, it will waste a certain amount of time to move and request.
4). Value value sizes are different: Redis can reach a maximum of 512M; memcache is only 1mb.
5) The speed of redis is much faster than memcached
6) Redis supports data backup, that is, data backup in master-slave mode.
Why is single-threaded redis so fast?
(1) Pure memory operation
(2) Single-threaded operation, avoiding frequent context switching
(3) Using non- Blocking I/O multiplexing mechanism
The data types of redis, and the usage scenarios of each data type
Answer: There are five types
(1)String
This In fact, there is nothing to say. For the most common set/get operations, value can be either a String or a number. Generally, some complex counting functions are cached.
(2)hash
The value here stores a structured object, and it is more convenient to operate a certain field in it. When bloggers do single sign-on, they use this data structure to store user information, use cookieId as the key, and set 30 minutes as the cache expiration time, which can simulate a session-like effect very well.
(3) list
Using the data structure of List, you can perform simple message queue functions. Another thing is that you can use the lrange command to implement redis-based paging function, which has excellent performance and good user experience. I also use a scenario that is very suitable—getting market information. It is also a scene of producers and consumers. LIST can implement the queuing and first-in-first-out principle very well.
(4)set
Because set is a collection of unique values. Therefore, the global deduplication function can be implemented. Why not use the Set that comes with the JVM for deduplication? Because our systems are generally deployed in clusters, it is troublesome to use the Set that comes with the JVM. Is it too troublesome to set up a public service just to do global deduplication?
In addition, by using intersection, union, difference and other operations, you can calculate common preferences, all preferences, your own unique preferences and other functions.
(5) sorted set
sorted set has an additional weight parameter score, and the elements in the set can be arranged according to score. You can make a ranking application and take TOP N operations.
Redis internal structure
dict is essentially to solve the search problem in the algorithm (Searching). It is a data structure used to maintain the mapping relationship between key and value. Maps or dictionaries in many languages are similar. Essentially, it is to solve the search problem (Searching) in the algorithm
sds sds is equivalent to char *. It can store any binary data and cannot be represented by the character '\ like C language strings. 0' to identify the end of the string, so it must have a length field.
skiplist (skip list) Skip list is a single-layer multi-pointer linked list that is very simple to implement. It has high search efficiency, comparable to an optimized binary balanced tree. Compared with the implementation of balanced tree,
quicklist
ziplist The compression table ziplist is an encoded list, which is composed of a series of special encodings A sequential data structure composed of consecutive memory blocks,
redis’ expiration strategy and memory elimination mechanism
redis adopts regular deletion and lazy deletion strategy.
Why not use a scheduled deletion strategy?
Scheduled deletion uses a timer to monitor the key, and it will be automatically deleted when it expires. Although the memory is released in time, it consumes a lot of CPU resources. Under large concurrent requests, the CPU needs to use time to process the request instead of deleting the key, so this strategy is not adopted.
How does lazy deletion work?
Periodic deletion How does lazy deletion work? Deletion, redis checks every 100ms by default to see if there are expired keys, and deletes them if there are expired keys. It should be noted that redis does not check all keys every 100ms, but randomly selects them for inspection (if all keys are checked every 100ms, wouldn't redis be stuck)? Therefore, if you only adopt a regular deletion strategy, many keys will not be deleted by the time.
So, lazy deletion comes in handy. That is to say, when you get a key, redis will check whether the key has expired if it has an expiration time set? If it expires, it will be deleted at this time.
Are there no other problems with regular deletion and lazy deletion?
No, if regular deletion does not delete the key. Then you did not request the key immediately, which means that lazy deletion did not take effect. In this way, the memory of redis will become higher and higher. Then the memory elimination mechanism should be adopted.
There is a line of configuration in redis.conf
maxmemory-policy volatile-lru
This configuration is configured with the memory elimination strategy (what, you haven’t configured it? Reflect on yourself)
volatile- lru: Select the least recently used data from the data set (server.db[i].expires) with an expiration time set to eliminate
volatile-ttl: Select the least recently used data from the data set with an expiration time set Select the data that will expire from the data set (server.db[i].expires) to eliminate
volatile-random: From the data set (server.db[i].expires) that has set the expiration time Randomly select data elimination
allkeys-lru: Select the least recently used data from the data set (server.db[i].dict) to eliminate
allkeys-random: Select any data from the data set (server.db[i].dict) to eliminate
no-enviction (eviction): prohibit the eviction of data, new write operations will report an error
ps : If the expire key is not set and the prerequisites are not met; then the behavior of volatile-lru, volatile-random and volatile-ttl strategies is basically the same as noeviction (no deletion).
Why is Redis single-threaded
The official FAQ states that because Redis is a memory-based operation, the CPU is not the bottleneck of Redis. The bottleneck of Redis is most likely the size of the machine memory or the network bandwidth. . Since single-threading is easy to implement, and the CPU will not become a bottleneck, it is logical to adopt a single-threaded solution (after all, using multi-threading will cause a lot of trouble!) Redis uses queue technology to turn concurrent access into serial access
1 ) Most requests are pure memory operations (very fast) 2) Single-threaded, avoiding unnecessary context switches and race conditions
3) Non-blocking IO advantages:
1. Fast because of data Exists in memory, similar to HashMap, the advantage of HashMap is that the time complexity of search and operation is O(1)
2. Supports rich data types, supports string, list, set, sorted set, hash
3 .Support transactions and operations are all atomic. The so-called atomicity means that all changes to the data are either executed or not executed at all
4. Rich features: can be used for caching, messaging, setting expiration time by key, after expiration It will be automatically deleted. How to solve the problem of concurrent key competition in redis
There are multiple subsystems setting a key at the same time. What should we pay attention to at this time? It is not recommended to use the redis transaction mechanism. Because our production environment is basically a redis cluster environment, data sharding operations are performed. When you have multiple key operations involved in a transaction, these multiple keys are not necessarily stored on the same redis-server. Therefore, the transaction mechanism of redis is very useless.
(1) If you operate on this key, the order is not required: prepare a distributed lock, everyone grabs the lock, and just do the set operation after grabbing the lock
(2) If you operate on this key, the order is required : Distributed lock timestamp. Assume that system B grabs the lock first and sets key1 to {valueB 3:05}. Next, system A grabs the lock and finds that the timestamp of its valueA is earlier than the timestamp in the cache, so it does not perform the set operation. And so on.
(3) Using queues to turn the set method into serial access can also enable redis to encounter high concurrency. If the consistency of reading and writing keys is ensured
All operations on redis are atomic and thread-safe. For operations, you don’t need to consider concurrency issues. Redis has already handled concurrency issues for you internally.
What should be done with the Redis cluster solution? What are the plans?
1.twemproxy, the general concept is that it is similar to a proxy method. When used, the place where redis needs to be connected is changed to connect to twemproxy. It will receive the request as a proxy and use a consistent hash algorithm. , transfer the request to specific redis, and return the result to twemproxy.
Disadvantages: Due to the pressure of twemproxy's own single-port instance, after using consistent hashing, the calculated value changes when the number of redis nodes changes, and the data cannot be automatically moved to the new node.
2.codis, the most commonly used cluster solution at present, basically has the same effect as twemproxy, but it supports the recovery of old node data to new hash nodes when the number of nodes changes
3. The cluster that comes with redis cluster3.0 is characterized by the fact that its distributed algorithm is not consistent hashing, but the concept of hash slots, and it supports node setting slave nodes. See the official documentation for details.
Have you tried deploying multi-machine redis? How to ensure data consistency?
Master-slave replication, read-write separation
One is the master database (master) and the other is the slave database (slave). The master database can perform read and write operations. When a write operation occurs, the data will be automatically Synchronize to the slave database, and the slave database is generally read-only and receives data synchronized from the master database. A master database can have multiple slave databases, while a slave database can only have one master database.
How to deal with a large number of requests
redis is a single-threaded program, which means that it can only handle one client request at the same time;
redis is multiplexed through IO Use (select, epoll, kqueue, different implementations based on different platforms) to handle
Redis common performance problems and solutions?
(1) Master is best not to do any persistence work, such as RDB memory snapshots and AOF log files
(2) If the data is important, a Slave enables AOF backup data, and the policy is set to every Synchronize once per second
(3) For the speed of master-slave replication and the stability of the connection, it is best for Master and Slave to be in the same LAN
(4) Try to avoid adding slave libraries to the master library that is under great pressure
(5) Do not use a graph structure for master-slave replication. It is more stable to use a one-way linked list structure, that is: Master Slave3…
Explanation Under the Redis thread model
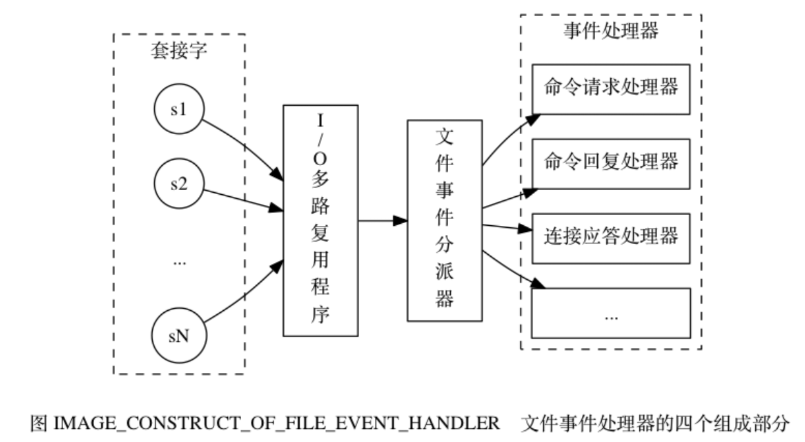
file event handlers include sockets, I/O multiplexers, file event dispatchers (dispatcher), and event handlers . Use an I/O multiplexer to listen to multiple sockets at the same time and associate different event handlers with the sockets based on the task they are currently performing. When the monitored socket is ready to perform operations such as connection response (accept), read (read), write (write), close (close), etc., the file event corresponding to the operation will be generated. At this time, the file The event handler will call the event handler previously associated with the socket to handle these events.
The I/O multiplexer is responsible for listening to multiple sockets and delivering those sockets that generated events to the file event dispatcher.
Working principle:
1) The I/O multiplexer is responsible for listening to multiple sockets and transmitting those sockets that generated events to the file event dispatcher.
Although multiple file events may occur concurrently, the I/O multiplexer will always enqueue all event-generating sockets into a queue, and then pass through this queue to order (Sequentially), synchronously (synchronously), one socket at a time is transmitted to the file event dispatcher: After the event generated by the previous socket is processed (the socket is associated with the event) event handler is executed), the I/O multiplexer will continue to pass the next socket to the file event dispatcher. If a socket is both readable and writable, then the server will read the socket first and then write the socket.
Why are Redis operations atomic? Guaranteed atomicity?
For Redis, the atomicity of a command means that an operation cannot be subdivided, and the operation is either executed or not.
The reason why Redis operations are atomic is because Redis is single-threaded.
All APIs provided by Redis itself are atomic operations. Transactions in Redis actually ensure the atomicity of batch operations.
Are multiple commands atomic in concurrency?
Not necessarily, change get and set to single command operations, incr. Use Redis transactions, or use Redis Lua== to implement.
Redis Transaction
The Redis transaction function is implemented through the four primitives MULTI, EXEC, DISCARD and WATCH
Redis will serialize all commands in a transaction and then execute them in order.
1.redis does not support rollback "Redis does not rollback when a transaction fails, but continues to execute the remaining commands", so the internals of Redis can remain simple and fast.
2. If an error occurs in the command in a transaction, then all commands will not be executed;
3. If an error occurs in a transaction Running error , then the correct command will be executed.
Note: Redis's discard only ends this transaction, and the impact of the correct command still exists.
1) The MULTI command is used to start a transaction, and it always returns OK. After MULTI is executed, the client can continue to send any number of commands to the server. These commands will not be executed immediately, but will be placed in a queue. When the EXEC command is called, all commands in the queue will be executed.
2) EXEC: Execute commands in all transaction blocks. Returns the return values of all commands within the transaction block, arranged in the order of command execution. When the operation is interrupted, the empty value nil is returned.
3) By calling DISCARD, the client can clear the transaction queue and give up executing the transaction, and the client will exit from the transaction state.
4) The WATCH command can provide check-and-set (CAS) behavior for Redis transactions. One or more keys can be monitored. Once one of the keys is modified (or deleted), subsequent transactions will not be executed, and monitoring continues until the EXEC command.
Redis implements distributed locks
Redis is a single-process single-thread mode. It uses queue mode to turn concurrent access into serial access, and there is no competition between multiple clients' connections to Redis. You can use the SETNX command in Redis to implement distributed locks.
Set the value of key to value if and only if key does not exist. If the given key already exists, SETNX does not take any action
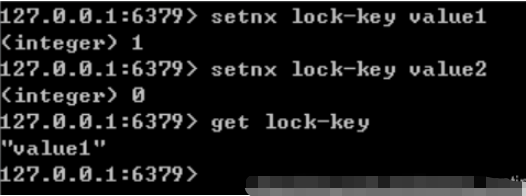
Unlocking: Use the del key command to release the lock
Solving the deadlock:
1) Through Redis In expire(), set the maximum holding time for the lock. If it exceeds, Redis will help us release the lock.
2) This can be achieved by using the command combination of setnx key "current system time locked time" and getset key "current system time locked time".
The above is the detailed content of How to solve Redis related problems. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
How to solve data loss with redis
Apr 10, 2025 pm 08:24 PM
Redis data loss causes include memory failures, power outages, human errors, and hardware failures. The solutions are: 1. Store data to disk with RDB or AOF persistence; 2. Copy to multiple servers for high availability; 3. HA with Redis Sentinel or Redis Cluster; 4. Create snapshots to back up data; 5. Implement best practices such as persistence, replication, snapshots, monitoring, and security measures.
 How to use the redis command line
Apr 10, 2025 pm 10:18 PM
How to use the redis command line
Apr 10, 2025 pm 10:18 PM
Use the Redis command line tool (redis-cli) to manage and operate Redis through the following steps: Connect to the server, specify the address and port. Send commands to the server using the command name and parameters. Use the HELP command to view help information for a specific command. Use the QUIT command to exit the command line tool.
