
 Technology peripherals
AI
Is the 'RL' in RLHF required? Some people use binary cross entropy to directly fine-tune LLM, and the effect is better.
Technology peripherals
AI
Is the 'RL' in RLHF required? Some people use binary cross entropy to directly fine-tune LLM, and the effect is better.
Is the 'RL' in RLHF required? Some people use binary cross entropy to directly fine-tune LLM, and the effect is better.

Recently, unsupervised language models trained on large datasets have achieved surprising capabilities. However, these models are trained on data generated by humans with a variety of goals, priorities, and skill sets, some of which are not necessarily expected to be imitated.
Selecting a model’s desired responses and behaviors from its very broad knowledge and capabilities is critical to building safe, high-performance, and controllable AI systems. Many existing methods instill desired behaviors into language models by using carefully curated human preference sets that represent the types of behaviors that humans consider safe and beneficial. This preference learning stage occurs on large textual data sets. After an initial phase of large-scale unsupervised pre-training.
While the most straightforward preference learning method is supervised fine-tuning of high-quality responses demonstrated by humans, a relatively popular class of methods recently is from human (or artificial intelligence) feedback. Perform reinforcement learning (RLHF/RLAIF). The RLHF method matches a reward model to a dataset of human preferences and then uses RL to optimize a language model policy to produce responses that assign high rewards without excessively deviating from the original model.
While RLHF produces models with impressive conversational and coding capabilities, the RLHF pipeline is much more complex than supervised learning, involving training multiple language models and looping through training Sampling from language model policies incurs a large computational cost.
And a recent study shows that:The RL-based objective used by existing methods can be accurately optimized with a simple binary cross-entropy objective, thus greatly improving the Simplified preference learning pipeline. That is, it is entirely possible to directly optimize language models to adhere to human preferences without the need for explicit reward models or reinforcement learning.

Paper link: https://arxiv.org/pdf/2305.18290 .pdf
Researchers from Stanford University and other institutions proposed Direct Preference Optimization (DPO). This algorithm implicitly optimizes the existing RLHF algorithm. Same goal (reward maximization with KL - divergence constraints), but simple to implement and straightforward to train.
Experiments show that DPO is at least as effective as existing methods, including those based on RLHF of PPO.
DPO algorithm
Like existing algorithms, DPO also relies on theoretical preference models (such as the Bradley-Terry model) to measure a given How well the reward function fits empirical preference data. However, existing methods use a preference model to define a preference loss to train a reward model and then train a policy that optimizes the learned reward model, whereas DPO uses changes in variables to directly define the preference loss as a function of the policy. Given the human preference dataset for model responses, DPO can therefore optimize the policy using a simple binary cross-entropy objective without the need to explicitly learn a reward function or sample from the policy during training.
The DPO update increases the relative log probability of preferred responses versus non-preferred responses, but it includes a dynamic, per-sample importance weight to prevent model degradation, The researchers found that this degradation occurs for a naive probability ratio target.
In order to understand DPO mechanistically, it is useful to analyze the gradient of the loss function  . The gradient with respect to parameter θ can be written as:
. The gradient with respect to parameter θ can be written as:
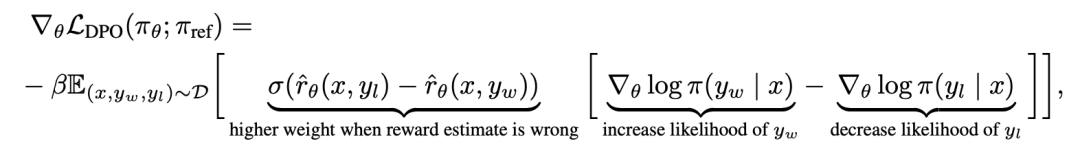
where 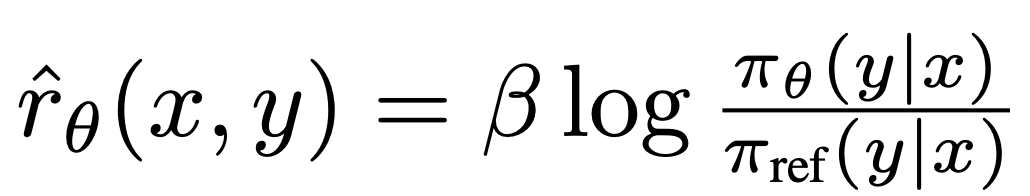 is the reward implicitly defined by the language model
is the reward implicitly defined by the language model 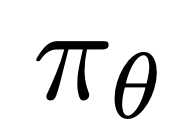 and the reference model
and the reference model 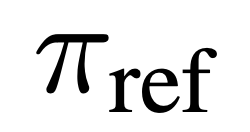 . Intuitively, the gradient of the loss function
. Intuitively, the gradient of the loss function  increases the likelihood of the preferred completion y_w and decreases the likelihood of the non-preferred completion y_l.
increases the likelihood of the preferred completion y_w and decreases the likelihood of the non-preferred completion y_l.
Importantly, the weight of these samples is determined by the implicit reward model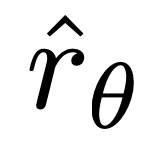 The evaluation of disliked completion is determined by β is the scale, that is, how incorrect the implicit reward model is in ranking completion, which is also a reflection of the KL constraint strength. Experiments demonstrate the importance of this weighting, as a naive version of this method without weighting coefficients leads to a degradation of the language model (Appendix Table 2).
The evaluation of disliked completion is determined by β is the scale, that is, how incorrect the implicit reward model is in ranking completion, which is also a reflection of the KL constraint strength. Experiments demonstrate the importance of this weighting, as a naive version of this method without weighting coefficients leads to a degradation of the language model (Appendix Table 2).
In Chapter 5 of the paper, the researcher further explained the DPO method, provided theoretical support, and compared the advantages of DPO with the Actor-Critic algorithm for RLHF ( Such as PPO) issues. Specific details can be found in the original paper.
Experiment
In the experiment, the researchers evaluated the ability of DPO to train policies directly based on preferences.
First, in a well-controlled text generation environment, they considered the question: Compared with common preference learning algorithms such as PPO, DPO trades off reward maximization in the reference policy How efficient is KL-divergence minimization? We then evaluated DPO's performance on larger models and more difficult RLHF tasks, including summarization and dialogue.
It was ultimately found that with almost no hyperparameter tuning, DPO often performed as well as, or even better than, powerful baselines such as RLHF with PPO, while learning rewards The function returns the best N sampling trajectory results.
In terms of tasks, the researchers explored three different open-ended text generation tasks. In all experiments, the algorithm learns policies from the preference dataset 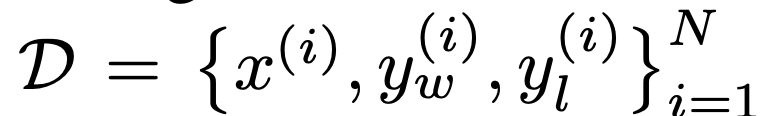 .
.
In controlled emotion generation, x is the prefix of a movie review from the IMDb dataset and the policy must generate y with positive emotion. For comparative evaluation, the experiment uses a pre-trained sentiment classifier to generate preference pairs, where 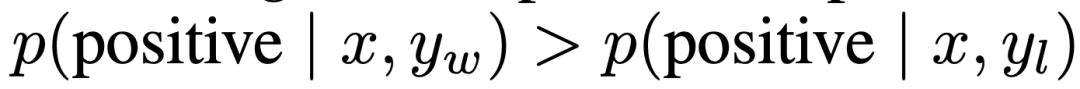 .
.
#For SFT, the researchers fine-tuned GPT-2-large until it converged on the comments on the training split of the IMDB dataset. In summary, x is a forum post from Reddit, and the strategy must generate a summary of the key points in the post. Building on previous work, experiments use the Reddit TL;DR summary dataset and human preferences collected by Stiennon et al. The experiments also used an SFT model fine-tuned based on human-written forum article summaries 2 and RLHF’s TRLX framework. The human preference dataset is a sample collected from a different but similarly trained SFT model by Stiennon et al.
Finally, in a single-turn conversation, x is a human question that can be anything from astrophysics to relationship advice. A policy must provide an engaging and helpful response to the user's query; the policy must provide an interesting and helpful response to the user's query; the experiment uses the Anthropic Helpful and Harmless conversation set, which contains between human and automated assistants of 170k conversations. Each text ends with a pair of responses generated by a large (albeit unknown) language model and a preference label representing the human-preferred response. In this case, no pretrained SFT model is available. Therefore, experiments fine-tune off-the-shelf language models only on preferred completions to form SFT models.
The researchers used two assessment methods. To analyze the efficiency of each algorithm in optimizing the constrained reward maximization goal, experiments evaluate each algorithm by its bounds on achieving rewards and KL-divergence from a reference strategy in a controlled emotion generation environment. Experiments can use ground-truth reward functions (sentiment classifiers), so this bound can be calculated. But in fact, the ground truth reward function is unknown. We therefore evaluate the algorithm's win rate by the win rate of the baseline strategy, and use GPT-4 as a proxy for human assessment of summary quality and response usefulness in summarization and single-round dialogue settings. For abstracts, the experiment uses the reference abstract in the test machine as the limit; for dialogue, the preferred response in the test data set is selected as the baseline. While existing research suggests that language models can be better automatic evaluators than existing metrics, the researchers conducted a human study that demonstrated the feasibility of using GPT-4 for evaluation. GPT-4 judged strongly with humans. The correlation between humans and GPT-4 is generally similar to or higher than the agreement between human annotators.
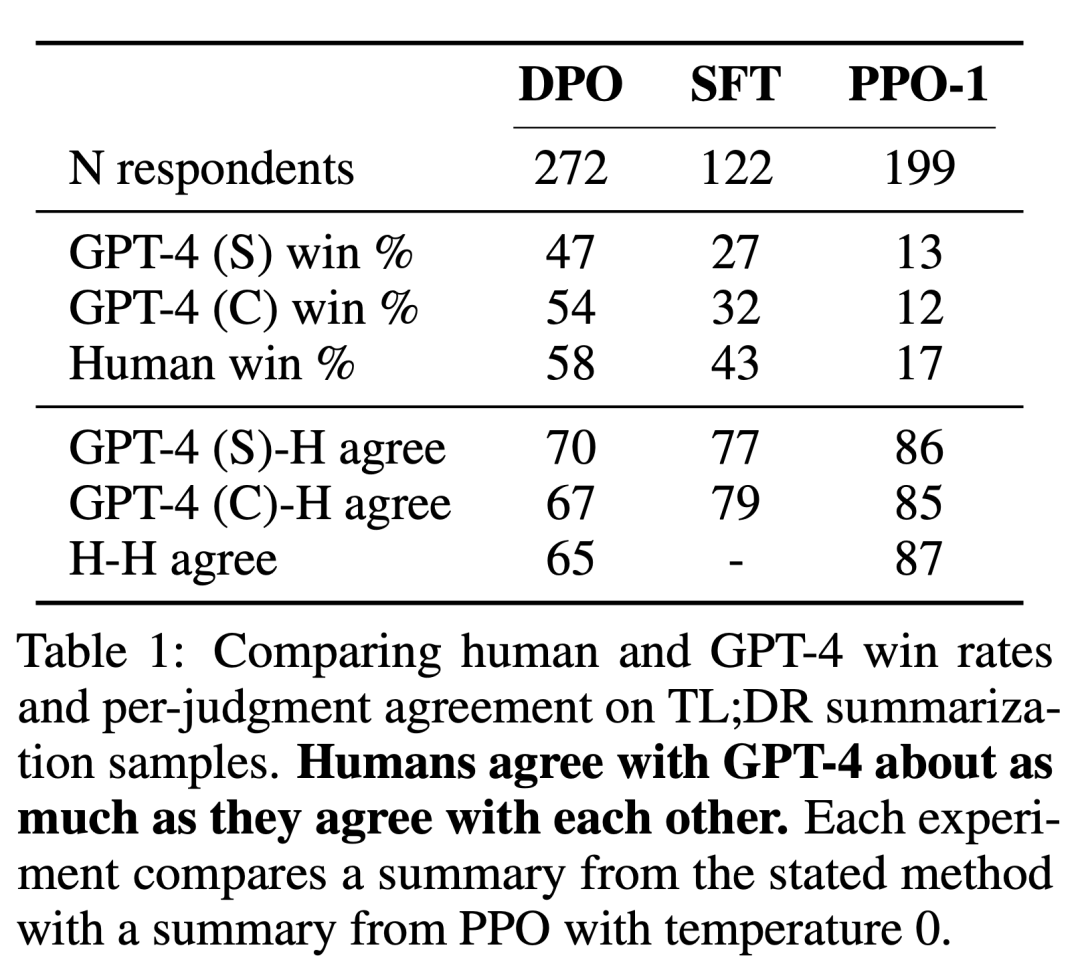
In addition to DPO, the researchers also evaluated several existing training language models to maintain parity with human preferences consistent. At its simplest, the experiments explore GPT-J’s zero-shot prompts on the summary task and Pythia-2.8B’s 2-shot prompts on the dialogue task. Additionally, experiments evaluate the SFT model and Preferred-FT. Preferred-FT is a model fine-tuned via supervised learning on completions y_w selected from SFT models (controlled sentiment and summarization) or general language models (single-turn dialogue). Another pseudo-supervised method is Unlikelihood, which simply optimizes the policy to maximize the probability assigned to y_w and minimize the probability assigned to y_l. The experiment uses an optional coefficient α∈[0,1] on “Unlikehood”. They also considered PPO, using a reward function learned from preference data, and PPO-GT. PPO-GT is an oracle learned from ground truth reward functions available in controlled emotion settings. In the emotion experiments, the team used two implementations of PPO-GT, an off-the-shelf version, and a modified version. The latter normalizes the rewards and further tunes the hyperparameters to improve performance (the experiments also used these modifications when running "Normal" PPO with learning rewards). Finally, we consider the best of N baselines, sample N responses from the SFT model (or Preferred-FT in conversational terms), and return the highest-scoring response based on a reward function learned from the preference dataset. This high-performance approach decouples reward model quality from PPO optimization, but is computationally impractical even for moderate N since it requires N sample completions per query at test time.
Figure 2 shows the reward KL bounds for various algorithms in the emotion setting.
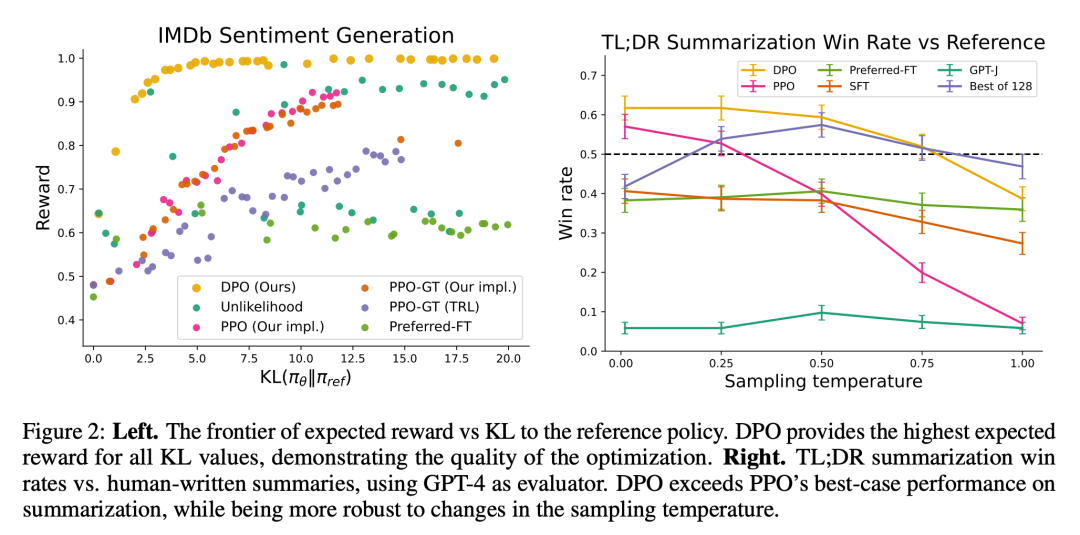
Figure 3 shows that DPO converges to its optimal performance relatively quickly.
For more research details, please refer to the original paper.
The above is the detailed content of Is the 'RL' in RLHF required? Some people use binary cross entropy to directly fine-tune LLM, and the effect is better.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
Managing Hadoop logs on Debian, you can follow the following steps and best practices: Log Aggregation Enable log aggregation: Set yarn.log-aggregation-enable to true in the yarn-site.xml file to enable log aggregation. Configure log retention policy: Set yarn.log-aggregation.retain-seconds to define the retention time of the log, such as 172800 seconds (2 days). Specify log storage path: via yarn.n
