

With the development of large language models (LLM), artificial intelligence is in an explosive period of change. It is well known that LLM can be used in applications such as business, science, and finance, so more and more companies (OpenAI, AI21, CoHere, etc.) are providing LLM as a basic service. Although LLMs like GPT-4 have achieved unprecedented performance in tasks such as question answering, their high-throughput nature makes them very expensive in applications.
For example, ChatGPT costs more than $700,000 per day to operate, while using GPT-4 to support customer service can cost a small business more than $21,000 per month. In addition to the monetary cost, using the largest LLMs comes with significant environmental and energy impacts.
Many companies now provide LLM services through APIs, and their charges vary. The cost of using the LLM API typically consists of three components: 1) prompt cost (proportional to the length of the prompt), 2) generation cost (proportional to the length of the generation), and 3) sometimes a per-query fixed costs.
Table 1 below compares the costs of 12 different commercial LLMs from mainstream vendors, including OpenAI, AI21, CoHere, and Textsynth. Their costs differ by up to 2 orders of magnitude: for example, OpenAI's GPT-4 prompt costs $30 for 10 million tokens, while Textsynth-hosted GPT-J costs just $0.2.
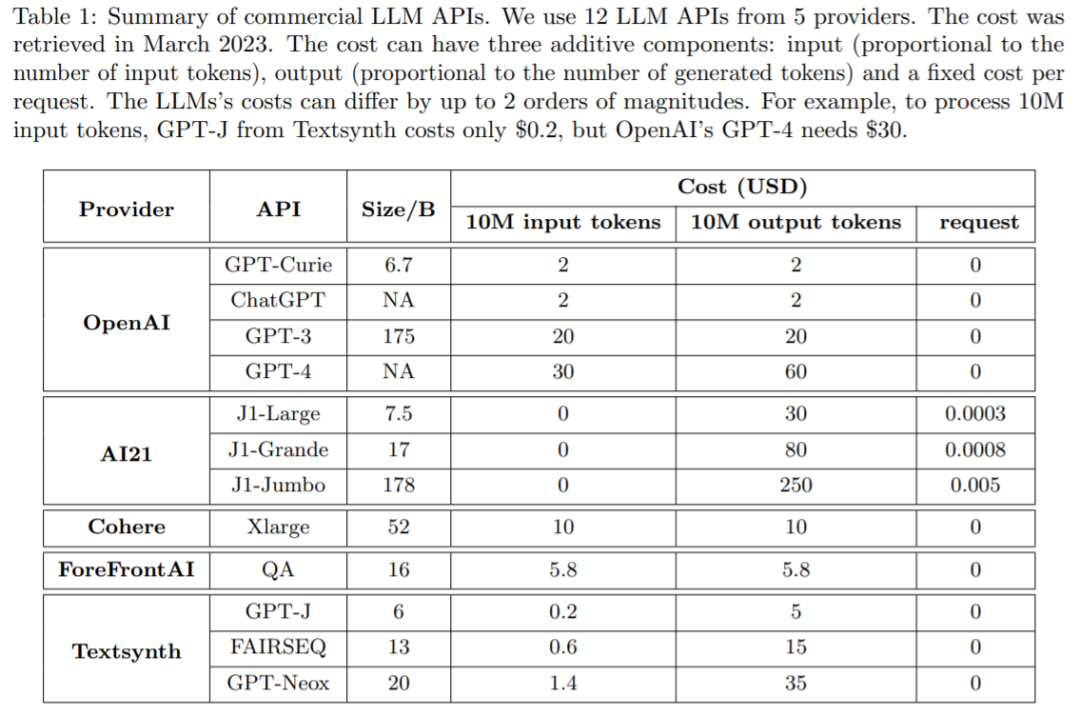
The balance between cost and accuracy is a key factor in decision making, esp. When adopting new technologies. How to effectively and efficiently utilize LLM is a key challenge for practitioners: if the task is relatively simple, then aggregating multiple responses from GPT-J (which is 30 times smaller than GPT-3) can achieve similar performance to GPT-3 , thereby achieving a cost and environmental trade-off. However, on more difficult tasks, GPT-J's performance may degrade significantly. Therefore, new approaches are needed to use LLM cost-effectively.
A recent study attempted to propose a solution to this cost problem. The researchers experimentally showed that FrugalGPT can compete with the performance of the best individual LLM (such as GPT-4) , the cost is reduced by up to 98%, or the accuracy of the best individual LLM is improved by 4% at the same cost.

Researchers from Stanford University review the costs of using LLM APIs such as GPT-4, ChatGPT, J1-Jumbo , and found that these models have different pricing, and the costs can differ by two orders of magnitude, especially using LLM on large quantities of queries and text can be more expensive. Based on this, this study outlines and discusses three strategies that users can exploit to reduce the cost of inference using LLM: 1) prompt adaptation, 2) LLM approximation, and 3) LLM cascading. Furthermore, this study proposes a simple and flexible instance of cascaded LLM, FrugalGPT, which learns which LLM combinations to use in different queries to reduce cost and improve accuracy.
The ideas and findings presented in this study lay the foundation for the sustainable and efficient use of LLM. Being able to adopt more advanced AI capabilities without increasing budgets could drive wider adoption of AI technology across industries, giving even smaller businesses the ability to implement sophisticated AI models into their operations.
Of course, this is just one perspective. It will take some time to reveal what kind of influence FrugalGPT can achieve and whether it can become a "game changer in the AI industry." After the paper was released, this research also caused some controversy:
"The abstract grossly exaggerates what the paper is about, and the title here is grossly misleading. What they have done is devise a way to reduce the need to call high-end on the type of problem covered in the paper. number of models. This is not a replacement for GPT-4 at 2% cost, nor is it a replacement for GPT-4 at 4% accuracy. It is a way to combine GPT-4 with cheaper models and supporting infrastructure .What the abstract doesn't point out is that this requires building a custom model to score results, which is the real heart of the mechanism. … There are legitimate use cases for this approach, which include basic cost engineering like caching results. . But for most use cases, this is completely irrelevant because you don't have a suitable scoring model."

##"They only evaluated this on three (small) datasets and provided no information on how often FrugalGPT selected the respective models. Additionally, they reported that the smaller model achieved better results GPT-4 has higher accuracy, which makes me very skeptical about this paper in general."
How to judge specifically, let's take a look at the content of the paper.
How to use LLM economically and accuratelyThe next paper introduces how to use LLM API efficiently within the budget. As shown in Figure 1 (b), this study discusses three cost reduction strategies, namely prompt adaptation, LLM approximation, and LLM cascading.
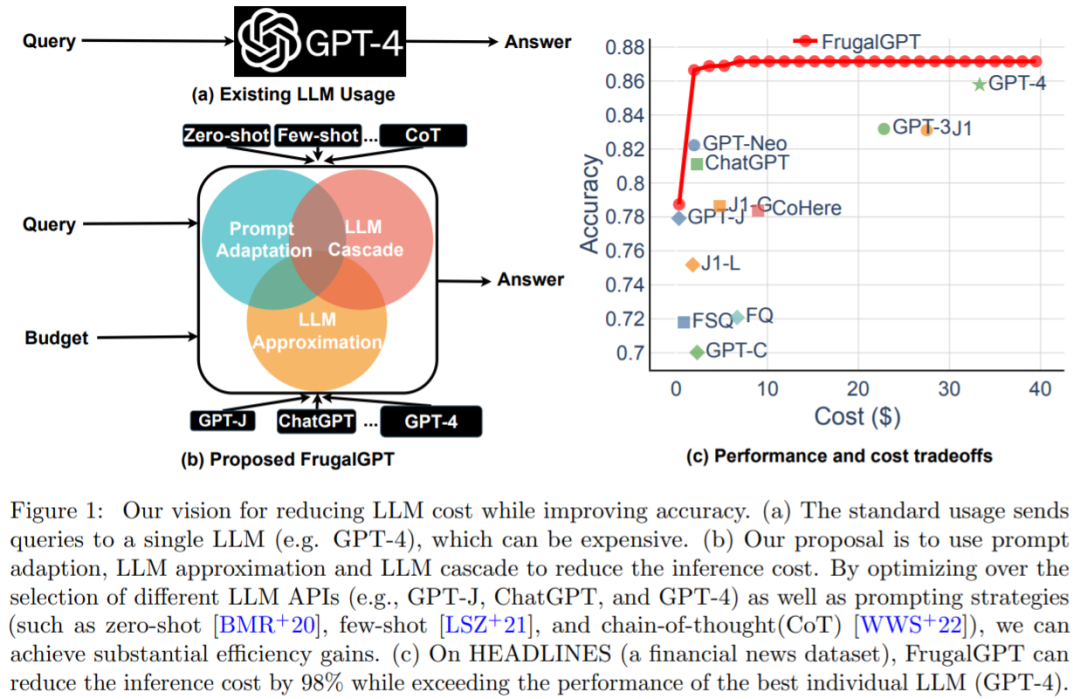
Strategy 1: prompt adaptation. The cost of LLM queries grows linearly with prompt size. Therefore, a reasonable approach to reduce the cost of using the LLM API involves reducing the prompt size, a process the study calls prompt adaptation. The prompt selection is shown in Figure 2(a): instead of using prompt that contains many examples to demonstrate how to perform a task, it is possible to keep only a small subset of examples in prompt. This results in smaller prompts and lower cost. Another example is query concatenation (shown in Figure 2(b)).
Strategy 2: LLM approximation. The concept of LLM approximation is very simple: if using the LLM API is too expensive, it can be approximated using more affordable models or infrastructure. One example of this is shown in Figure 2(c), where the basic idea is to store the response in a local cache (e.g. database) when submitting a query to the LLM API. Another example of LLM approximation is model fine-tuning, as shown in Figure 2 (d).
Strategy 3: LLM cascade. Different LLM APIs have their own strengths and weaknesses in various queries. Therefore, appropriate selection of the LLM to use can both reduce costs and improve performance. An example of LLM cascade is shown in Figure 2(e).
Cost reduction and accuracy improvementThe researcher conducted an empirical study on FrugalGPT LLM cascade with three goals:
The experimental setup is divided into several aspects: LLM API (Table 1), tasks, datasets (Table 2), and FrugalGPT instances.
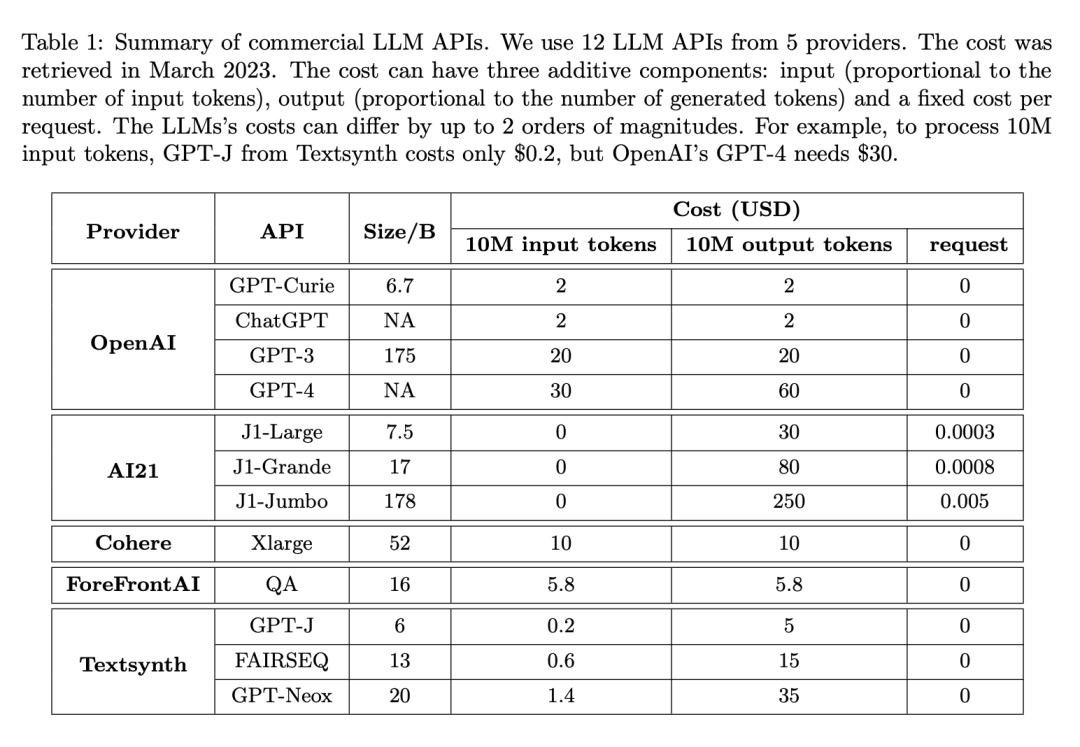
FrugalGPT was developed on top of the above API and evaluated on a range of datasets belonging to different tasks. Among them, HEADLINES is a financial news data set. The goal is to determine the gold price trend (up, down, neutral or none) by reading financial news headlines, which is particularly useful for filtering relevant news in the financial market; OVERRULING is a legal document data set. , whose goal is to determine whether a given sentence is an "overruling", that is, overruling a previous legal case; COQA is a reading comprehension dataset developed in a conversational environment, which the researchers adapted as a direct query answering task.
They focus on the LLM cascade method with a cascade length of 3 because this simplifies the optimization space and have shown good results. Each dataset is randomly divided into a training set to learn the LLM cascade and a test set for evaluation.
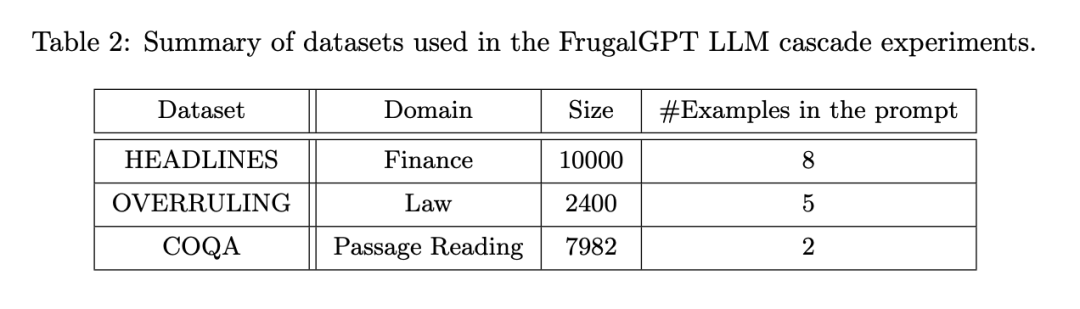
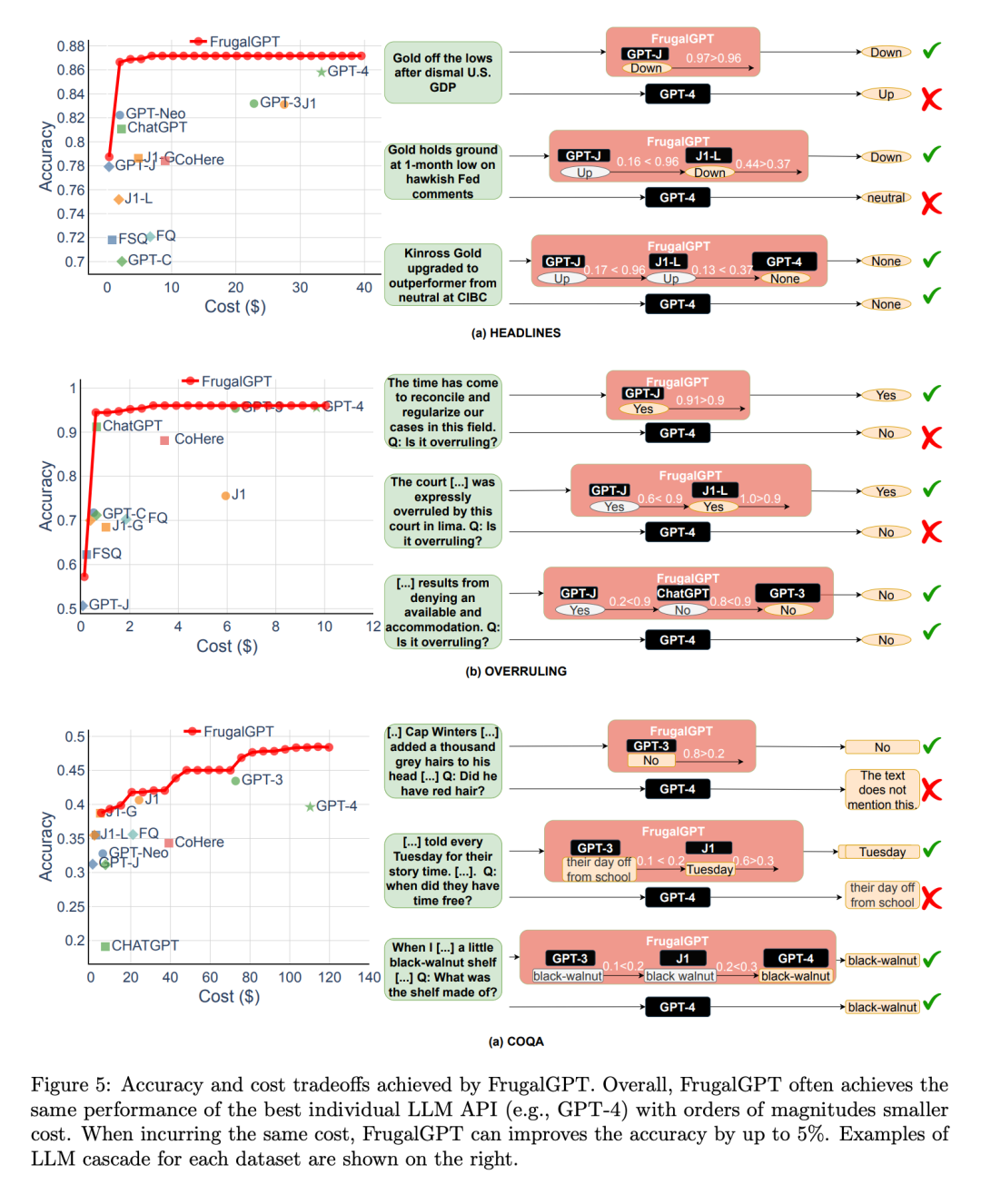
Here is a HEADLINES dataset case study: Set the budget to $6.50, yes One-fifth the cost of GPT-4. Adopt DistilBERT [SDCW19] for regression as the scoring function. It is worth noting that DistilBERT is much smaller than all LLMs considered here and therefore is less expensive. As shown in Figure 3(a), the learned FrugalGPT sequentially calls GPT-J, J1-L, and GPT-4. For any given query, it first extracts an answer from GPT-J. If the answer's score is greater than 0.96, the answer is accepted as the final response. Otherwise, J1-L will be queried. If J1-L's answer score is greater than 0.37, it is accepted as the final answer; otherwise, GPT-4 is called to obtain the final answer. Interestingly, this approach outperforms GPT-4 on many queries. For example, based on Nasdaq's headline "US GDP data is dismal, gold is off its lows", FrugalGPT accurately predicted that prices would fall, while GPT-4 provided a wrong answer (as shown in Figure 3(b) ).
Overall, the result of FrugalGPT is both improved accuracy and reduced cost. As shown in Figure 3 (c), the cost is reduced by 80%, while the accuracy is even 1.5% higher.
##Diversity at LLM
Why is it possible for multiple LLM APIs to yield better performance than the best single LLM? Essentially, this is due to the diversity of generation: even a low-cost LLM can sometimes correctly answer queries that a higher-cost LLM cannot. To measure this diversity, researchers use Maximum Performance Improvement, also known as MPI. The MPI of LLM A relative to LLM B is the probability that LLM A produces a correct answer and LLM B provides an incorrect answer. This metric essentially measures the maximum performance improvement that can be achieved by calling LLM A at the same time as LLM B.
Figure 4 shows the MPI between each pair of LLM APIs for all datasets. On the HEADLINES dataset, GPT-C, GPT-J, and J1-L all improve the performance of GPT-4 by 6%. On the COQA dataset, GPT-4 was wrong for 13% of the data points, but GPT-3 provided the correct answer. While upper bounds on these improvements may not always be achievable, they do demonstrate the possibility of leveraging cheaper services to achieve better performance.

saving cost
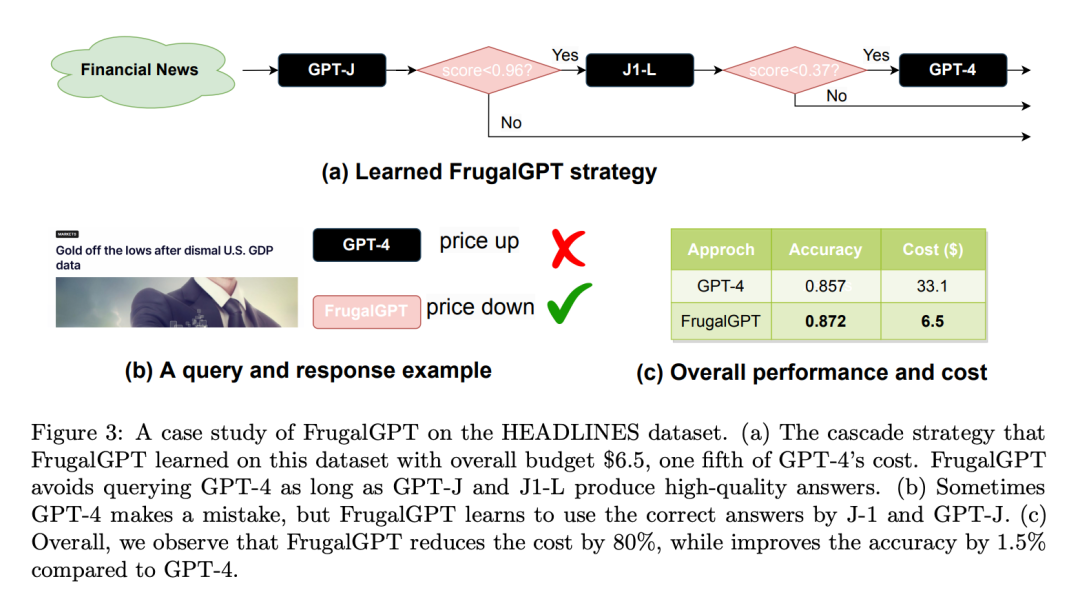
The researchers then examined whether FrugalGPT could reduce costs while maintaining accuracy, and if so, by how much. Table 3 shows the overall cost savings of FrugalGPT, ranging from 50% to 98%. This is possible because FrugalGPT can identify those queries that can be accurately answered by smaller LLMs, and therefore only calls those LLMs that are cost-effective. While powerful but expensive LLMs, such as GPT-4, are only used for challenging queries detected by FrugalGPT.
Performance and Cost Tradeoff
Next, the researchers explored the trade-off between performance and cost of the FrugalGPT implementation, as shown in Figure 5, and made several interesting observations.
First of all, the cost rankings of different LLM APIs are not fixed. Additionally, more expensive LLM APIs sometimes result in worse performance than their cheaper counterparts. These observations highlight the importance of appropriate selection of LLM APIs, even in the absence of budget constraints.
Next, the researchers also noted that FrugalGPT was able to achieve a smooth performance-cost trade-off on all datasets evaluated. This provides flexible options for LLM users and has the potential to help LLM API providers save energy and reduce carbon emissions. In fact, FrugalGPT can simultaneously reduce cost and improve accuracy, probably because FrugalGPT integrates knowledge from multiple LLMs.
The example query shown in Figure 5 further explains why FrugalGPT can simultaneously improve performance and reduce cost. GPT-4 makes mistakes on some queries, such as the first example in part (a), but some low-cost APIs provide correct predictions. FrugalGPT accurately identifies these queries and relies entirely on low-cost APIs. For example, GPT-4 incorrectly infers that there is no overturn from the legal statement “It is time to harmonize and standardize our cases in this area,” as shown in Figure 5(b). However, FrugalGPT accepts the correct answers of GPT-J, avoids the use of expensive LLM, and improves the overall performance. Of course, a single LLM API is not always correct; LLM cascading overcomes this by employing a chain of LLM APIs. For example, in the second example shown in Figure 5(a), FrugalGPT discovers that the generation of GPT-J may be unreliable and turns to the second LLM in the chain, J1-L, to find the correct answer. Again, GPT-4 provides the wrong answer. FrugalGPT is not perfect and there is still plenty of room to reduce costs. For example, in the third example of Figure 5 (c), all LLM APIs in the chain give the same answer. However, FrugalGPT is unsure whether the first LLM is correct, resulting in the need to query all LLMs in the chain. Determining how to avoid this remains an open question.
##For more research details, please refer to the original paper.
The above is the detailed content of GPT-4 API replacement? The performance is comparable and the cost is reduced by 98%. Stanford proposed FrugalGPT, but the research caused controversy. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



