
 Technology peripherals
AI
What else can NLP do? Beihang University, ETH, Hong Kong University of Science and Technology, Chinese Academy of Sciences and other institutions jointly released a hundred-page paper to systematically explain the post-ChatGPT technology chain
Technology peripherals
AI
What else can NLP do? Beihang University, ETH, Hong Kong University of Science and Technology, Chinese Academy of Sciences and other institutions jointly released a hundred-page paper to systematically explain the post-ChatGPT technology chain
What else can NLP do? Beihang University, ETH, Hong Kong University of Science and Technology, Chinese Academy of Sciences and other institutions jointly released a hundred-page paper to systematically explain the post-ChatGPT technology chain

Everything starts with the birth of ChatGPT...
The once peaceful NLP community was frightened by this sudden "monster" arrive! Overnight, the entire NLP circle has undergone tremendous changes. The industry has quickly followed suit, capital has surged, and the road to replicating ChatGPT has begun; the academic community has suddenly fallen into a state of confusion... Everyone slowly I started to believe that "NLP is solved!"
# However, judging from the NLP academic circle that is still active recently and the endless excellent work that is emerging, this is not the case, and it can even be Say "NLP just got real!"
In the past few months, Beihang University, Mila, Hong Kong University of Science and Technology, ETH Zurich (ETH), University of Waterloo, Dartmouth College, After systematic and comprehensive research, many institutions such as the University of Sheffield and the Chinese Academy of Sciences produced a 110-page paper, which systematically elaborated on the technology chain in the post-ChatGPT era: interaction.

- ##Paper Address : https://arxiv.org/abs/2305.13246
- Project resources: https://github.com/InteractiveNLP-Team
Different from traditional types of interactions such as "Human in the Loop (HITL)" and "Writing Assistant", the interaction discussed in this article has a higher and more comprehensive perspective:
- To the industry: If large models have difficult-to-solve problems such as factuality and timeliness, can ChatGPT X solve them? Even like ChatGPT Plugins, let it interact with tools to help us book tickets, order meals, and draw pictures in one step! In other words, we can alleviate some of the limitations of current large models through some systematic technical frameworks.
- To academia: What is real AGI? In fact, as early as 2020, Yoshua Bengio, the three giants of deep learning and winner of the Turing Award, described the blueprint of an interactive language model [1]: a language model that can interact with the environment and even socially interact with other agents. Only in this way can we have the most comprehensive semantic representation of language. To a certain extent, interaction with the environment and people creates human intelligence.
Therefore, allowing language models (LM) to interact with external entities and themselves can not only help bridge the inherent shortcomings of large models, but may also be the ultimate path to AGI. Ideal for an important milestone!
What is interaction?In fact, the concept of “interaction” is not imagined by the authors. Since the advent of ChatGPT, many papers have been published on new issues in the NLP world, such as:
- Tool Learning with Foundation Models explains how language models can use tools to reason or perform real-world operations [2];
- Foundation Models for Decision Making: Problems , Methods, and Opportunities explains how to use language models to perform decision making [3];
- ChatGPT for Robotics: Design Principles and Model Abilities explains how to use ChatGPT empowerment Robot [4];
- Augmented Language Models: a Survey explains how to use chain of thought (Chain of Thought), tool use (Tool-use) and other enhanced language models, and points out Language models use tools that can have actual impact on the external world (i.e. act) [5];
- Sparks of Artificial General Intelligence: Early experiments with GPT-4 explains how to use GPT- 4 Perform various types of tasks, including cases of interaction with people, environments, tools, etc. [6].
It can be seen that the focus of the NLP academic community has gradually transitioned from "how to build a model" to "how to build a framework", that is, incorporating more entities into the language model During the process of training and inference. The most typical example is the well-known Reinforcement Learning from Human Feedback (RLHF). The basic principle is to let the language model learn from the interaction with humans (feedback) [7]. This idea has become the finishing touch of ChatGPT.
Therefore, it can be said that the feature of “interaction” is one of the most mainstream technical development paths for NLP after ChatGPT! The authors' paper defines and systematically deconstructs "interactive NLP" for the first time, and mainly based on the dimension of interactive objects, discusses the advantages and disadvantages of various technical solutions and application considerations as comprehensively as possible, including:

- LM interacts with humans to better understand and meet user needs, personalize responses, and align with human values ), and improve the overall user experience;
- LM interacts with the knowledge base to enrich factual knowledge expressed in language, enhance the knowledge background relevance of responses, and dynamically utilize external information to generate more accurate Response;
- LM interacts with models and tools to effectively decompose and solve complex reasoning tasks, utilize specific knowledge to handle specific subtasks, and promote the emergence of social behaviors of agents;
- LM interacts with the environment to learn language grounding and effectively handles embodied tasks related to environmental observation such as reasoning, planning and decision-making. .
Therefore, in the interactive framework, the language model is no longer the language model itself, but a model that can be "observed" and "acted" , language-based agents that can "get feedback".
Interacting with an object, the authors call it "XXX-in-the-loop", indicating that this object participates in the process of language model training or inference, and is based on A form of cascade, loop, feedback, or iteration is involved.
Interacting with people

##Let the language model interact with people Interaction can be broken down into three ways:
- Use prompts to communicate
- Use feedback to learn
- Adjust using configuration
In addition, in order to ensure scalable deployment, models or programs are often used to simulate human behavior or preferences, that is, simulated from humans middle school study.
In general, the core problem to be solved in human interaction is alignment, that is, how to make the response of the language model more in line with the needs of the user and more helpful. It is harmless and well-founded, allowing users to have a better user experience.
"Use Prompts to Communicate" mainly focuses on the real-time and continuous nature of interaction, that is, it emphasizes the continuous nature of multiple rounds of dialogue. This is consistent with the idea of Conversational AI [8]. That is, through multiple rounds of dialogue, let the user continue to ask questions, so that the response of the language model slowly aligns with the user's preference during the dialogue. This approach usually does not require adjustment of model parameters during the interaction.
"Learning using feedback" is the main way of alignment currently, which is to allow users to give feedback to the language model's response. This feedback can be "good/bad" that describes preferences. ” annotation can also be more detailed feedback in the form of natural language. The model needs to be trained to make these feedbacks as high as possible. A typical example is RLHF [7] used by InstructGPT. It first uses user-labeled preference feedback data for model responses to train a reward model, and then uses this reward model to train a language model with a certain RL algorithm to maximize the reward (as shown below) ).
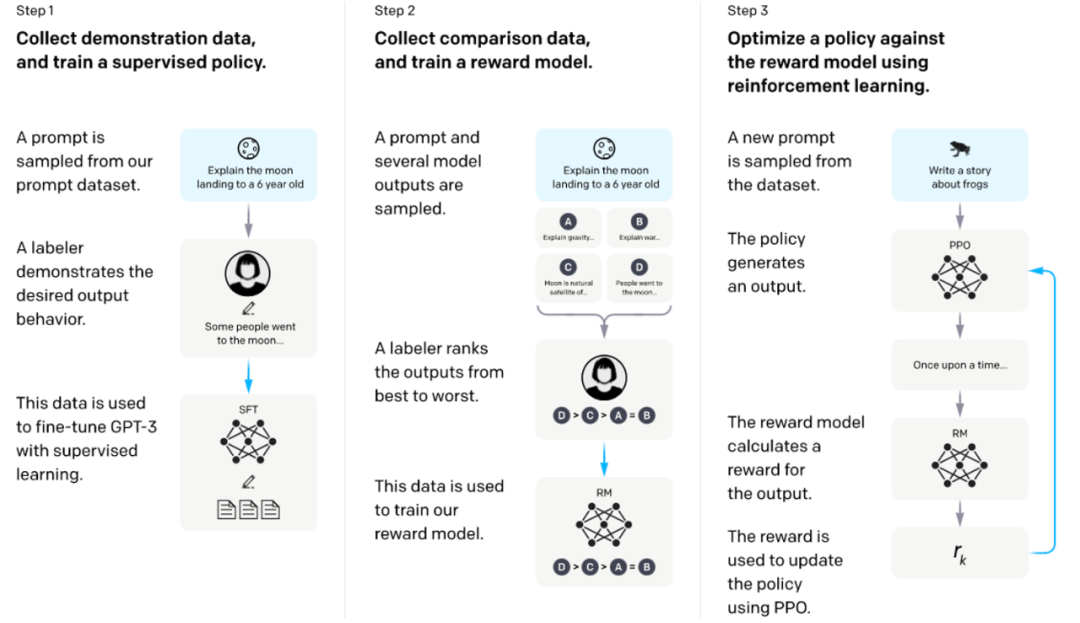
##Training language models to follow instructions with human feedback [7]
"Use configuration to adjust" is a special interaction method that allows users to directly adjust the hyperparameters of the language model (such as temperature), or the cascade mode of the language model, etc. A typical example is Google's AI Chains [9]. Language models with different preset prompts are connected to each other to form a reasoning chain for processing streamlined tasks. Users can drag and drop through a UI to adjust the node connection method of this chain. .
"Learning from human simulation" can promote large-scale deployment of the above three methods, because especially in the training process, using real users is unrealistic. For example, RLHF usually needs to use a reward model to simulate user preferences. Another example is Microsoft Research's ITG [10], which uses an oracle model to simulate user editing behavior.
Recently, Stanford Professor Percy Liang and others constructed a very systematic evaluation scheme for Human-LM interaction: Evaluating Human-Language Model Interaction [11], interested readers can Refer to this paper or the original text.
Interacting with the knowledge base
- Determine the source of supplementary knowledge: Knowledge Source
- Retrieve knowledge: Knowledge Retrieval
- Use knowledge to enhance: Please refer to the Interaction Message Fusion section of this paper for details, and I will not introduce it here.
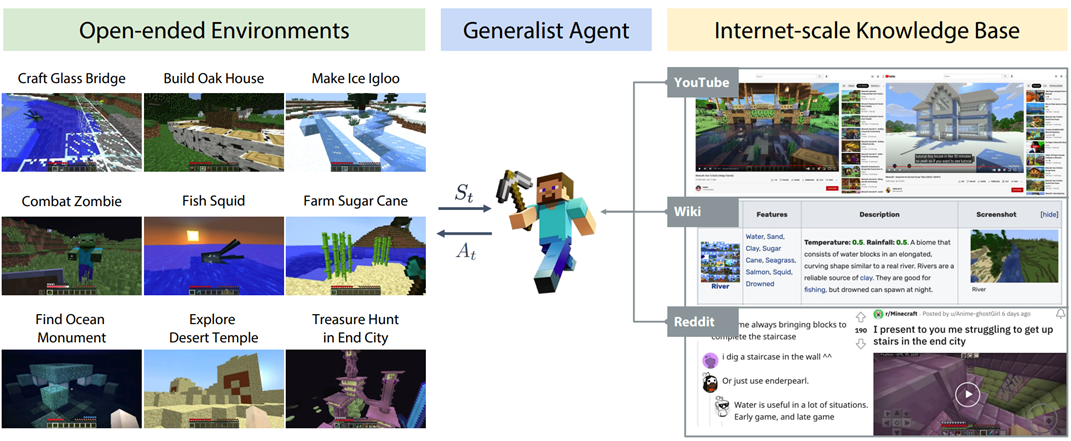
##MineDojo [16]: When a language model agent encounters a task that it does not know, it can learn from the knowledge base Find study materials, and then complete this task with the help of the materials. "Knowledge Source" is divided into two types, one is closed corpus knowledge (Corpus Knowledge), such as WikiText, etc. [15]; the other is Open network knowledge (Internet Knowledge), such as the knowledge that can be obtained using search engines [14].
"Knowledge Retrieval" is divided into four methods:
- Language-based sparse representation and lexical matching sparse retrieval (sparse retrieval): such as n-gram matching, BM25, etc.
- Dense retrieval (dense retrieval) based on language-based dense representation and semantic matching: such as using a single-tower or twin-tower model as a retriever, etc.
- Based on generative search: It is a relatively new method. The representative work is Google Tay Yi et al.’s Differentiable Search Index [12], which saves knowledge in the parameters of the language model. , after giving a query, directly output the doc id or doc content of the corresponding knowledge. Because the language model is the knowledge base [13]!
- Based on reinforcement learning: It is also a relatively cutting-edge method. Representative work such as OpenAI's WebGPT [14] uses human feedback to train the model to retrieve correct knowledge.
Interacting with models or tools

##Language models interact with models or tools, mainly The purpose is to decompose complex tasks, such as decomposing complex reasoning tasks into several sub-tasks, which is also the core idea of Chain of Thought [17]. Different subtasks can be solved using models or tools with different capabilities. For example, computing tasks can be solved using calculators, and retrieval tasks can be solved using retrieval models. Therefore, this type of interaction can not only improve the reasoning, planning, and decision making capabilities of the language model, but also alleviate the limitations of the language model such as "hallucination" and inaccurate output. In particular, when a tool is used to perform a specific sub-task, it may have a certain impact on the external world, such as using the WeChat API to post a circle of friends, etc., which is called "Tool-Oriented Learning" [ 2].
In addition, sometimes it is difficult to explicitly decompose a complex task. In this case, different roles or skills can be assigned to different language models, and then Let these language models implicitly and automatically form a division of labor during the process of mutual collaboration and communication to decompose tasks. This type of interaction can not only simplify the solution process of complex tasks, but also simulate human society and construct some form of intelligent agent society.
The authors put models and tools together, mainly because models and tools are not necessarily two separate categories. For example, a search engine tool and a retriever model are not essential. different. This essence is defined by the authors using "after task decomposition, what kind of subtasks are undertaken by what kind of objects".
When a language model interacts with a model or tool, there are three types of operations:
- Thinking: The model interacts with itself , perform task decomposition and reasoning;
- Acting: The model calls other models, or external tools, etc., to help with reasoning, or to have actual effects on the external world;
- Collaborating: Multiple language model agents communicate and collaborate with each other to complete specific tasks or simulate human social behavior.
Note: Thinking mainly talks about the "Multi-Stage Chain-of-Thought", that is: different reasoning steps, corresponding to language Different calls to the model (multiple model run), instead of running the model once and outputting thought answer at the same time (single model run) like Vanilla CoT [17].
Part of what is inherited here is formulation of ReAct [18].
Typical thinking work includes ReAct [18], Least-to-Most Prompting [19], Self-Ask [20], etc. For example, Least-to-Most Prompting [19] first decomposes a complex problem into several simple module sub-problems, and then iteratively calls the language model to solve them one by one.
Typical work on Acting includes ReAct [18], HuggingGPT [21], Toolformer [22], etc. For example, Toolformer [22] processes the pre-training corpus of the language model into a form with tool-use prompt. Therefore, the trained language model can automatically call the correct language at the correct time when generating text. External tools (such as search engines, translation tools, time tools, calculators, etc.) solve specific sub-problems.
Collaborating mainly includes:
- Closed-loop interaction: such as Socratic Models [23], etc., through large language models, visual language models , closed-loop interaction of audio language models to complete certain complex QA tasks specific to the visual environment.
- Theory of Mind: Aims to enable one agent to understand and predict the state of another agent to promote efficient interaction with each other. For example, the Outstanding Paper of EMNLP 2021, MindCraft [24], gives two different language models different but complementary skills, allowing them to collaborate to complete specific tasks in the MineCraft world during the communication process. The famous professor Graham Neubig has also paid great attention to this research direction recently, such as [25].
- Communicative Agents (Communicative Agents): Aimed at allowing multiple agents to communicate and collaborate with each other . The most typical example is Generative Agents [26] of Stanford University that recently shocked the world: building a sandbox environment and allowing many intelligent agents injected with "souls" from large models to move freely in it, they can spontaneously present some human-like behaviors. The social behaviors, such as chatting and saying hello, have a "Western World" flavor (as shown below). In addition, the more famous work is the new work CAMEL [27] by the author of DeepGCN, which allows two agents empowered by large models to develop games and even stock stocks in the process of communicating with each other without requiring too much human intervention. intervention. The author clearly puts forward the concept of "Large Model Society" (LLM Society) in the article.
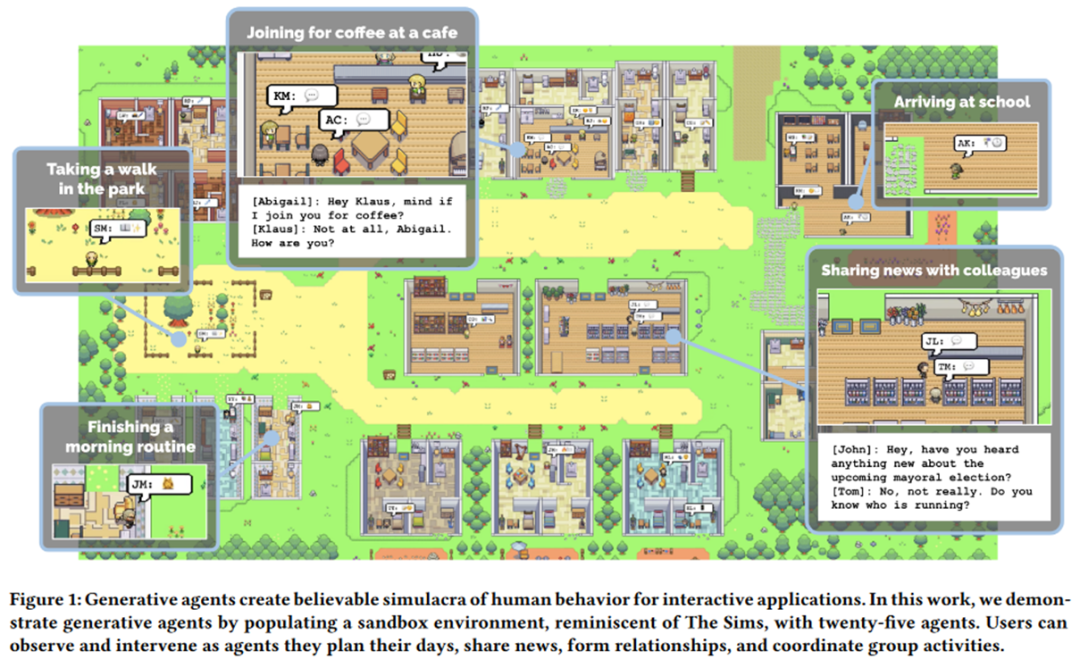
##Generative Agents: Interactive Simulacra of Human Behavior, https://arxiv.org/pdf/2304.03442 .pdf
Interacting with the environment
The language model and the environment belong to two two different quadrants: the language model is built on abstract text symbols and is good at high-level reasoning, planning, decision-making and other tasks; while the environment is built on specific sensory signals (such as visual information, auditory information, etc.), and simulation Or some low-level tasks may occur naturally, such as providing observation, feedback, state transition, etc. (for example: an apple falls to the ground in the real world, and a "creeper" appears in the simulation engine. in front of you).
Therefore, to enable the language model to effectively and efficiently interact with the environment, it mainly includes two aspects of effort:
- Modality Grounding: Allows the language model to process multi-modal information such as images and audio;
- Affordance Grounding: Allows the language model to handle possible and appropriate information at the scale of the specific scene of the environment The object performs possible and appropriate actions.
#The most typical one for Modality Grounding is the visual-language model. Generally speaking, it can be carried out using a single tower model such as OFA [28], a two-tower model such as BridgeTower [29], or the interaction of language model and visual model such as BLIP-2 [30]. No more details will be said here, readers can refer to this paper for details.
There are two main considerations for Affordance Grounding, namely: how to perform (1) scene-scale perception (scene-scale perception) under the conditions of a given task, and (2) possible action. for example:

For example, in the scene above, the given task "Please turn off the lights in the living room" and "Perception of scene scale" require us to find all the lights with red frames, instead of selecting the green ones that are not in the living room but in the kitchen. For the circled lights, "possible actions" require us to determine the feasible ways to turn off the light. For example, pulling a cord light requires a "pull" action, and turning the light on and off requires a "toggle switch" action.
Generally speaking, Affordance Grounding can be solved using a value function that depends on the environment, such as SayCan [31], etc., or a specialized grounding model such as Grounded Decoding [32] wait. It can even be solved by interacting with people, models, tools, etc. (as shown below).
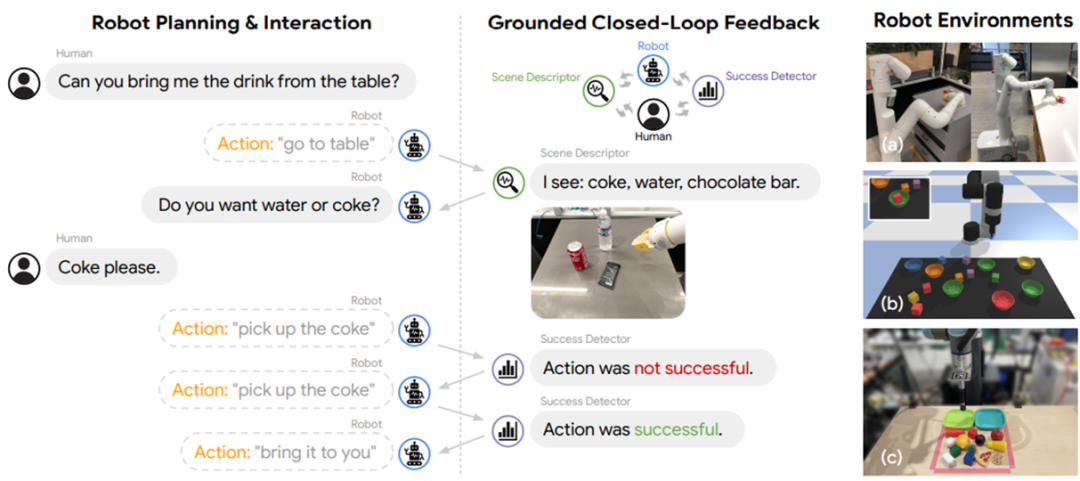
Inner Monologue [33]
What to use for interaction :Interaction Interface
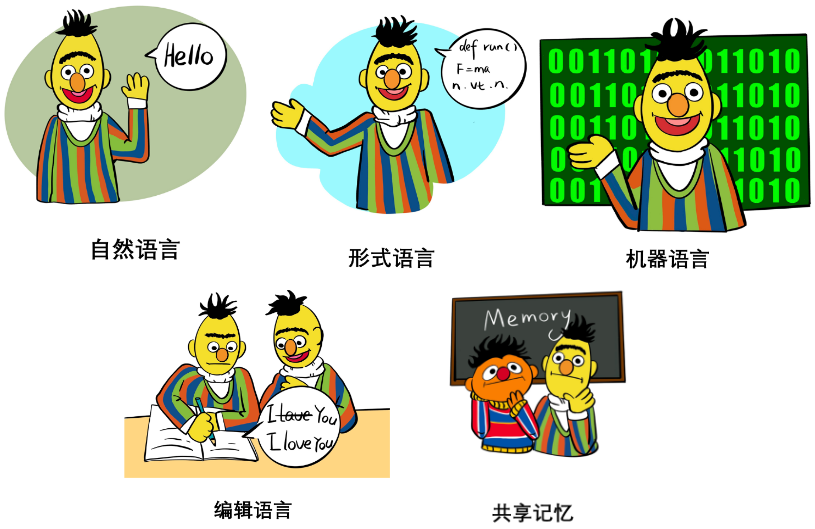
In the Interaction Interface chapter of the paper, the authors systematically discussed the usage, advantages and disadvantages of different interaction languages and interaction media , including:
- Natural language: such as few-shot example, task instruction, role assignment and even structured natural language, etc. Its characteristics and functions in generalization and expressivity are mainly discussed.
- Formal language: such as code, grammar, mathematical formulas, etc. Its characteristics and functions in parsability and reasoning ability are mainly discussed.
- Machine language: such as soft prompts, discretized visual tokens, etc. Its characteristics and functions in generalization, information bottleneck theory, interaction efficiency, etc. are mainly discussed.
- Editing: mainly includes operations such as deleting, inserting, replacing, and retaining text. Its principles, history, advantages, and current limitations are discussed.
- Shared memory: mainly includes hard memory and soft memory. The former records the historical status in a log as a memory, and the latter uses a readable and writable memory external module to save it. Tensor. The paper discusses the characteristics, functions and limitations of the two.
How to interact: interaction methods
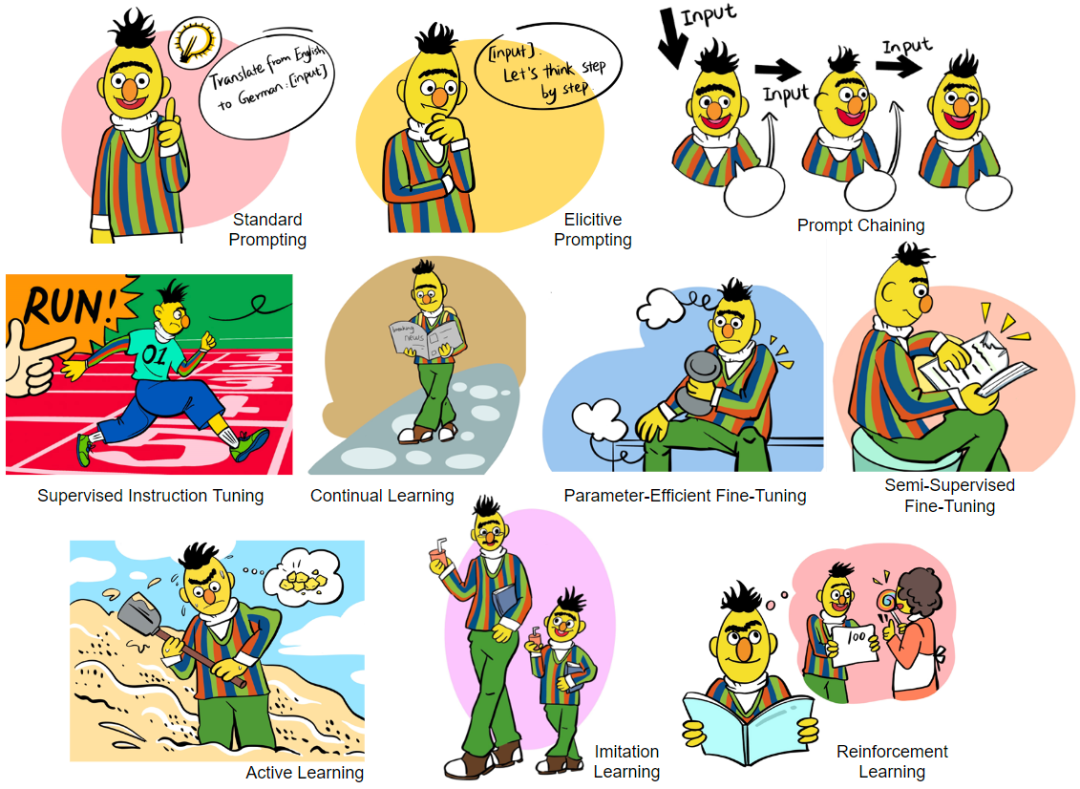
The paper also discusses it comprehensively, in detail and systematically A variety of interaction methods, including:
- Prompting: Without adjusting model parameters, the language model is only called through prompt engineering, covering In-Context Learning, Chain of Thought, and tool usage tips ( Tool-use), cascade reasoning chaining (Prompt Chaining) and other methods, the principles, functions, various tricks and limitations of various prompting techniques are discussed in detail, such as considerations of controllability and robustness, etc. .
- Fine-Tuning: Adjust model parameters to allow the model to learn and update from interactive information. This section covers methods such as Supervised Instruction Tuning, Parameter-Efficient Fine-Tuning, Continual Learning, and Semi-Supervised Fine-Tuning. The principles, functions, advantages, considerations in specific use, and limitations of these methods are discussed in detail. It also includes part of Knowledge Editing (ie, editing knowledge inside the model).
- Active Learning: Interactive active learning algorithm framework.
- Reinforcement Learning: Interactive reinforcement learning algorithm framework, discusses online reinforcement learning framework, offline reinforcement learning framework, learning from human feedback (RLHF), learning from environmental feedback ( RLEF), learning from AI feedback (RLAIF) and other methods.
- Imitation Learning: An interactive imitation learning algorithm framework that discusses online imitation learning, offline imitation learning, etc.
- Interaction Message Fusion: Provides a unified framework for all the above interaction methods. At the same time, within this framework, it expands outward and discusses different knowledge and information fusion solutions, such as cross- Attention fusion scheme (cross-attention), constrained decoding fusion scheme (constrained decoding), etc.
Other discussions
Due to space limitations, this article does not detail discussions on other aspects, such as evaluation, application, ethics, security, and future development directions. However, these contents still occupy 15 pages in the original text of the paper, so readers are recommended to view more details in the original text. The following is an outline of these contents:
Evaluation of interaction
The discussion of evaluation in the paper mainly involves the following keywords:
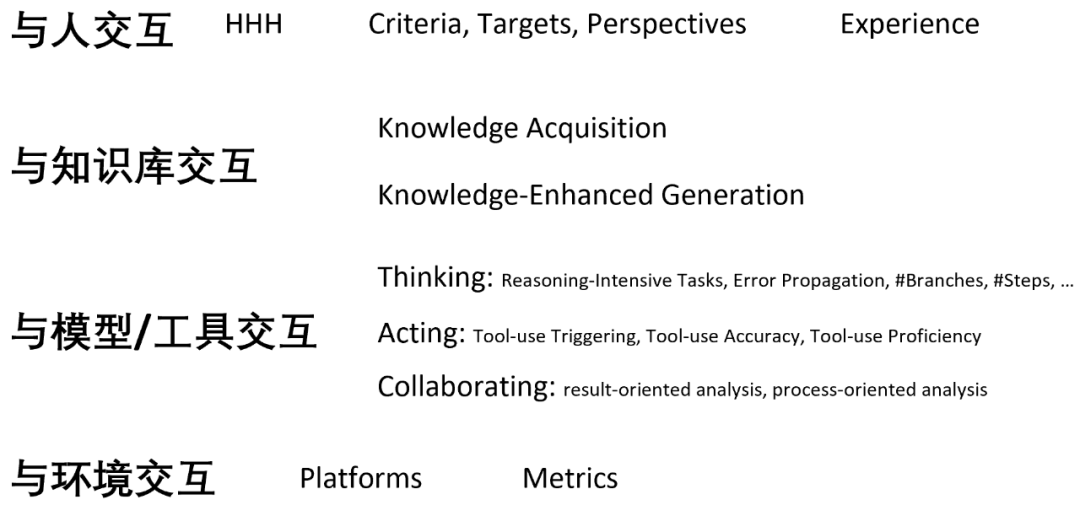
Main applications of interactive NLP
- ##Controllable Text Generation
- Interaction with people: RLHF’s ideological stamping phenomenon, etc.
- Interaction with knowledge: Knowledge-Aware Fine-Tuning [34] etc.
- Interacting with models and tools: Classifier-Guided CTG etc.
- Interacting with the environment: affordance grounding etc
- Interactive Writing Assistant(Writing Assistant)
- Content Support: Content support type
- Content Checking and Polishing:Content checking and polishing type
- Content Enrichment:Content enrichment type
- Content Co-creation:Content creation type
- ##Embodied AI
- Observation and Manipulation: Basics
- Navigation and Exploration: Advanced (e.g., long-horizon embodied tasks)
- Multi-Role Tasks: Advanced
Ethics and Safety The impact of interactive language models on education was discussed, as well as ethical and safety issues such as social bias and privacy. Future development direction and challenges
The above is the detailed content of What else can NLP do? Beihang University, ETH, Hong Kong University of Science and Technology, Chinese Academy of Sciences and other institutions jointly released a hundred-page paper to systematically explain the post-ChatGPT technology chain. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
