

AI, artificial intelligence, this thing is actually not new at all.
From the science fiction works in the early years to the gradual implementation later, from the IBM supercomputer "Deep Blue" defeating the chess master Kasparov in 1997 to Google AlphaGo defeating the Go champion Lee Sedol in 2016, AI has always been there Progress is always evolving.
However, due to various limitations in computing power algorithms, technical capabilities, application scenarios, etc., AI has always felt like a castle in the air.
It wasn’t until the emergence of ChatGPT that AI truly ignited the enthusiasm of ordinary people. We discovered that AI is so powerful and so easily available, making many individuals and companies excited and crazy about it.

As we all know, sufficiently powerful and reasonable hardware and algorithms are the two cornerstones for realizing efficient and practical AI. In this AI boom, NVIDIA is proud of its many years of experience in the field of high-performance computing. The future layout and deep cultivation are very suitable for ultra-large-scale cloud AI development.
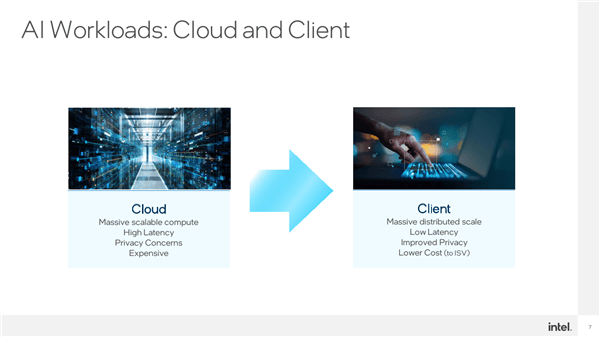
Of course, AI is diverse in both implementation methods and application scenarios, both on the cloud side and on the device side.
NVIDIA’s focus is on cloud-side and generative AI, Intel is attacking both cloud-side generative and device-side judgment. As more and more AI runs on the device, it is closer to the daily life of ordinary users. The improvements brought about by experience are becoming more and more obvious, and Intel has a lot to do.
Device-side AI has several outstanding features:
First, the user base is huge and the application scenarios are becoming more and more extensive;
Second, the latency is very low. After all, there is no need to rely on the network to transmit instructions and data to the cloud for processing and then return;
The third is privacy and security. You don’t have to worry about personal information, business secrets, etc. being leaked after being uploaded;
Fourth, the cost is lower. It does not require large-scale servers and calculations, and can be completed with only local equipment.
On-device AI may sound strange to you, but in fact, background blur, visual beautification, sound beautification (audio noise reduction), video noise reduction, image segmentation, etc. that people are accustomed to, are all It is a typical application scenario of end-side AI, and AI is working hard behind the scenes.
To achieve better results, these applications require more complete and complex network models, and the demand for computing power is naturally growing rapidly.
For example, noise suppression requires 50 times more computing power than two years ago, and background segmentation has also increased by more than 10 times.
Not to mention that after the emergence of generative AI models, the demand for computing power has increased by leaps and bounds, directly increasing by orders of magnitude. Whether it is Stable Diffusion or language-based GTP, the model parameters are very exaggerated.
For example, the number of parameters of GPT3 has reached about 175 billion, which is almost 500 times more than that of GPT2. GPT4 is estimated to reach the trillion level.
These all put forward more stringent requirements for hardware and algorithms.

Intel has naturally begun to pay attention to and invest in AI for a long time. Whether it is server-level Xeon or consumer-level Core, they are participating in AI in various ways. The term "XX generation intelligent Core processor" is very popular. Largely due to AI.
Prior to this, Intel AI solutions mainly accelerated at the architecture and instruction set levels of CPU and GPU.
For example, the DL Boost based on deep learning added from the 10th generation Core and the 2nd generation scalable to strong, including VNNI vector neural network instructions, BF16/INT8 acceleration, etc.

Gaussian network accelerator GNA 2.0 added to the 11th generation Core is equivalent to the role of NPU. It only consumes very low resources and can efficiently perform neural inference calculations.
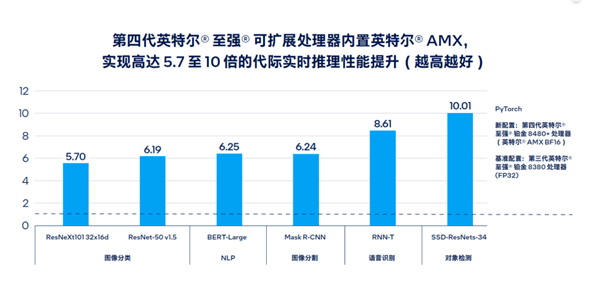
For example, the fourth-generation scalableAMX Advanced Matrix Extension codenamed Sapphire Rapids has improved AI real-time reasoning and training performance by up to 10 times, and the processing speed of large language models has been improved by enough 20 times, and the supporting software and tool development are also more complete and rich.
no single hardware architecture is suitable for all AI scenarios. Different hardware has its own characteristics, some have powerful computing power, some have ultra-low latency, some are all-round, and some have Specialize.
As an infrastructure, AI also has various scenario applications and requirements, with different loads and delays. For example, real-time voice and image processing do not require too much computing power, but are very sensitive to delays. sensitive.
At this time, Intel's XPU strategy has quite targeted special advantages. The CPU is suitable for delay-sensitive lightweight AI processing, and the GPU is suitable for heavy-load, highly parallel AI applications.Another unparalleled advantage of Intel is its stable and huge x86 ecosystem, which has a broad mass base regardless of application or development.
Now, Intel has VPU again.

Meteor Lake, which will be released later this year, will integrate an independent VPU unit for the first time, and it will be standard on all models, which can perform specific AI operations more efficiently.
The technical source of the Intel VPU unit comes from the AI start-up Movidius acquired by Intel in 2017. The VPU architecture designed by it is revolutionary. It only requires 1.5W power consumption to achieve a powerful computing power of 4TOPS. The energy efficiency ratio is simply incredible. , was first used for drone obstacle avoidance, etc., and now it has entered the processor, working in conjunction with the CPU and GPU.
VPU is essentially a new architecture designed for AI. It can efficiently perform some matrix operations and is especially good at sparse processing. Its ultra-low power consumption and ultra-high energy efficiency are very suitable for some applications that require long-term Scenarios that are opened and executed, such as background blur and removal for video conferencing, and gesture control for streaming media.
The reason why Intel needs to build a VPU when it already has a CPU and GPU is that many end-side applications are now carried out on notebooks, which are very sensitive to battery life. High-energy-efficiency VPUs are used in mobile applications. Just right.
Another factor is that CPU and GPU, as general computing platforms, have heavy tasks themselves. If a large amount of AI load is added to them, the execution efficiency will be greatly reduced.


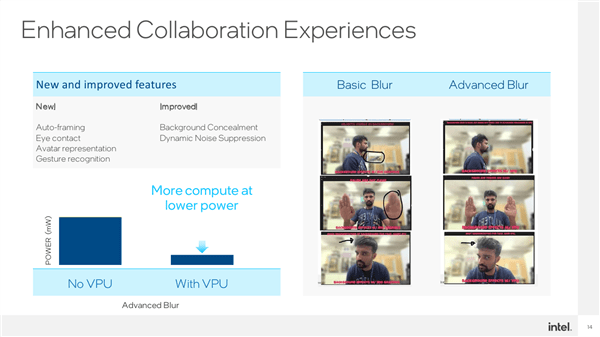
Specific to application scenarios, VPU is also very extensive, such as video conferencing. Current CPU AI can already implement automatic framing (Auto-Framing), eye tracking, virtual avatars/portraits, gesture recognition, etc.
After adding a VPU with low power consumption and high computing power, it can also strengthen background blurring, dynamic noise reduction and other processing to make the effect more accurate. For example, objects in the background will be blurred if they should be blurred, and human hands/hair will be blurred. Wait until something that shouldn't be blurry is no longer blurry.
With efficient hardware and suitable scenarios, equally efficient software is needed to release its full strength and achieve the best results. This is really not a problem for Intel, which has tens of thousands of software developers.
Meteor Lake has not yet been officially released. Intel has cooperated with many ecological partners on VPU adaptation, and independent software developers are also very active.
For example, Adobe, many filters, automated processing, intelligent cutouts, etc., can be run on VPU.
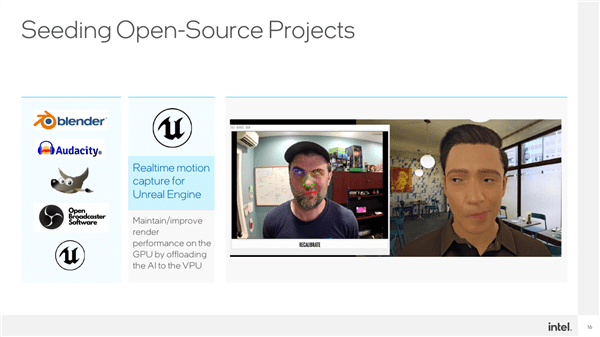
For example, Unreal Engine’s digital people, such as virtual anchors, and VPU can capture and render in real time very well.
Blender, Audacity, OBS, GIMP...the list can be drawn out for a long time, and it is still growing.

More importantly, CPU, GPU, and VPU do not do their own thing, but can be combined to give full play to their respective advantages to achieve the best AI experience.
For example, there is a plug-in based on Stable Diffusion in GIMP, which can greatly lower the threshold for ordinary users to use generative AI. It can fully mobilize the acceleration capabilities of CPU, GPU, and VPU, and disperse the entire model to different On top of IP, they cooperate with each other to obtain the best performance.
Among them, the VPU can host the VNET module to run, and the GPU is used to execute the encoder module. Through such cooperation, it only takes about 20 seconds to generate a complex picture.
Among them, the power consumption of VPU is the lowest, followed by CPU, and GPU is the highest.

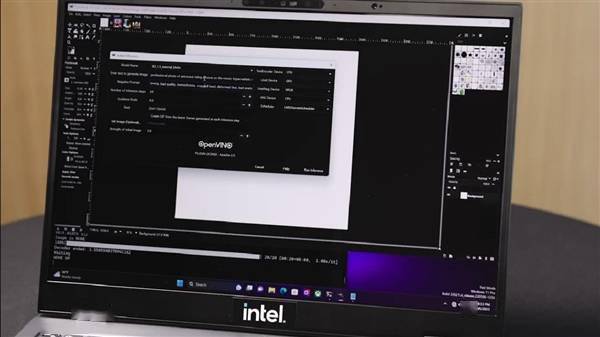
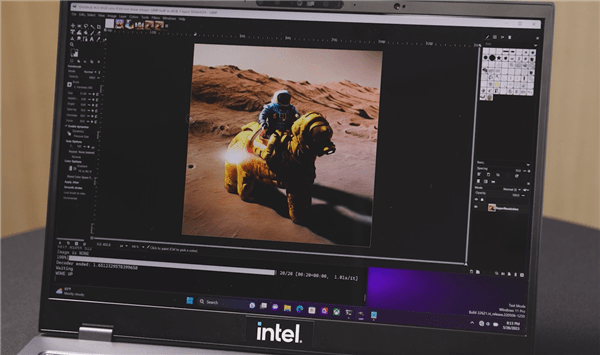
Intel has fully realized the importance of AI in enhancing PC experience. In order to meet this challenge, Intel is making every effort to promote the development and popularization of AI on both the hardware and software levels, laying a solid foundation for the development and popularization of AI on the device side.
At the hardware level, CPU, GPU, and VPU will form a ubiquitous underlying platform; at the software level, various standardized development software such as OpenVINO will greatly promote the exploration of application scenarios.
In the future, thin and light notebooks equipped with the Meteor Lake platform can easily run large models such as Stable Diffusion to realize Vincentian graphs, which greatly reduces the application threshold of AI. Both judgmental AI and generative AI can be executed efficiently. Ultimately realizing true AI everywhere.

The above is the detailed content of Let AI be everywhere! Intel launches new VPU: ultra-high energy efficiency crushes GPU. For more information, please follow other related articles on the PHP Chinese website!
 attributeusage
attributeusage
 Website domain name valuation tool
Website domain name valuation tool
 What are the cloud servers?
What are the cloud servers?
 How to solve the problem of missing steam_api.dll
How to solve the problem of missing steam_api.dll
 Ethereum browser query digital currency
Ethereum browser query digital currency
 The main components that make up the CPU
The main components that make up the CPU
 What are the java file transfer methods?
What are the java file transfer methods?
 How to set the computer to automatically connect to WiFi
How to set the computer to automatically connect to WiFi
 Is Bitcoin trading allowed in China?
Is Bitcoin trading allowed in China?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



